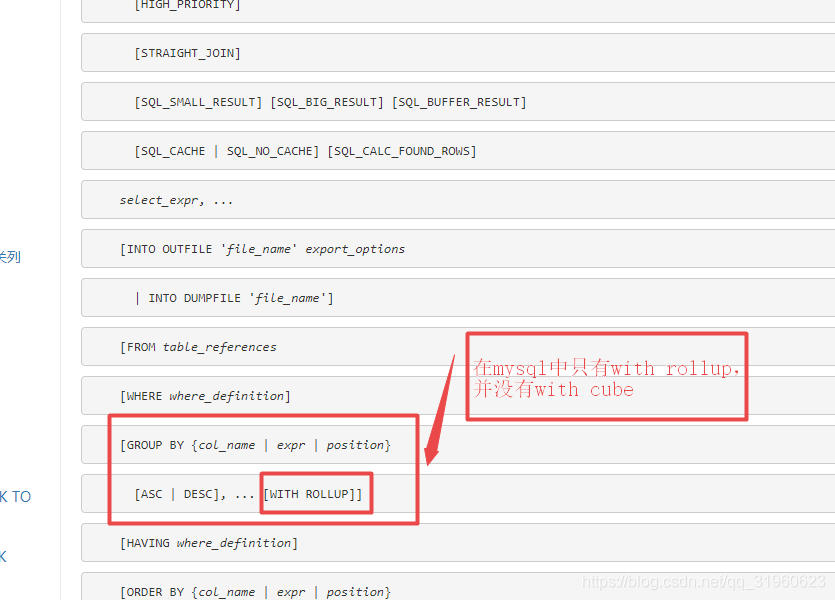
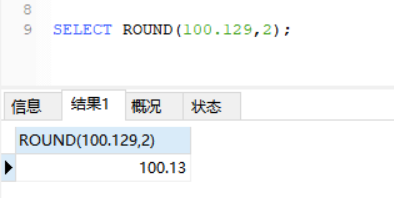
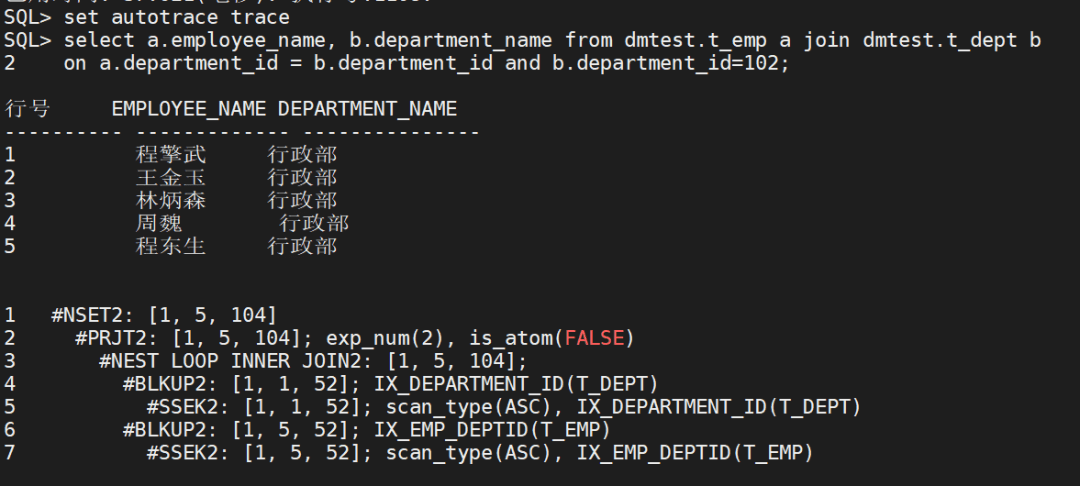
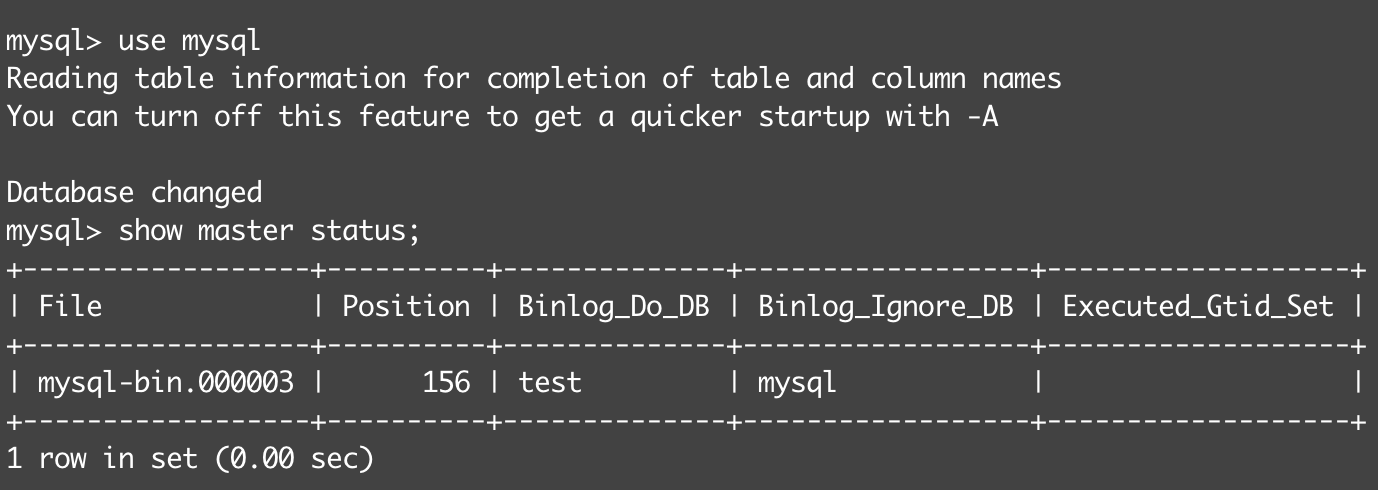
MySQL中存储时间通常会用datetime类型,但现在很多系统也用int存储unix时间戳,它们有什么区别?本人总结如下:
int
(1)4个字节存储,INT的长度是4个字节,存储空间上比datatime少,int索引存储空间也相对较小,排序和查询效率相对较高一点点
(2)可读性极差,无法直观的看到数据
TIMESTAMP
(1)4个字节储存
(2)值以UTC格式保存
(3)时区转化 ,存储时对当前的时区进行转换,检索时再转换回当前的时区。
(4)TIMESTAMP值不能早于1970或晚于2037
datetime
(1)8个字节储存
(2)与时区无关
(3)以'YYYY-MM-DD HH:MM:SS'格式检索和显示DATETIME值。支持的范围为'1000-01-01 00:00:00'到'9999-12-31 23:59:59'
随着Mysql性能越来越来高,个人觉得关于时间的存储方式,具体怎么存储看个人习惯和项目需求吧
分享两篇关于int vs timestamp vs datetime性能测试的文章
Myisam:MySQL DATETIME vs TIMESTAMP vs INT 测试仪
CREATE TABLE `test_datetime` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`datetime` FIELDTYPE NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM;
|
机型配置
-
kip-locking
-
key_buffer = 128M
-
max_allowed_packet = 1M
-
table_cache = 512
-
sort_buffer_size = 2M
-
read_buffer_size = 2M
-
read_rnd_buffer_size = 8M
-
myisam_sort_buffer_size = 8M
-
thread_cache_size = 8
-
query_cache_type = 0
-
query_cache_size = 0
-
thread_concurrency = 4
测试
DATETIME 14111 14010 14369 130000000
TIMESTAMP 13888 13887 14122 90000000
INT 13270 12970 13496 90000000
执行mysql
mysql> select * from test_datetime into outfile ‘/tmp/test_datetime.sql';
Query OK, 10000000 rows affected (6.19 sec)
mysql> select * from test_timestamp into outfile ‘/tmp/test_timestamp.sql';
Query OK, 10000000 rows affected (8.75 sec)
mysql> select * from test_int into outfile ‘/tmp/test_int.sql';
Query OK, 10000000 rows affected (4.29 sec)
alter table test_datetime rename test_int;
alter table test_int add column datetimeint INT NOT NULL;
update test_int set datetimeint = UNIX_TIMESTAMP(datetime);
alter table test_int drop column datetime;
alter table test_int change column datetimeint datetime int not null;
select * from test_int into outfile ‘/tmp/test_int2.sql';
drop table test_int;
|
So now I have exactly the same timestamps from the DATETIME test, and it will be possible to reuse the originals for TIMESTAMP tests as well.
