ava中的锁主要包括synchronized锁和JUC包中的锁,这些锁都是针对单个JVM实例上的锁,对于分布式环境如果我们需要加锁就显得无能为力。 在单个JVM实例上,锁的竞争者通常是一些不同的线
|
ava中的锁主要包括synchronized锁和JUC包中的锁,这些锁都是针对单个JVM实例上的锁,对于分布式环境如果我们需要加锁就显得无能为力。 在单个JVM实例上,锁的竞争者通常是一些不同的线程,而在分布式环境中,锁的竞争者通常是一些不同的线程或者进程。如何实现在分布式环境中对一个对象进行加锁呢?答案就是分布式锁。 分布式锁实现方案目前分布式锁的实现方案主要包括三种:
基于数据库实现分布式锁:主要是利用数据库的唯一索引来实现,唯一索引天然具有排他性,这刚好符合我们对锁的要求:同一时刻只能允许一个竞争者获取锁。加锁时我们在数据库中插入一条锁记录,利用业务id进行防重。当第一个竞争者加锁成功后,第二个竞争者再来加锁就会抛出唯一索引冲突,如果抛出这个异常,我们就判定当前竞争者加锁失败。防重业务id需要我们自己来定义,例如我们的锁对象是一个方法,则我们的业务防重id就是这个方法的名字,如果锁定的对象是一个类,则业务防重id就是这个类名。 基于缓存实现分布式锁:理论上来说使用缓存来实现分布式锁的效率最高,加锁速度最快,因为Redis几乎都是纯内存操作,而基于数据库的方案和基于Zookeeper的方案都会涉及到磁盘文件IO,效率相对低下。一般使用Redis来实现分布式锁都是利用Redis的SETNX key value这个命令,只有当key不存在时才会执行成功,如果key已经存在则命令执行失败。 基于Zookeeper:Zookeeper一般用作配置中心,其实现分布式锁的原理和Redis类似,我们在Zookeeper中创建瞬时节点,利用节点不能重复创建的特性来保证排他性。 在实现分布式锁的时候我们需要考虑一些问题,例如:分布式锁是否可重入,分布式锁的释放时机,分布式锁服务端是否有单点问题等。 基于数据库实现分布式锁上面已经分析了基于数据库实现分布式锁的基本原理:通过唯一索引保持排他性,加锁时插入一条记录,解锁是删除这条记录。下面我们就简要实现一下基于数据库的分布式锁。 表设计
