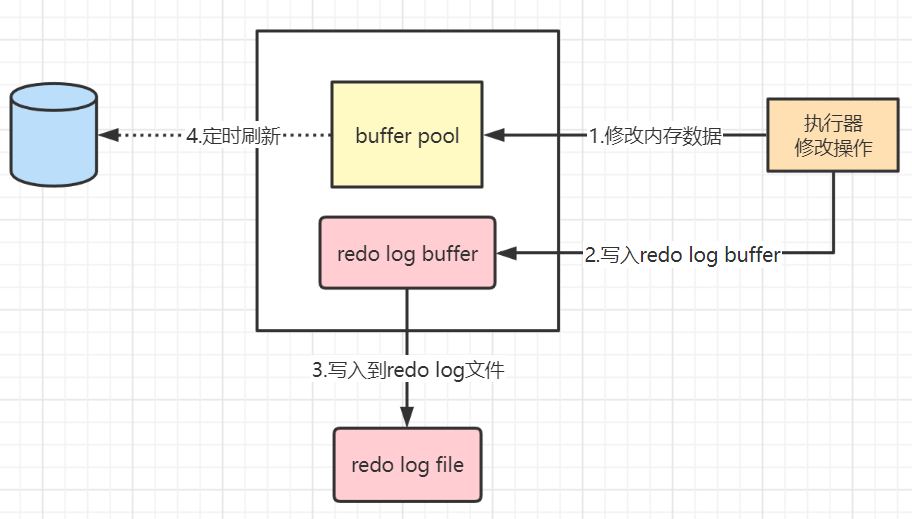
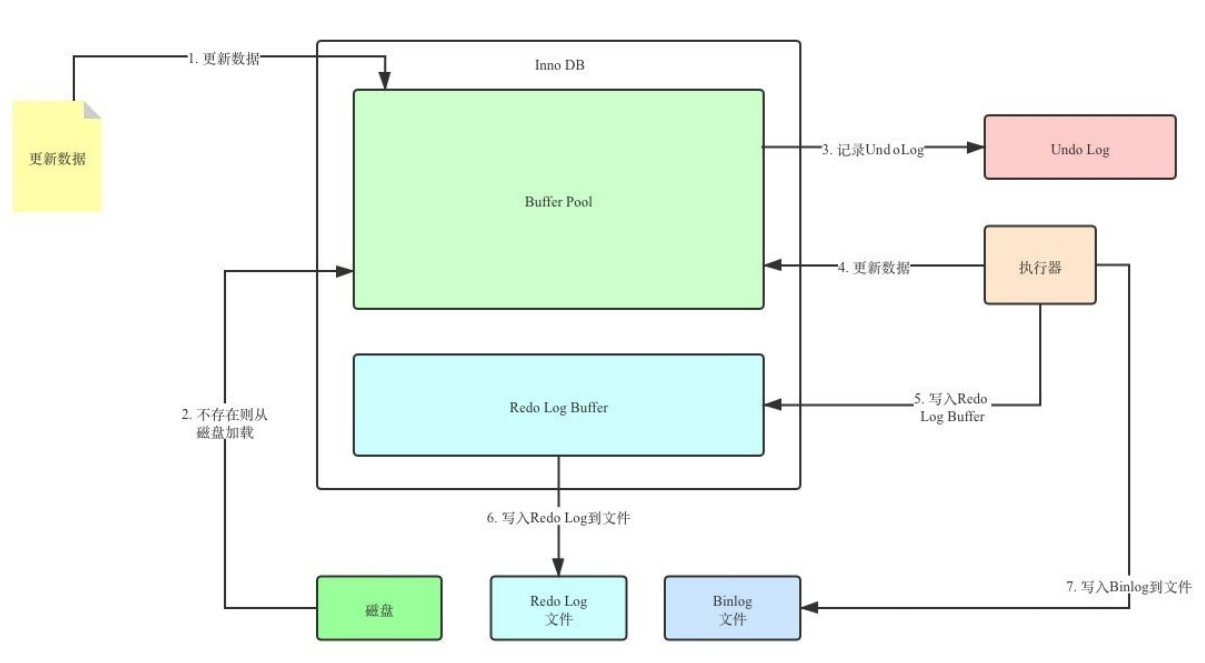
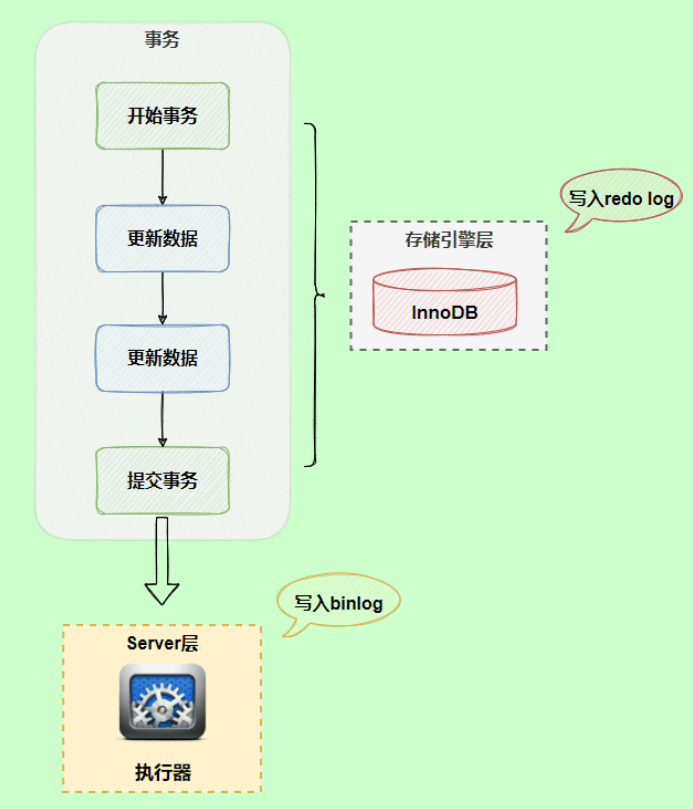
Redo Log REDO LOG称为重做日志 ,当MySQL服务器意外崩溃或者宕机后,保证已经提交的事务持久化到磁盘中(持久性)。 InnoDB是以页为单位去操作记录的,增删改查都会加载整个页到buffer
Redo LogREDO LOG称为重做日志 ,当MySQL服务器意外崩溃或者宕机后,保证已经提交的事务持久化到磁盘中(持久性)。 InnoDB是以页为单位去操作记录的,增删改查都会加载整个页到buffer pool中(磁盘->内存),事务中的修改操作并不是直接修改磁盘中的数据,而是先修改内存中buffer pool中的数据,后台线程每隔一段时间再异步刷新到磁盘中。 buffer pool:可存放索引、数据,可加速读写,直接在内存中操作数据页,有专门的线程去把buffer pool中的脏页写入磁盘。 为什么不直接修改磁盘中的数据? 因为直接修改磁盘数据的话,它是随机IO,修改的数据分布在磁盘中不同的位置,需要来回的查找,所以命中率低,消耗大,而且一个小小的修改就不得不将整个页刷新到磁盘,利用率低; 与之相对的是顺序IO,磁盘的数据分布在磁盘的一块,所以省去了查找的过程,节省寻道时间。 