mysql> load data infile ‘/export/home/ntavares/test_datetime.sql' into table test_datetime;
Query OK, 10000000 rows affected (41.52 sec)
Records: 10000000 Deleted: 0 Skipped: 0 Warnings: 0
mysql> load data infile ‘/export/home/ntavares/test_datetime.sql' into table test_timestamp;
Query OK, 10000000 rows affected, 44 warnings (48.32 sec)
Records: 10000000 Deleted: 0 Skipped: 0 Warnings: 44
mysql> load data infile ‘/export/home/ntavares/test_int2.sql' into table test_int;
Query OK, 10000000 rows affected (37.73 sec)
Records: 10000000 Deleted: 0 Skipped: 0 Warnings: 0
As expected, since INT is simply stored as is while the others have to be recalculated. Notice how TIMESTAMP still performs worse, even though uses half of DATETIME storage size.
Let's check the performance of full table scan:
mysql> SELECT SQL_NO_CACHE count(id) FROM test_datetime WHERE datetime > ‘1970-01-01 01:30:00′ AND datetime < ‘1970-01-01 01:35:00′;
+———–+
| count(id) |
+———–+
| 211991 |
+———–+
1 row in set (3.93 sec)
mysql> SELECT SQL_NO_CACHE count(id) FROM test_timestamp WHERE datetime > ‘1970-01-01 01:30:00′ AND datetime < ‘1970-01-01 01:35:00′;
+———–+
| count(id) |
+———–+
| 211991 |
+———–+
1 row in set (9.87 sec)
mysql> SELECT SQL_NO_CACHE count(id) FROM test_int WHERE datetime > UNIX_TIMESTAMP('1970-01-01 01:30:00′) AND datetime < UNIX_TIMESTAMP('1970-01-01 01:35:00′);
+———–+
| count(id) |
+———–+
| 211991 |
+———–+
1 row in set (15.12 sec)
|
Then again, TIMESTAMP performs worse and the recalculations seemed to impact, so the next good thing to test seemed to be without those recalculations: find the equivalents of those UNIX_TIMESTAMP() values, and use them instead:
mysql> select UNIX_TIMESTAMP('1970-01-01 01:30:00′) AS lower, UNIX_TIMESTAMP('1970-01-01 01:35:00′) AS bigger;
+——-+——–+
| lower | bigger |
+——-+——–+
| 1800 | 2100 |
+——-+——–+
1 row in set (0.00 sec)
mysql> SELECT SQL_NO_CACHE count(id) FROM test_int WHERE datetime > 1800 AND datetime < 2100;
+———–+
| count(id) |
+———–+
| 211991 |
+———–+
1 row in set (1.94 sec)
|
Innodb:MySQL DATETIME vs TIMESTAMP vs INT performance and benchmarking with InnoDB