
MySQL进阶之路索引失效的11种情况介绍

在MySQL的查询优化中,索引是一项至关重要的技术,它能够大大提升数据检索的效率。本文将讨论这11种常见情况,帮助开发者更好地理解索引的使用及优化。 图示 1.使用不等式操作符(!=,,)
|
在MySQL的查询优化中,索引是一项至关重要的技术,它能够大大提升数据检索的效率。本文将讨论这11种常见情况,帮助开发者更好地理解索引的使用及优化。 图示
1. 使用不等式操作符(!=, <, >)
2. 使用 OR 连接多个条件
3. 对索引字段进行计算操作
4. 对索引字段进行类型转换
5. LIKE 头部模糊查询
6. NULL 值的查询
7. DISTINCT 或 GROUP BY 操作
8. JOIN 查询中没有适当的索引
9. 排序(ORDER BY)与索引不匹配
10. 表连接顺序不当
11. 启用 NO_INDEX 或 FORCE INDEX 提示时的索引失效
总结在 SQL 查询优化中,合适的索引设计和查询结构调整是提高性能的关键。通过以下措施可以避免常见的性能瓶颈:
|

您可能感兴趣的文章 :

-
MySQL逻辑备份的实现方法
MySQL 的逻辑备份指的是使用 SQL 语句备份数据库的结构和数据,而不是直接备份数据库文件。通常使用mysqldump工具进行逻辑备份。 一.mysqld -

navicat连接Mysql数据库报2013错误解决办法
报错信息 Navicat连接mysql报2013错误 2013-Lost connection to MYSQL server at waitting for initial communication packet,system error:0 1、检验Mysql数据库是否安装成 -
MySQL实现索引下推的代码
索引下推(Index Condition Pushdown, 简称ICP)是一种数据库优化技术,旨在减少数据库查询过程中从存储引擎到数据库引擎的数据传输量,从而提 -

