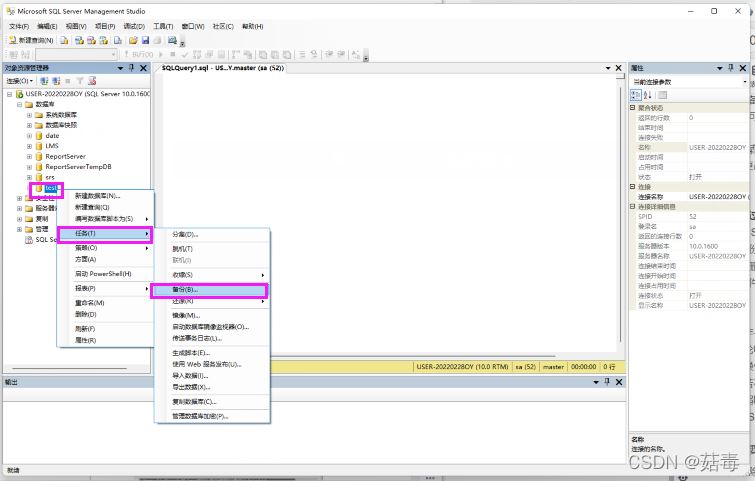
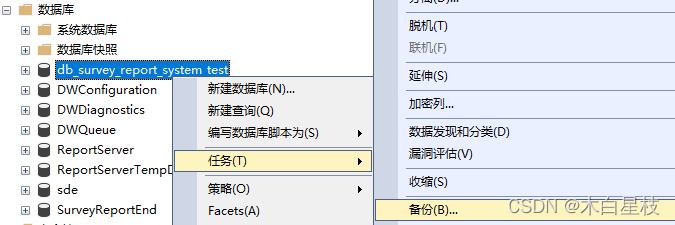
在没学习开窗函数之前,我们都知道,用了分组之后,查询字段就只能是分组字段和聚合的字段,这带来了极大的不方便,有时我们查询时需要分组,又需要查询不分组的字段,每次都要又到子查询,这样显得sql语句复杂难懂,给维护代码的人带来很大的痛苦,然而开窗
|
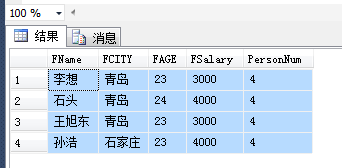
在没学习开窗函数之前,我们都知道,用了分组之后,查询字段就只能是分组字段和聚合的字段,这带来了极大的不方便,有时我们查询时需要分组,又需要查询不分组的字段,每次都要又到子查询,这样显得sql语句复杂难懂,给维护代码的人带来很大的痛苦,然而开窗函数出现了,曙光也来临了。如果要想更具体了解开窗函数,请看书《程序员的SQL金典》,开窗函数在mysql不能使用。 开窗函数与聚合函数一样,都是对行的集合组进行聚合计算。它用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用group by语句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。定义看不懂不要紧,会用就行。 举个简单例子 查询每个工资小于5000的员工信息(姓名,城市 年龄 薪水),并且显示小于5000的员工个数,尝试使用下面语句:
消息 8120,级别 16,状态 1,第 1 行 可以使用子查询实现,语句:
结果:
使用开窗函数实现,查询结果一模一样,就不粘贴了:
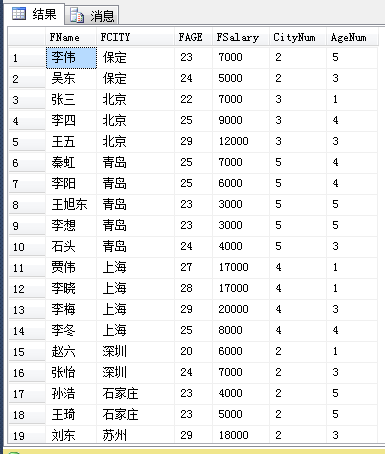
1.开窗函数格式:函数名(列) OVER(选项) 2.聚合开窗函数格式:聚合函数(列) OVER(PARTITION BY 字段) over关键字把聚合函数当成聚合开窗函数而不是聚合函数,SQL标准允许将所有的聚合函数用做聚合开窗函数。OVER关键字后的括号中还经常添加选项用以改变进行聚合运算的窗口范围。如果OVER关键字后的括号为空,则开窗函数会对结果集合的所有行进行聚合运算。 PARTITION BY来定义行的分区来进行聚合运算,与group by 不同,partition by 字句创建的分区是独立于结果集的,创建的分区只是用于进行聚合运算,而且不同的开窗函数所创建的分区不互相影响,例如:查询所有人员的信息,并查询所属城市的人员数以及同年龄的人员数:
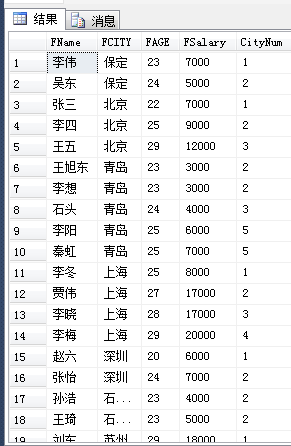
查询所有人员的信息,并查询所属城市的人员数,每个城市的人按照年龄排序语句:
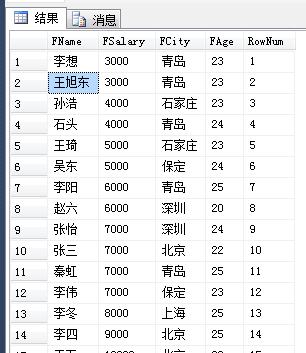
3.排序开窗函数格式:排序函数() OVER(ORDER BY 字段) (1)主要函数有ROW_NUMBER()、RANK()、DENSE_RANK()、NTILE() ROW_NUMBER() 加行号,一般可以用于分页查询(现在被offset fetch取代 ),对于没有主键列的表加行号作用很明显,删除重复数据等。 按照薪水高低给所有人员排序,同样薪水的排名不一样,可以用row_number(),
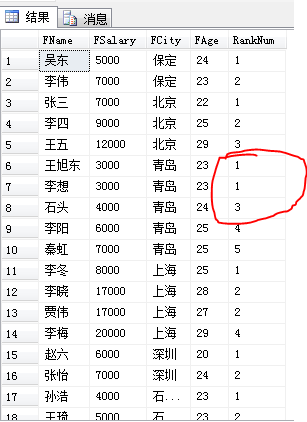
使用rank()将每个城市的薪水排行,值一样的同一个排名,出现两个第一名的时候,排在两个第一名后的排名将是第三名
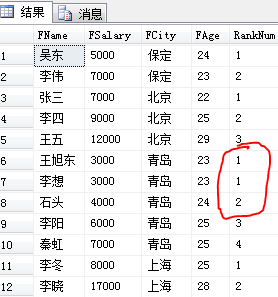
使用dense_rank()将每个城市的薪水排行,值一样的同一个排名,出现两个第一名的时候,排在两个第一名后的排名将是第三名
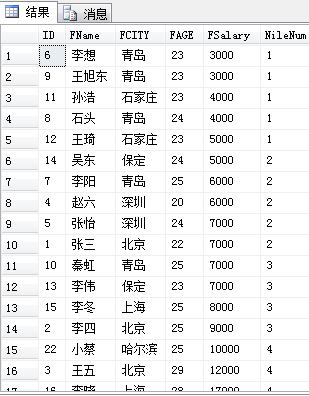
ntile(数字) over(order by 字段):数字表示一组多少个数,并根据数量得出分组的数量
|






2021-10-16
2022-09-14
2022-08-25
2022-03-01
2022-08-25