
SQL中的partition分区功能使用

需求来源 今天甲方这边要查看一个机车的周时数据(就是一个机车从到我的管辖范围内,到出我的管辖内所用的时间),那这个它会跑很多次,我们要查询这一天的周时数据,锚定一个点比如
需求来源今天甲方这边要查看一个机车的周时数据(就是一个机车从到我的管辖范围内,到出我的管辖内所用的时间),那这个它会跑很多次,我们要查询这一天的周时数据,锚定一个点比如出管辖区的时间,那么根据查询到今天所有这个时间范围内出去的车信息,然后去数据表里找这个机车进来的数据且时最新的一条就行了。 实现思路分两次查询的第一次查询出来所有的当天出管辖区的机车信息,第二个查询是根据第一个查询小小的改动,把时间范围去掉就好,然后根据机车信息进行组取时间每个机车时间最新的数据就好。直接使用group by,但是这个并不能取出其它的信息所以就pass掉了。GPTl了一下给的方案是使用partition这个功能。 实施就不看项目数据了就看一下我写的小demo的结果吧。我有一个student表,这个表里有10个班的学生,每个班的学生有20个,我现在要取出每个班的学生id最大的这个记录,就可以使用这个partition了。
解释一下这个啊。 这条 SQL 语句使用了窗口函数 ROW_NUMBER() 来为每个 classes_id 组中的行编号,并在外部查询中只选择每个 classes_id 组中的最新一行(根据 id 倒序排序)。以下是对这条 SQL 语句的详细解释: SQL 语句结构
内部查询(子查询)
SELECT *: 选择 student 表中的所有列。 ROW_NUMBER() OVER (PARTITION BY classes_id ORDER BY id DESC) AS rn:
这部分查询为每个 classes_id 组中的行编号,编号从1开始,按照 id 倒序排列。因此,rn 为1的行是每个 classes_id 组中 id 最大的行。 外部查询
FROM (...) a: 将内部查询的结果作为一个临时表 a。 WHERE rn = 1: 筛选出临时表 a 中 rn 等于 1 的行,即每个 classes_id 组中 id 最大的行。 结果 整个查询的作用是:
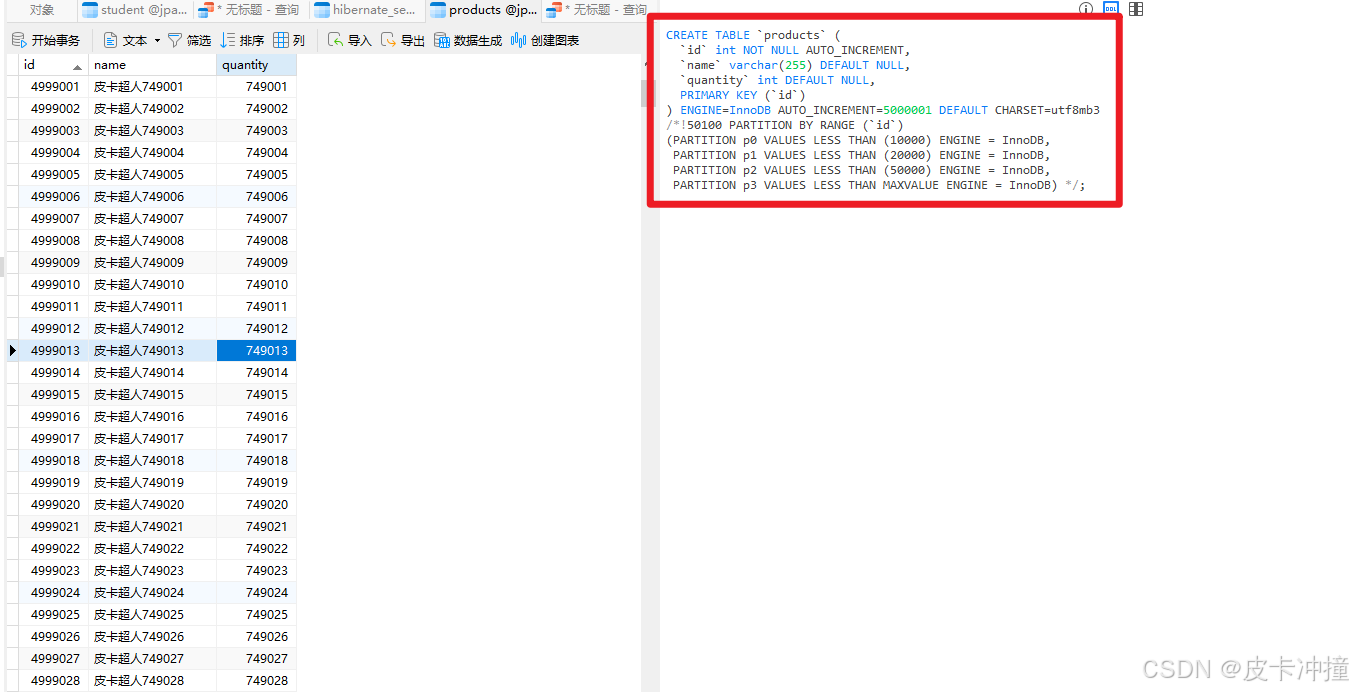
partition的升级使用partition不仅仅可以在日常查询中使用,还可以在表的数据结构上进行优化,比如在建表的时候创建分区或者后期添加分区,这个分区操作是在物理上的操作,可以看我下面这张表的结构,有一部分注释说明就是分区的设置,
对表进行分区可以提升查询性能和数据管理的效率。由于 ENGINE=MyISAM 不支持分区,我们需要将表的存储引擎更改为 InnoDB,因为 InnoDB 支持分区。 假设我们要根据 id 列进行范围分区,将数据划分为四个分区:
解释
这样,表 products 就被划分为四个分区,每个分区包含一定范围的 id 值的数据。 验证一下看看分区上面说了创建分区了,但是怎么才能确定我们的查询sql使用到了分区呢?使用explain来查看执行的sql有没有在分区的范围呢,
分区的一些操作创建分区后,数据库管理系统会自动处理分区的数据存储和检索,用户在日常操作中并不需要特殊处理分区。不过,你可以通过一些特定的查询和操作来利用分区的优势。以下是一些常见的用法示例: 1. 普通查询普通的查询不需要特别处理分区,数据库管理系统会自动根据分区优化查询:
2. 分区表上的查询优化当你的查询条件包含分区键时,数据库会自动选择相关的分区进行查询,从而提高查询性能。例如:
3. 插入数据插入数据时,数据库会根据分区键自动将数据插入到相应的分区:
4. 删除分区中的数据可以通过分区键删除特定分区中的数据:
5. 分区维护操作你可以进行一些特定的分区维护操作,例如合并分区、拆分分区、删除分区等: 添加新的分区
删除分区
重组分区 可以将多个分区合并为一个分区:
6. 检查分区信息你可以使用 SHOW 语句查看表的分区信息:
总结综合示例展示了如何创建分区表、插入数据以及进行查询和维护操作:
目前先整理这么多,以后有深入学习使用了再继续!!! |