Mysql8主从复制解读(兼容低高版本)
Mysql主从复制 理论知识 主从复制必要前提 主从复制必要的条件: 主库开启binlog日志(设置log-bin参数) 主从server-id不同 从库服务器能连同 -
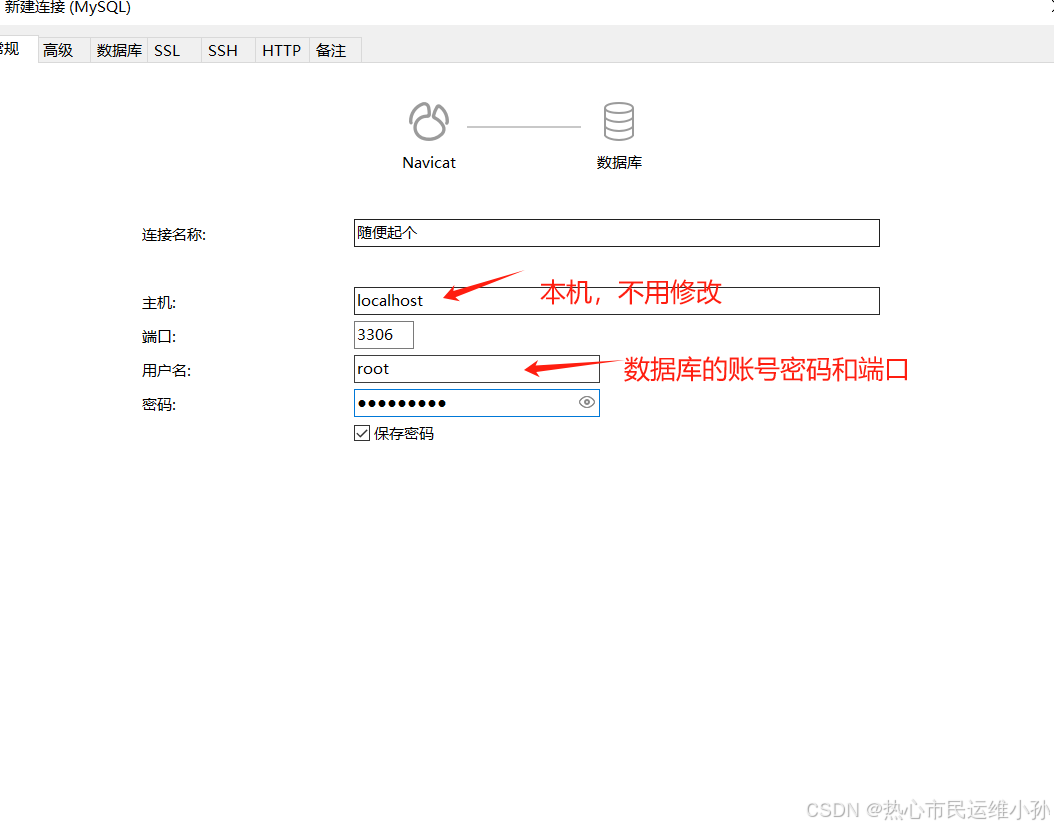
Navicat如何通过ssh连接mysql
navicat 通过ssh连接mysql 对搭建完的mysql连接时,通过ssh连接的方法 需要确保mysql默认端口3306没有被防火墙阻拦 第一步 第二步 需要注意的是乌 -
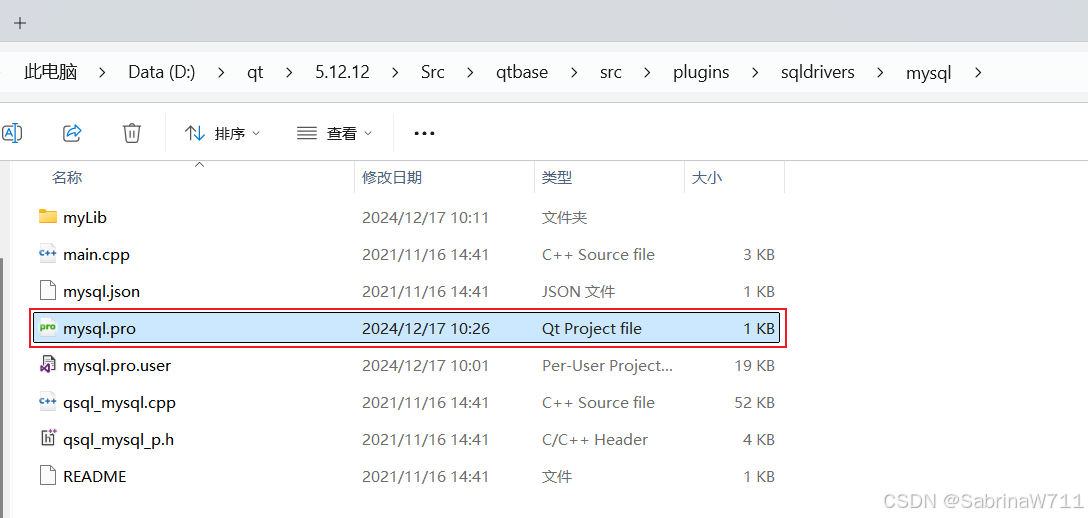
Qt如何编译MySQL数据库驱动
Qt编译MySQL数据库驱动 (1)先找到MySQL安装路径以及Qt安装路径 C:\Program Files\MySQL\MySQL Server 8.0 D:\qt\5.12.12 (2)在D:\qt\5.12.12\Src\qtbase\src\plugi -
MySQL中禁止修改数据库表特定列的实现
在数据库设计过程中,有时我们需要确保某些列的数据不被修改,以保护数据的一致性和完整性。MySQL 数据库提供了多种方式来达到这个目 -
MySQL安装报错找不到MSVCR120.dll文件丢失的解决方案
遇到MSVCR120.dll 文件丢失问题通常是因为Microsoft Visual C++ Redistributable文件丢失或未正确安装。 MSVCR120.dll是 Microsoft Visual C++ Redistributable for Vi



-
zabbix监控mysql的实例方法
2021-06-02
-
MySQL时间类型的选择
2021-06-05
-
MySQL数据库基本SQL语句教程之高级操作
2022-06-27
-
MySQL文件权限存在的安全问题和解决方
2024-07-31
-
利用Mysql定时+存储过程创建临时表统
2024-02-19