使用后台线程以一定的频率去刷新磁盘可以降低随机IO的频率,增加吞吐量,这是使用buffer pool的根本原因。 修改内存再异步同步到磁盘的问题: 因为buffer pool是在内存中的区域,系统意外崩溃的话数据有可能会丢失,有些脏数据可能会来不及刷新到磁盘,事务的持久性得不到保证。因此,引入了redo log。修改数据时,额外记录一次日志,内容是xx页xx偏移量发生了xx变化,当系统崩溃时可以根据日志内容进行恢复。 写日志和直接刷新磁盘的区别是:写日志是追加写入,顺序IO,速度更快,且写入的内容相对更小 redo log由两部分组成:
修改操作大致过程:
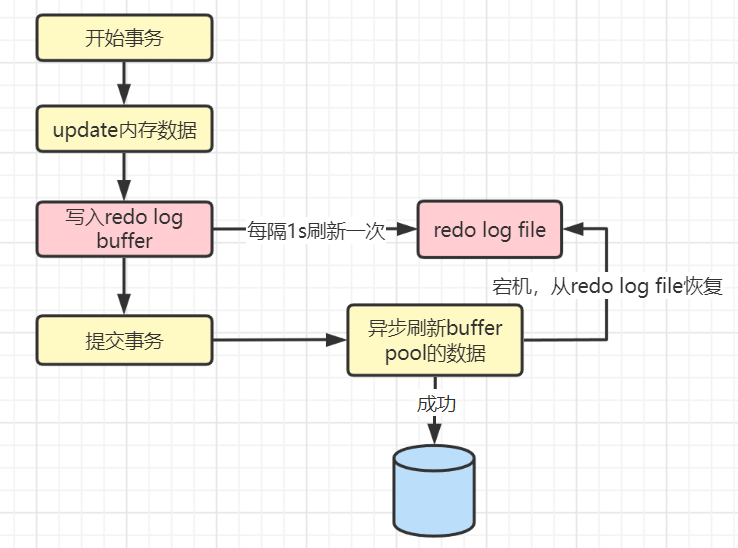
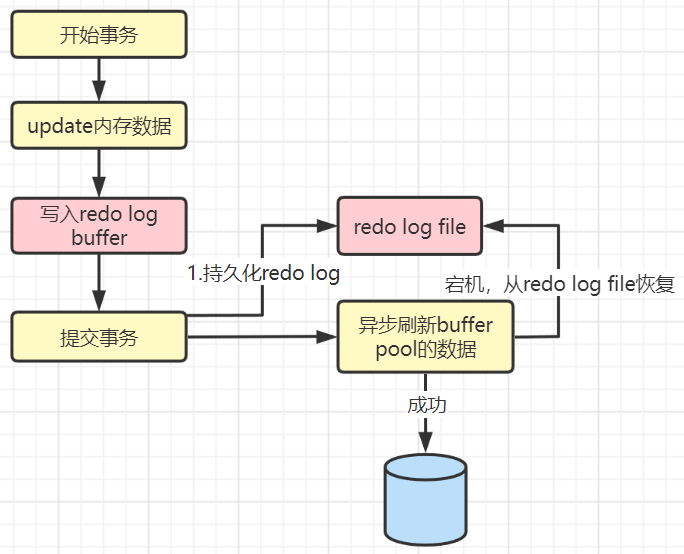
第1步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝,产生脏数据 第2步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值 第3步:默认在事务提交后将redo log buffer中的内容刷新到redo log file,对redo log file采用追加写的方式 第4步:定期将内存中修改的数据刷新到磁盘中(这里说的是那些还没及时被后台线程刷盘的脏数据) 通常所说的Write-Ahead Log(预先日志持久化)指的是在持久化一个数据页之前,先将内存中相应的日志页持久化。 redo log的好处:
redo log一定能保证事务的持久性吗? 不一定,这要根据redo log的刷盘策略决定,因为redo log buffer同样是在内存中,如果提交事务之后,redo log buffer还没来得及将数据刷新到redo log file进行持久化,此时发生宕机照样会丢失数据。如何解决?刷盘策略。 redo log刷盘策略InnoDB中给出了innodb_flush_log_at_trx_commit参数控制redo log buffer刷新到redo log file时的三种策略:
值为0的情况:
因为有1s的间隔,所以最坏情况下会丢失1秒的数据。 值为1的情况:
commit时需要先主动刷新redo log buffer到redo log file,如果中途宕机了,事务也就失败了,不会有任何损失,真正能保证事务的持久性。但是效率最差。 值为2的情况:是根据os决定。 可以调整为0或2提高事务的性能,但是丧失了ACID特性 其他参数
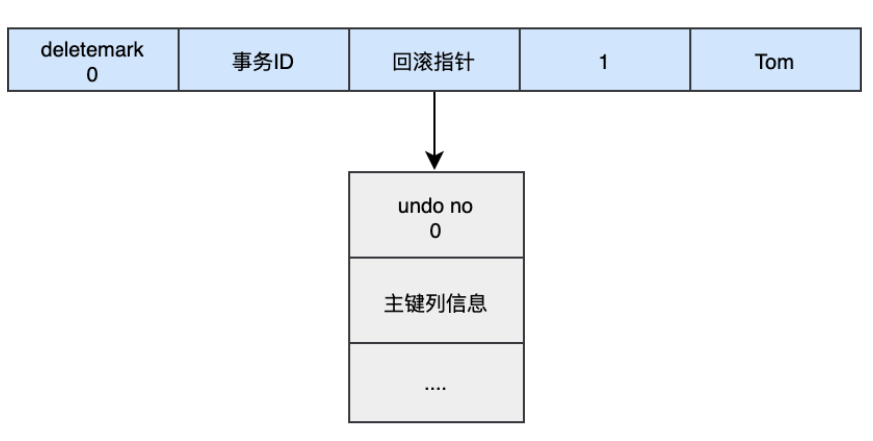
Undo Logundo log用于保证事务的原子性和一致性。作用有两个:①提供回滚操作 ②多版本控制MVVC 回滚操作 前面redo log中说过,后台线程会不定时的去刷新buffer pool中的数据到磁盘,但是如果该事务执行期间出现各种错误(宕机)或者执行rollback语句,那么前面刷进去的操作都是需要回滚的,保证原子性,undo log就是提供事务回滚的。 