您可能感兴趣的文章 :
- 怎么安装SQL Server 2016及SQL Server Management Studio安装配置
- SQL Server使用Windows身份验证与JDBC连接数据库的操作流程
- SQL Server使用T-SQL创建数据库的操作
- sql中的regexp与like区别实现介绍
- SQLServer日志收缩的两种方法
- Sql Server查询卡顿的排查方法
- sql server安装及使用全流程
- SQL Povit函数使用及实例
- Navicat连接SQL server出现:[IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数
- sql server实现图片的存入和读取的流程介绍

-
怎么安装SQL Server 2016及SQL Server Management Studio安装
一、安装SQL Server 2016 1.准备SQL Server 2016的安装包 SQL Server 2016可在官网上进行下载; 2.解压安装包 将下载的SQL Server2016的安装包解压,找到 -
SQL Server使用Windows身份验证与JDBC连接数据库的操
什么是 Windows 身份验证 Windows 身份验证(也称为集成安全性)是 SQL Server 提供的一种身份验证方式,它允许 SQL Server 使用 Windows 用户账户来 -
SQL Server使用T-SQL创建数据库的操作
功能和特性上: SQL server的管理工具(SQL Server Management Studio)功能强大,适合企业级应用。支持更多的数据类型,如 XML、JSON、地理空间数据 -
sql中的regexp与like区别实现介绍
1、REGEXP 用途:高级字符串匹配,使用正则表达式。 特点:灵活性强,能进行复杂模式匹配(如开头、结尾、字符集等)。 基本语法: 1 -
SQLServer日志收缩的两种方法
在日常运维中,有时会遇到The transaction log for database xxxx is full due to ACTIVE_TRANSACTION.这样的报错信息。 此错误消息表明:数据库的事务日志文 -

sql server安装及使用全流程
一、安装SQL Server 1.到微软官网下载SQL Server Developer版本,现在的最新版本是SQL Server 2019 Developer。微软官网传送门:点击此处直达 2.下载完成 -
![Navicat连接SQL server出现:[IM002] [Microsoft][ODBC 驱动](https://www.f11.cn/uploads/allimg/240703/222FK2V-0.png)
Navicat连接SQL server出现:[IM002] [Microsoft][ODBC 驱动
问题 解决方法 一 找到Navicat的安装路径,然后找到sqlncli_x64.msi文件并安装,安装成功后重启Navicat重新进行连接,看是否成功。 解决方法 二




-
SQL Server表分区删除介绍
2021-10-16
-
SQLServer或Oracle卸载不完全导致安装失
2024-05-08
-
SQL Server还原完整备份和差异备份的操
2022-09-14
-
安装sqlserver2022提示缺少msodbcsql.msi错误
2024-05-07
-
编写SQLMap的Tamper脚本过狗
2023-02-27

