
怎么在Neo4j与PostgreSQL间实现高效数据同步

1. 引言 在当今数字化时代,数据已成为企业的核心资产。随着业务的不断扩展和技术的快速发展,企业常常需要同时运用多种数据库系统来满足不同的业务需求。在这种背景下,Neo4j作为领先的图
1. 引言在当今数字化时代,数据已成为企业的核心资产。随着业务的不断扩展和技术的快速发展,企业常常需要同时运用多种数据库系统来满足不同的业务需求。在这种背景下,Neo4j作为领先的图数据库,以其高效的关系数据处理能力而备受青睐;而PostgreSQL作为功能强大的关系型数据库,则以其稳定性和可扩展性而闻名。然而,如何在这两种截然不同的数据库系统之间实现高效、可靠的数据同步,成为了许多企业面临的一大挑战。 本文旨在为读者提供一个全面的指南,详细阐述如何在Neo4j和PostgreSQL之间构建高效的数据同步机制。我们将深入探讨数据同步的重要性,分析两种数据库系统的特点,并提供从策略设计到技术实现的完整解决方案。无论您是数据库管理员、系统架构师,还是对数据集成感兴趣的技术爱好者,本文都将为您提供宝贵的见解和实用的技巧。 通过阅读本文,您将了解到:
让我们开始这段探索数据同步世界的旅程,一同揭示Neo4j和PostgreSQL协同工作的无限可能! 2. Neo4j与PostgreSQL的基础知识2.1. Neo4j基本概念与架构
Neo4j 是一种高性能的图数据库,它使用图结构存储复杂的网络关系,以节点、关系和属性的形式存储和查询数据。Neo4j的主要特点包括:
2.2. PostgreSQL基本概念与架构
PostgreSQL 是一种功能强大的开源关系型数据库系统,以其稳定性、可扩展性和丰富的特性集而著名。其核心特点包括:
2.3. 数据处理上的不同与互补Neo4j和PostgreSQL在数据处理上有本质的不同,这些差异为它们在特定应用场景中的互补提供了基础:
通过理解这些基本概念和架构的不同,可以更好地设计出符合特定业务需求的数据同步策略,有效地利用两种数据库系统的优势。 3. 数据同步方案设计3.1. Neo4j与PostgresSQL对比说明在我们开始讨论如何同步Neo4j和PostgreSQL之间的数据之前,先来看看它们在数据模型上的异同。为了方便理解,我把两者对应的概念列成了一个表格:
这张表看起来很简单,但如果我们深入分析,每一行其实都揭示了两种数据库背后完全不同的思维方式。 1. 表 vs 图 在PostgreSQL里,数据是存储在表格中的,每张表有固定的结构和字段,比如用户表可能包含用户ID、姓名、邮箱等信息。 简单理解: 表是二维的,一行行数据排列得整整齐齐。图是网络状的,数据之间的连接是它的核心。 2. 行 vs 节点 PostgreSQL中的每一行表示一条具体的记录,比如某个用户的详细信息。 3. 列 vs 属性 在PostgreSQL中,表的每一列都是字段,比如姓名、邮箱这些。 4. 约束 vs 关系 这一点是PostgreSQL和Neo4j最根本的差异。