MVVC 当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据版本是怎样的,从而让用户能够读取到当前事务操作之前的数据——快照读。 快照读:SQL读取的数据是历史版本,不用加锁,普通的SELECT就是快照读。 undo log的组成部分:
select操作不会产生undo log 回滚段与undo页在InnoDB存储引擎中,undo log使用rollback segment回滚段进行存储,每隔回滚段包含了1024个undo log segment。 MySQL5.5之后,一共有128个回滚段。即总共可以记录128 * 1024个undo操作。 每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务。 事务提交后不能立即删除该undo log,可能有些事务会想要读取之前的数据版本(快照读)。所以事务提交时将undo log放入一个链表中,称为版本链,undo log的删除与否由一个称为purge的线程判断。 Undo类型undo log分为: insert undo log 因为insert操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该undo log可以在事务提交后直接删除。不需要进行purge操作。 update undo log update undo log记录的是对delete和update操作产生的undo log。该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。 undo log的生命周期假设有2个数值,分别为A=1和B=2,然后某个事务将A修改为3,B修改为4,修改过程可简化为:
详细生成过程对于InnoDB引擎来说,每个行记录除了记录本身的数据之外,还有几个隐藏的列:
当我们执行INSERT时:
插入的数据都会生成一条insert undo log,并且数据的回滚指针会指向它。undo log会记录undo log的序号、插入主键的列和值...,那么在进行rollback的时候,通过主键直接把对应的数据删除即可。
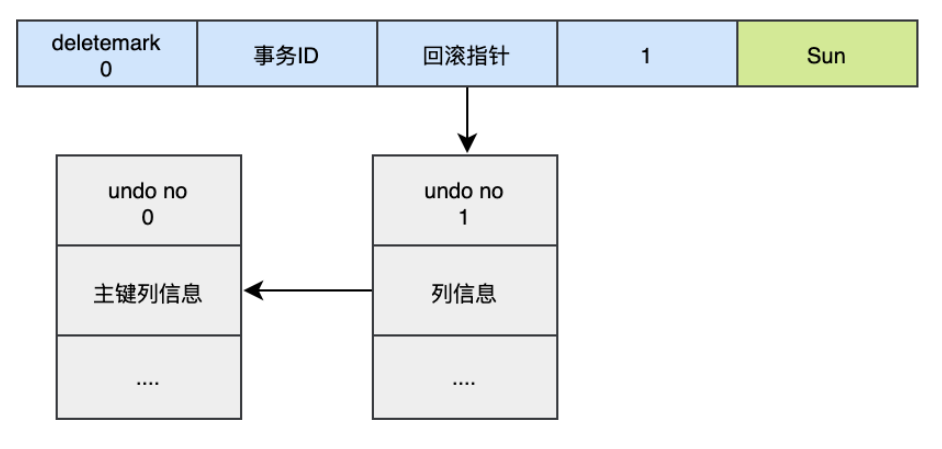
当我们执行UPDATE时: 对于更新的操作会产生update undo log,并且会分更新主键的和不更新主键的,假设现在执行:
这时会把新的undo log记录加入到版本链中,它的undo no是1,并且新的undo log的回滚指针会指向老的undo log (undo no=0)。 假设现在执行:
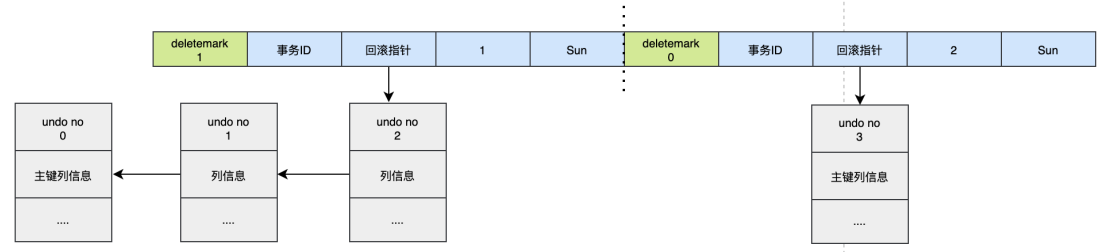
