今天我们来探讨一个有意思的问题,先说场景: 这是一个做在线文档产品的业务,需要给用户展示文档的编辑记录,现在我们叫它【智能文档】。 智能文档会不定期给文档数据打一个
|
今天我们来探讨一个有意思的问题,先说场景:
那如何实现查找两个快照之间的【变更记录】有哪些呢? 快照 和 变更记录 预期是两张表。首先我们不能将【变更记录】通过 id 挂在某个【快照】上,因为我们的快照是不断被回收的,这样的话当你回收快照时,也需要连带着更新大量的【变更记录】,出现写扩散。 另一个想法是,能否通过时间戳进行比较?比如快照 A 的创建时间戳是 12345,快照 B 的创建时间戳是 23456。那么我只要【变更记录】这张表也有一个时间戳字段,写一个 SQL 查到两个快照时间戳之间的变更记录是不是就可以了? 写出来 SQL 类似这样:
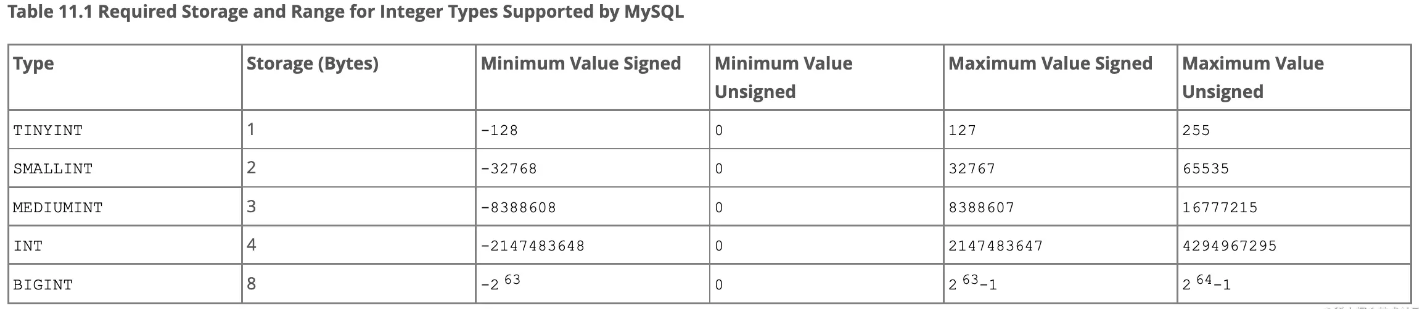
那么,问题来了,这个 create_time,虽然这里我们直接拿时间戳比较,但真的是性能最好的么?建表的时候,我应该用 datetime, timestamp 还是 int ? 今天我们就来看看到底有什么区别。 MySQL 支持的数据类型任何一篇博客,教程都比不上官方文档,大家选型有疑虑时还是建议先来看看 MySQL Data Types 。 Integer我们先来看 integer 有什么类型。 SQL 标准中对于整数,提出了两种类型:INTEGER(INT) 以及 SMALLINT。在此之外,MySQL 还额外提供了 TINYINT, MEDIUMINT, BIGINT 三种类型。 所以一共是五种:
可以看到,INT 其实和我们通常用的 int32 是一样的,本质是 2 的 31 次方 - 1,大概21亿4千7百万。(正整数以二进制存储。负整数以补码存储。一个Int类型数据占据空间4字节。每个字节8位,共32位。因此最大存储2的31次方(从2的0次方开始)。但32位的第一位是符号位。所以2的31次方减1.简单说Int类型占据4字节,所以是这个取值范围。) 这里 BIGINT 就等价于 int64。 Datetimedatetime 其实是一个统称,MySQL 提供了 DATE, DATETIME, TIMESTAMP 三种类型。
DATE 类型没有具体的时间点,只能精确到【日期】,即 YYYY-MM-DD,比如 1994-06-09。
DATETIME 则同时支持【日期】和【时间】,格式为 YYYY-MM-DD hh:mm:ss。如 1995-04-29 17:11:12。
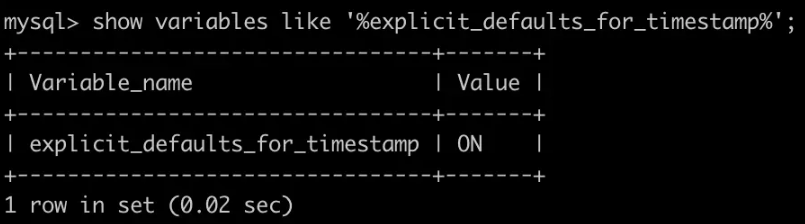
TIMESTAMP 同样也支持【日期】和【时间】,但由于带上了时间戳的语义,就不如 DATETIME 支持的范围那么宽了。UTC 时间,从'1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' 因为此前的系统设计都是基于 32 位实现的,我们上面提到过,最多无非是 2 的 31次方 - 1,每个数代表一秒的话,最多表示 68 年。所以 Unix 选取了 1970年1月1日作为UNIX TIME的纪元时间(开始时间)。 这里我们主要还是关心 DATETIME 以及 TIMESTAMP,二者除了整秒之外,还可以支持小数点后的部分,最多到 microseconds (6位)精度。格式为 'YYYY-MM-DD hh:mm:ss[.fraction]',比如 '2038-01-19 03:14:07.999999' (事实上这也是 TIMESTAMP 能支持的最大值)。 除此之外,二者也都支持 自动初始化(Automatic Initialization)。这里要用到的两个大杀器:
二者可以同时出现,也可以单独出现,分几种情况:
此时 ts 和 dt 的默认值就是当前时间,当这一行其他值发生变化时,也会自动把这两个属性更新为当前时间。
此时只有初始化的时候才会写入当前时间,随后更新时不会变动。(当然,我们也可以把 CURRENT_TIMESTAMP 换成一个常数,比如 0,语法上是支持的,只不过那样就不是当前时间了)
此时没有指定默认值,但发生更新时会改为当前时间,这时的默认值就是 type dependent,依赖类型了。 TIMESTAMP 的默认值为 0,如果定义了 NULL 则默认值为 NULL。