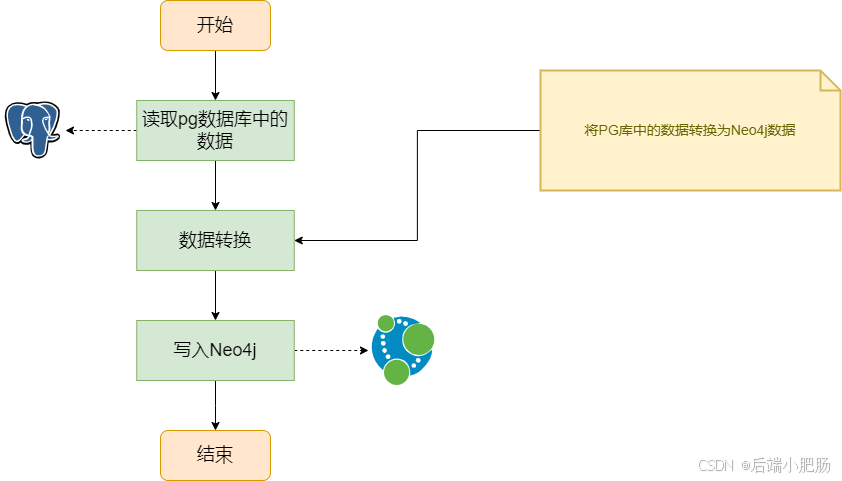
在Neo4j中,你不需要分成两张表,因为好友关系可以直接存在于图中: (张三)-[:朋友]->(李四) 通过这几个对应关系,我们可以看出PostgreSQL更注重结构化的数据存储,而Neo4j更适合表现复杂的数据关系。在设计数据同步方案时,我们的目标就是把PostgreSQL里的表、行、列和约束,巧妙地转换成Neo4j里的图、节点、属性和关系,为下一步的全量同步和增量同步打好基础。简单点说,这就是把二维的表,变成更立体的图,顺便让数据之间的关系更加直观。 3.2. 数据同步技术方案设计在Neo4j与PostgreSQL之间实现数据同步,通常有两种方式:全量同步和增量同步。全量同步通常用于初次数据迁移,而增量同步适用于实时或近实时的增量更新。增量同步和全量同步实现的方式很多,本章仅仅基于Java实现展开。 3.2.1 全量同步全量同步是一种将PostgreSQL中的所有数据一次性迁移到Neo4j的方式,适用于初次数据迁移或定期的全量刷新。
实现步骤: 数据抽取:
数据转换:
批量插入:
数据验证:
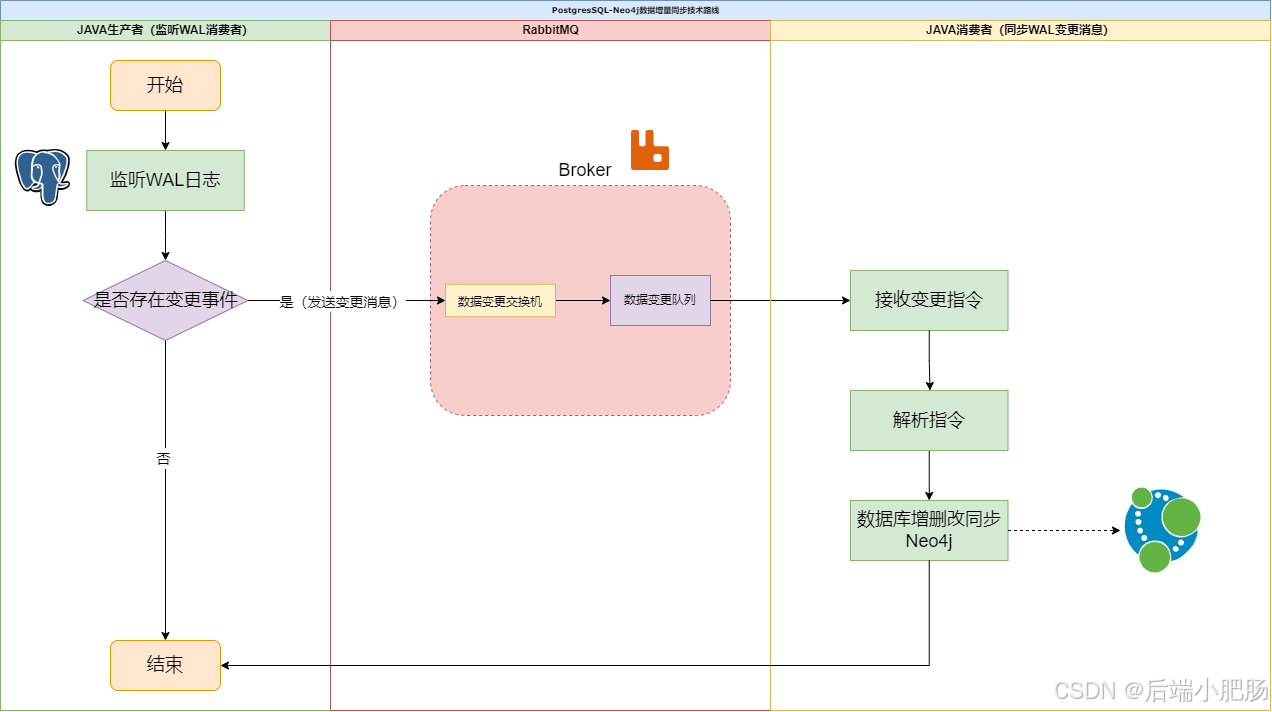
3.2.2. 增量同步增量同步是一种实时或周期性同步数据变更的方式,适用于数据更新频繁、需要实时反映变动的场景。
实现步骤:
4. 技术实现4.1. PostgresSQL表结构设计在本节PG库到Neo4j数据库同步技术实践中,我设计了4张数据表,分别是教师表(xfc_teacher)、学生表(xfc_student)、班级表(xfc_class)、班级和老师关联中间表(xfc_brid_teacher_and_class)。其表关系如下:
4.2. Neo4j 数据模型设计根据提供的关系型数据库表结构,我们设计了如下的 Neo4j 图数据库数据模型:
示意模型 老师和班级:
班级和学生:
对应的 PostgreSQL 数据表和 Neo4j 模型的映射
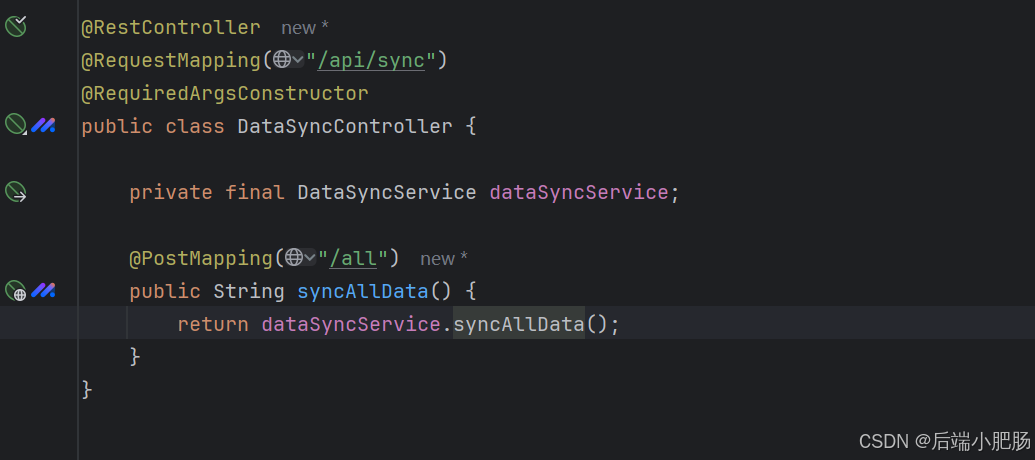
通过这种图模型设计,我们将关系型数据库中的结构化表格数据转换为更直观的图数据结构,为后续的数据同步和分析奠定基础。 4.3. 全量同步代码代码我都放到git仓库了,需要的自己去取。xfc-fdw-cloud: 公共解决方案 1. 全量同步接口:
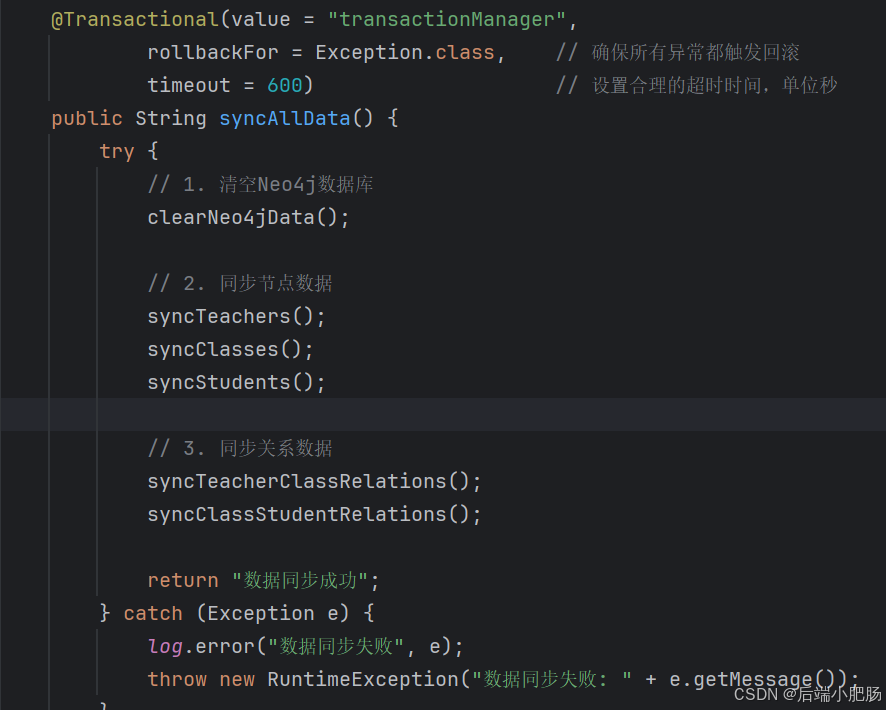
2. 全量同步方法:
3. 多源事务管理配置类:
这段代码是一个Spring配置类,通过定义多个事务管理器(分别用于PostgreSQL和Neo4j)以及一个链式事务管理器(ChainedTransactionManager),实现对多数据源的分布式事务管理,确保事务在多个数据库之间的一致性和原子性。 我就不讲解了,很简单。 4.4. 增量同步代码1. 编写ChangeLogProcessor 代码太长了,我这里就不粘贴了,只粘贴主干代码,要看全都代码可以去仓库。
processChangeLog 函数是一个变更日志处理器,主要功能是接收并处理 PostgreSQL 数据库的变更日志(比如插入、更新、删除操作),然后将这些变更同步到 Neo4j 图数据库中 2. 编写DatabaseChangeService
DatabaseChangeService 是一个数据库变更监听服务,它通过 PostgreSQL 的逻辑复制功能(使用复制槽 replication slot)来捕获数据库的变更事件(如插入、更新、删除),当检测到变更时,会通过 ChangeLogProcessor 处理这些变更并将其同步到 Neo4j 图数据库中,从而实现 PostgreSQL 到 Neo4j 的实时数据同步。这个服务在启动时会自动创建并监听复制槽,并通过循环轮询的方式持续获取变更日志,同时包含了错误处理和重试机制以确保同步的可靠性。 5. 结论本文详细介绍了如何在 Neo4j 与 PostgreSQL 两种数据库之间实现高效数据同步,从基础概念到全量与增量同步的实现策略,结合具体代码与实践案例,为开发者提供了全面的指导。通过充分利用 Neo4j 的关系处理优势与 PostgreSQL 的结构化数据支持,这种同步机制能够满足复杂业务需求,为数据整合和分析提供坚实基础。希望本文能为技术从业者提供清晰的思路,助力多数据库协作的实现与优化。 |



您可能感兴趣的文章 :

-
对postgresql日期和时间的比较
postgresql日期和时间比较 DB里保存到时分秒,需要和年月日比较 1 2 3 select date_trunc(day,now())=date_trunc(day,date(20200615)) --true select date_trunc(day,dat -
PostgreSQL中查看当前时间和日期的几种常用方法
PostgreSQL中查看当前时间和日期 CURRENT_TIMESTAMP CURRENT_TIMESTAMP返回当前的日期和时间,包含时间戳信息,包括时区信息。 1 SELECT CURRENT_TIMESTAMP -
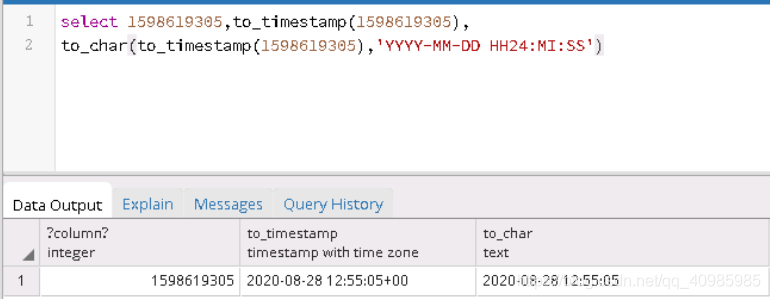
Postgresql之时间戳long,TimeStamp,Date,String互转方式