对于更新主键的操作,会先把原来的数据deletemark标识打开,这时并没有真正的删除数据,真正的删除会交给清理线程去判断,然后在后面插入一条新的数据,新的数据也会产生undo log,并且undo log的序号会递增。 可以发现每次对数据的变更都会产生一个undo log,当一条记录被变更多次时,那么就会产生多条undo log,undo log记录的是变更前的日志,并且每个undo log的序号是递增的,那么当要回滚的时候,按照序号依次向前推,就可以找到我们的原始数据了。 undo log是如何回滚的以上面的例子来说,假设执行rollback,那么对应的流程应该是这样: 1. 通过undo no=3的日志把id=2的数据删除 2. 通过undo no=2的日志把id=1的数据的deletemark还原成0 3. 通过undo no=1的日志把id=1的数据的name还原成Tom 4. 通过undo no=0的日志把id=1的数据删除 MySQL MVVC多版本并发控制 扩展bin logbinlog即binary log,二进制日志文件,也叫作变更日志(update log)。它记录了数据库所有执行的更新语句。 binlog主要应用场景:
查看bin log日志:
使用日志恢复数据:
删除二进制日志:
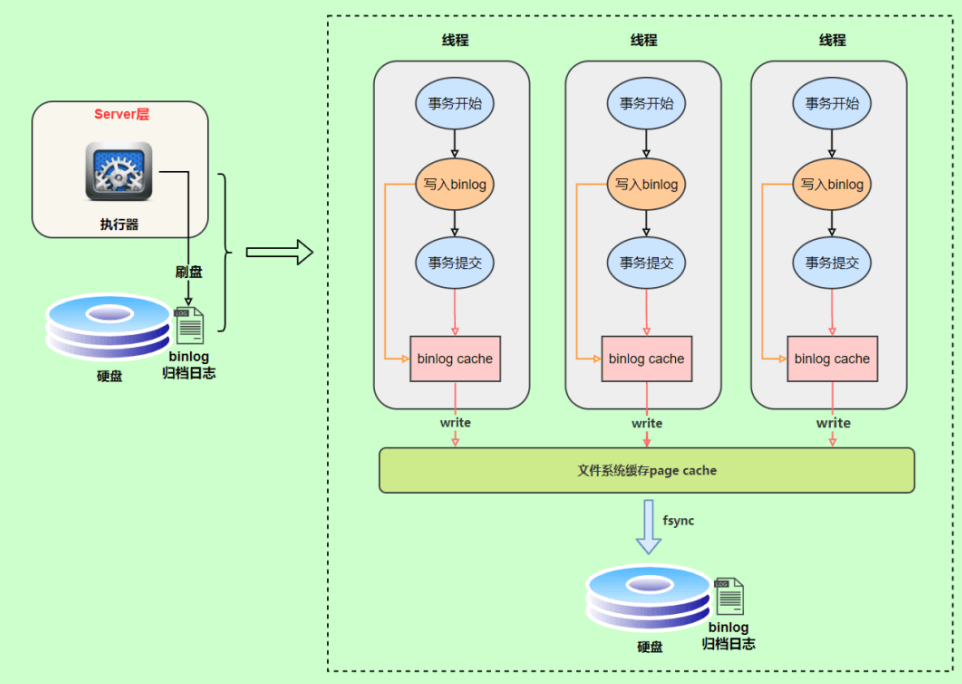