id字段是数据库的自增id,unique_mutex字段就是我们的防重id,也就是加锁的对象,此对象唯一。在这张表上我们加了一个唯一索引,保证unique_mutex唯一性。holder_id代表竞争到锁的持有者id。 加锁
如果当前sql执行成功代表加锁成功,如果抛出唯一索引异常(DuplicatedKeyException)则代表加锁失败,当前锁已经被其他竞争者获取。 解锁
解锁很简单,直接删除此条记录即可。 分析 是否可重入:就以上的方案来说,我们实现的分布式锁是不可重入的,即是是同一个竞争者,在获取锁后未释放锁之前再来加锁,一样会加锁失败,因此是不可重入的。解决不可重入问题也很简单:加锁时判断记录中是否存在unique_mutex的记录,如果存在且holder_id和当前竞争者id相同,则加锁成功。这样就可以解决不可重入问题。 锁释放时机:设想如果一个竞争者获取锁时候,进程挂了,此时distributed_lock表中的这条记录就会一直存在,其他竞争者无法加锁。为了解决这个问题,每次加锁之前我们先判断已经存在的记录的创建时间和当前系统时间之间的差是否已经超过超时时间,如果已经超过则先删除这条记录,再插入新的记录。另外在解锁时,必须是锁的持有者来解锁,其他竞争者无法解锁。这点可以通过holder_id字段来判定。 数据库单点问题:单个数据库容易产生单点问题:如果数据库挂了,我们的锁服务就挂了。对于这个问题,可以考虑实现数据库的高可用方案,例如MySQL的MHA高可用解决方案。 基于Zookeeper实现分布式锁前置知识: Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。
Znode分为四种类型:
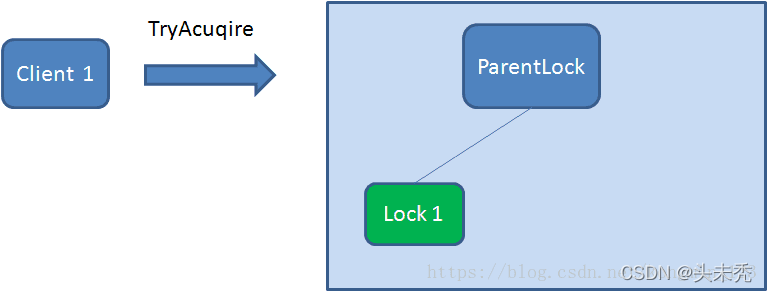
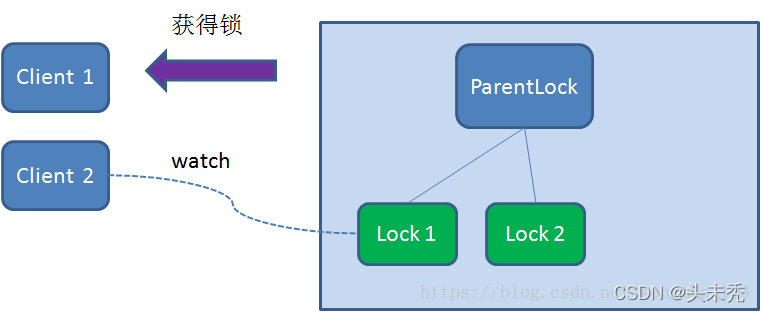
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤: 加锁和解锁流程获取锁 首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