时间戳long,TimeStamp,Date,String互转 今天遇到一个神奇的问题: Postgre数据库里存的 10位long类型的时间戳,拿Java代码转完的日期年月日时分秒, -
postgresql使用dblink跨库增删改查的详细步骤
postgresql使用dblink跨库增删改查 一、使用步骤 1、创建dblink扩展,连接与被连接的两个数据库都要执行下面sql 1 create extension if not exists dblin -
PostgreSQL中json数据类型介绍
前言 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(European Computer Manufacturers Association, 欧洲计算机协会制定的 -
postgresql使用dblink跨库增删改查的步骤介绍
postgresql使用dblink跨库增删改查 一、使用步骤 1、创建dblink扩展,连接与被连接的两个数据库都要执行下面sql 1 create extension if not exists dblin -
PostgreSQL复制表的5种方法
PostgreSQL 提供了多种不同的复制表的方法,它们的差异在于是否需要复制表结构或者数据。 CREATE TABLE AS SELECT 语句 CREATE TABLE AS SELECT 语句可以 -
postgresql13主从搭建Ubuntu的教程
先安装完数据库以后,安装路径如下: 数据库安装完毕以后, 服务的安装路径为:/usr/lib/postgresql/13/bin/ 数据路径为:/var/lib/postgresql/13/ma -
Postgresql删除数据库表中重复数据的几种方法
一直使用Postgresql数据库,有一张表是这样的: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 DROP TABLE IF EXISTS public.devicedata; CREATE TABLE public.devicedata ( Id varchar(20



-
postgresql使用dblink跨库增删改查的详细
2023-09-30
-
Postgresql之时间戳long,TimeStamp,Date,Stri
2024-02-11
-
在Centos8-stream安装PostgreSQL13的教程
2022-02-26
-
postgresql13主从搭建Ubuntu的教程
2022-11-24
-
PostgreSQL HOT与PHOT有哪些区别
2022-09-22