写入时机事务执行过程中,先把日志写到bin log cache ,事务提交的时候,再把binlog cache写到binlog文件中。因为一个事务的binlog不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为binlog cache。
binlog与redo log对比
两个侧重点也不同, redo log让InnoDB有了崩溃恢复的能力,binlog保证了MySQL集群架构的数据一致性。 两阶段提交在执行更新语句过程,会记录redo log与binlog两块日志,以基本的事务为单位,redo log在事务执行过程中可以不断写入,而binlog只有在提交事务时才写入,所以redo log与binlog的写入时机不一样。
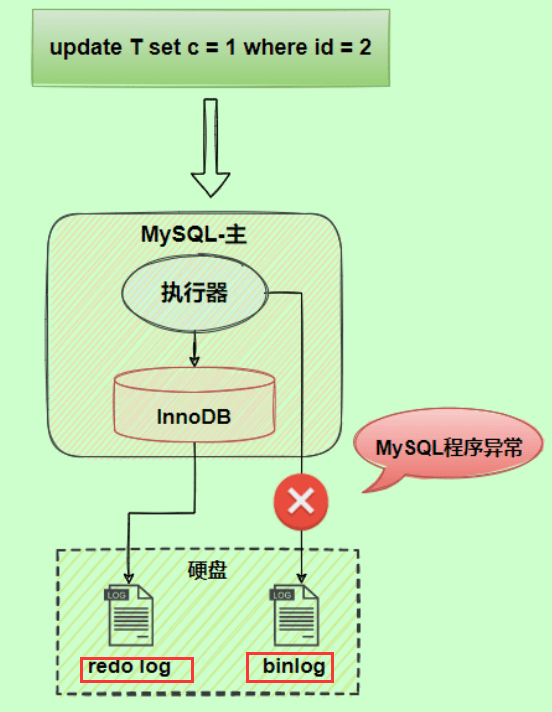
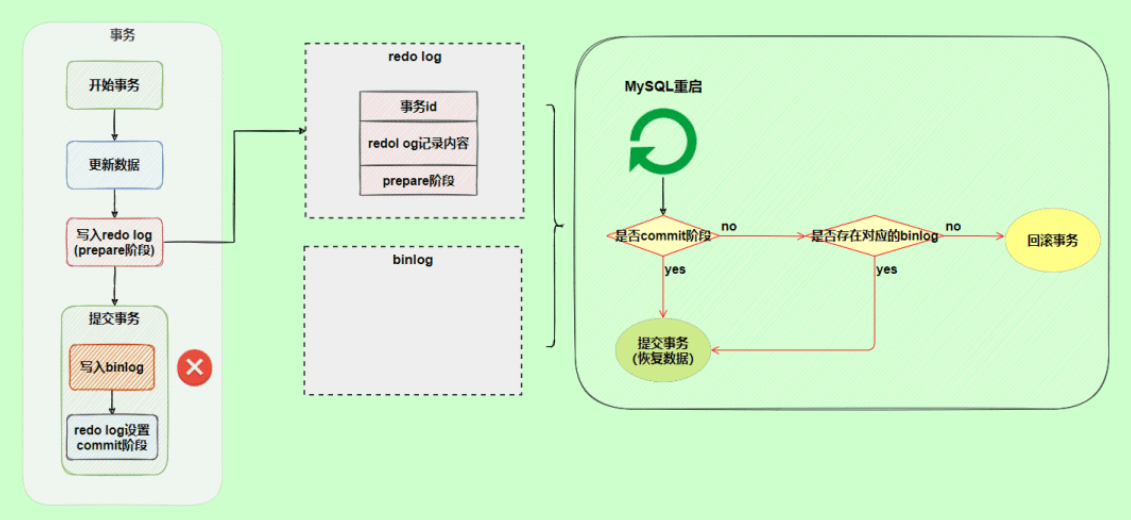
redo log与binlog两份日志之间的逻辑不一致,会出现什么问题? 以update语句为例,假设id=2的记录,字段c值是0,把字段c值更新成1,SQL语句为update T set c=1 where id=2。 假设执行过程中写完redo log日志后,binlog日志写期间发生了异常,会出现什么情况呢?
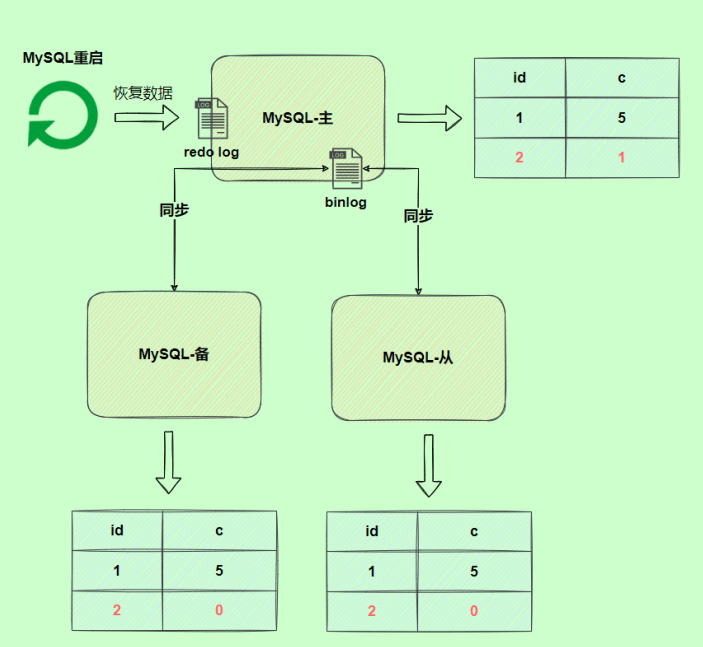
由于binlog没写完就异常,这时候binlog里面没有对应的修改记录。因此,之后用binlog日志恢复数据或者slave读取master的binlog时,就会少这一次更新,恢复出来的这一行c值是0,而原库因为redo log日志恢复,这一行c值是1,最终数据不一致。