这次我们换成了 DATETIME,二者正好相反,不指定 DEFAULT 的话,默认值为 NULL,但如果我们声明了 NOT NULL,则默认值变成 0。
TIMESTAMP
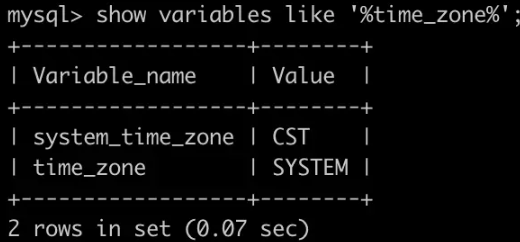
TIMESTAMP 底层采用 4 个字节存储(2的31次方-1,还记得么),能支持的时间范围比 DATETIME 要小一倍,但它的特点在于,当我们写入时,MySQL会根据当前 server 所在的时区进行转换,将值变成 UTC 时区的时间,再存储。同样的,在查询的时候,MySQL 也会帮助我们转成当前时区再展示。这是 DATETIME 不具备的。 这样的跨时区支持,在一些业务场景下是很有用的。毕竟存储时间这件事情本身是很敏感的。海外用户一开始请求到了新加坡机房,落了一个时间。随后跑到欧洲玩耍,在法国重新访问,发现跟本地时间完全对不上,这就有问题了。 所以 TIMESTAMP 的思路就是,大家都以 UTC 时间为准,这是个基线,不管你是哪个时区的,我都要转成统一的时间,查询的时候给你转回去就是了。 我们可以用 show variables like '%time_zone%'; 来查看当前库的时区:
需要注意,当MySQL参数time_zone=system时,查询timestamp字段会调用系统时区做时区转换,而由于系统时区存在全局锁问题,在多并发大数据量访问时会导致线程上下文频繁切换,CPU使用率暴涨,系统响应变慢设置假死。
使用 SET TIME_ZONE = 'america/new_york"; 来设置时区。每个连接可以使用不同的时区
可以实验一下,在一个时区写入 TIMESTAMP 数据,切换时区后读出来,显示的时间是不一样的,而 DATETIME 则是完全一致的。demo DATETIMEDATETIME 底层采用 8 个字节存储,没有跨时区的支持,结果直接展示。你存进去的是什么时间,读到的就是什么时间。不过我们如果需要跨时区,也不是没有办法,可以在读出来 DATETIME 后转为时间戳,从业务代码层面来处理,想转成什么时区都 OK。 这里不用担心 2038 年的限制,虽然空间大了一倍,但通常情况下不会造成多大性能影响。 Integer这里在讨论完 DATETIME, TIMESTAMP 之后,我们回过头来看看 Integer。 为什么我们能用一个整数来代表时间呢?这里本质是我们给它赋予了【时间戳】的语义。 虽然整数的上下限更大(比如我们用 BIGINT,可以支持 2 的 63 次方 - 1 的数据),但是,但是,用法是关键。 如果你打算还用时间戳函数进行生成和转换,那就需要关注 2038 年这个限制,本质上和 TIMESTAMP 是没有区别的。 所以,通常我们认为,用整型时间戳的形式,取值范围也是 1970 年 1 月 1日起,到 2038 年截止,这个区间。用 BIGINT 的意义不大,只要它的语义还是时间戳,就需要遵循这个规范。 BETWEEN 查询回到我们一开始提到的案例,我们需要筛选出两个时间点之间,有哪些【变更记录】。 如果是整型,我们其实经常使用 BETWEEN 来进行查询:
它和下面直接用运算符的形式是等价的,注意 BETWEEN 是个闭区间:
同样的,查询 datetime 依然可以用 BETWEEN:
下面两个查询也是等价的:
当然,我们也可以用 now() 等函数作为辅助,注意 between 里面一定要先写小的时间,and 后面写更大的时间点。 性能差异
其实 DATETIME 和 TIMESTAMP 底层也是整型存储(否则就不会按照 2 的31 次方,63 次方来支持了),算是一层封装,提供了一系列时间函数使用。 DATETIME 底层存储实现是 BigInt,索引存储上和 BigInt 的处理是几乎一模一样的,所以 BigInt 支持的索引查询,datetime也支持。 加上索引后的速度如何,推荐大家阅读这一篇 benchmark MYSQL 数据库时间字段 INT,TIMESTAMP,DATETIME 性能效率的比较介绍 这里引用一下结论:
大家可以尝试一下,结合你的业务场景,跑一下 explain 看看。 |





2021-06-02
2021-06-05
2022-06-27
2022-10-12
2019-09-11