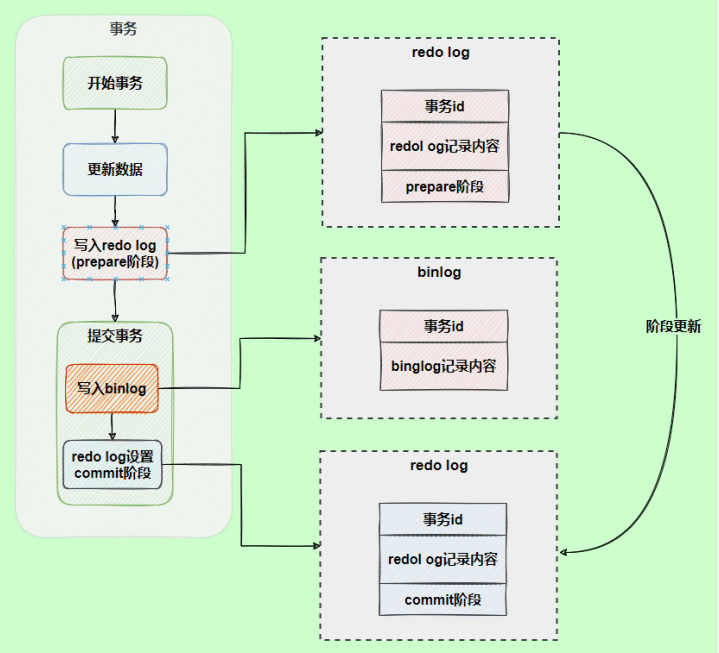
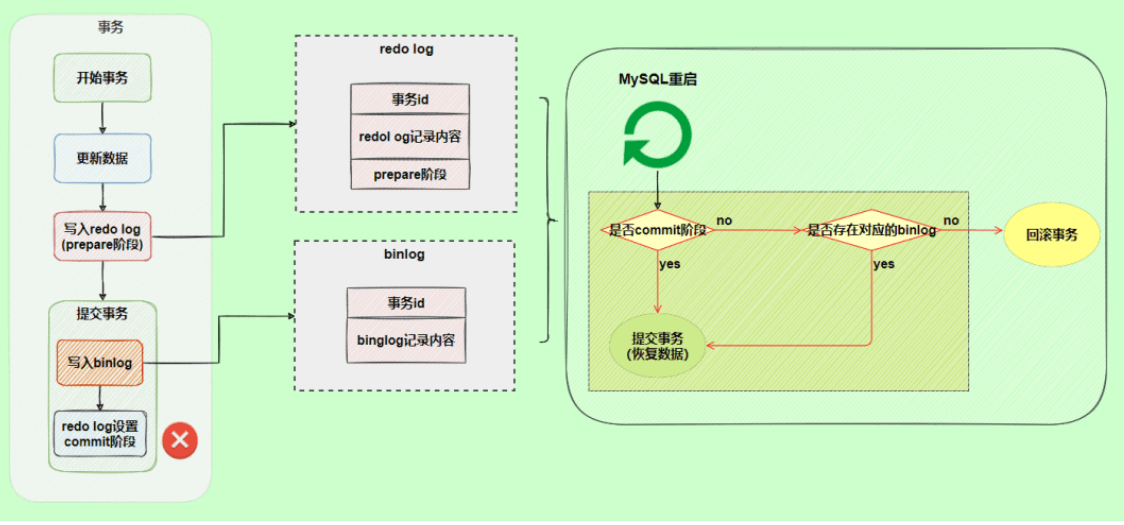
为了解决两份日志之间的逻辑一致问题,InnoDB存储引擎使用两阶段提交方案。将redo log拆成了两个步骤prepare和commit,这就是两阶段提交。 让redo log和bin log最终的提交绑定到一起,前面说过的,事务commit时默认需要让redo log先同步完才算commit成功,所以如果绑定到一起的话,bin log也具有该特性了,就保证了数据不会丢失。
使用两阶段提交后,写入binlog时发生异常也不会有影响,因为MySQL根据redo log日志恢复数据时发现redo log还处于prepare阶段,并且没有对应binlog日志,就会提交失败,回滚数据。
另一个场景,redo log的commit阶段发生异常,那会不会回滚事务呢?
并不会回滚事务,它会执行上图框住的逻辑,虽然redo log是处于prepare阶段,但是能通过事务id找到对应的binlog日志,所以MySQL认为是完整的,就会提交事务恢复数据。 |





2021-06-02
2021-06-05
2022-06-27
2022-10-12
2019-09-11