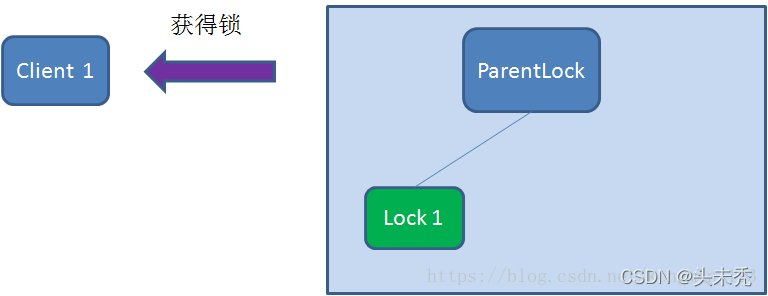
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
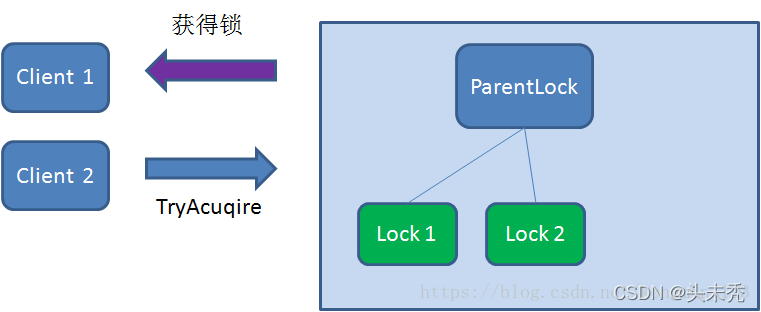
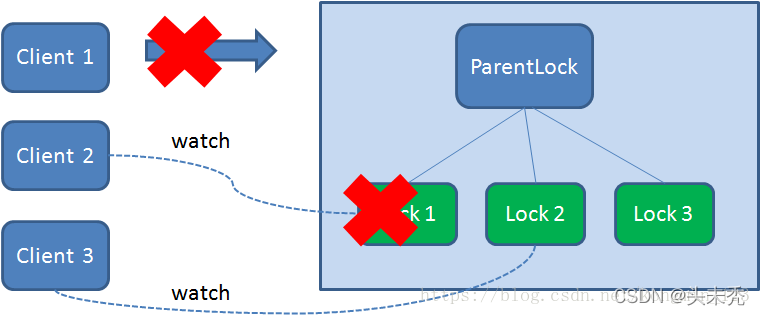
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。 于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。
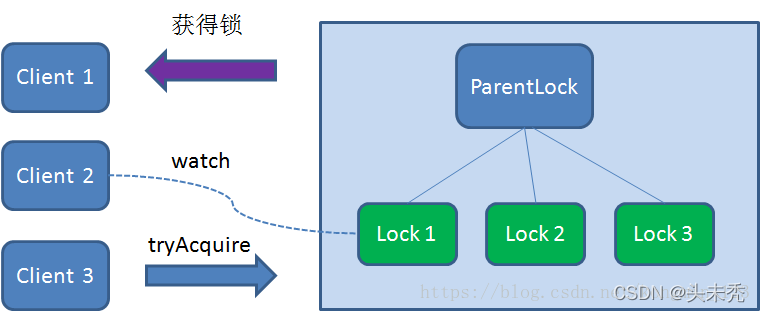
这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock3。
Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。 于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
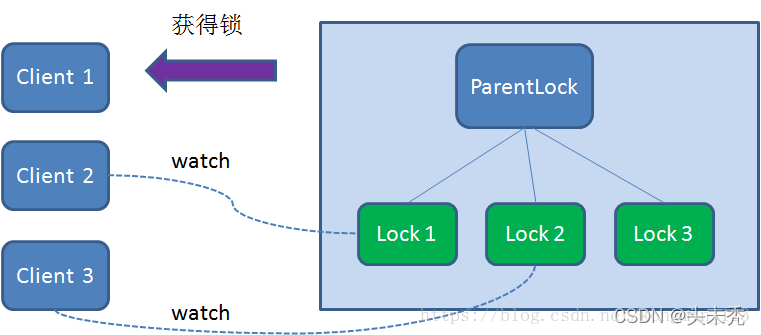
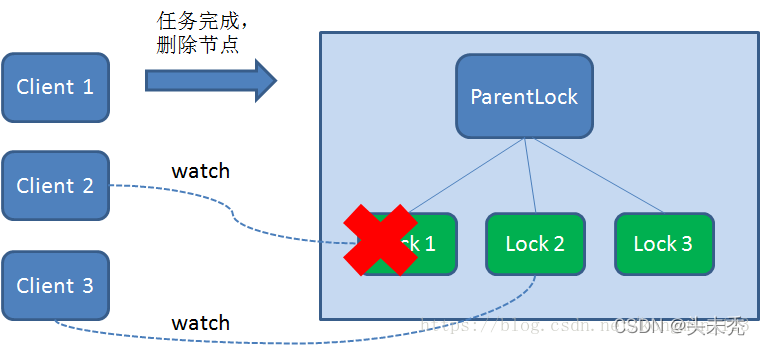
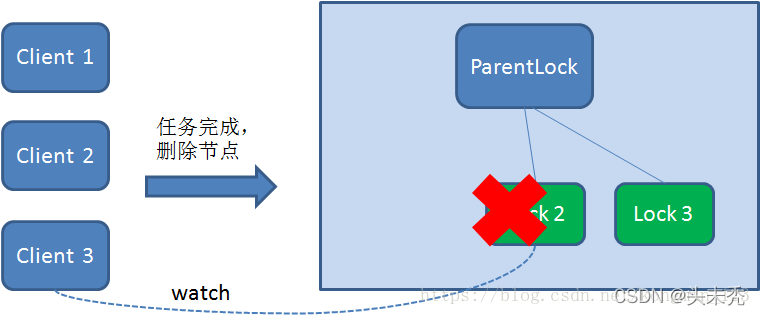
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2。这恰恰形成了一个等待队列,很像是Java当中ReentrantLock(可重入锁)所依赖的AQS(AbstractQueuedSynchronizer)。 获得锁的过程大致就是这样,那么Zookeeper如何释放锁呢? 释放锁的过程很简单,只需要释放对应的子节点就好。 释放锁 释放锁分为两种情况: 1.任务完成,客户端显示释放 当任务完成时,Client1会显示调用删除节点Lock1的指令。
2.任务执行过程中,客户端崩溃 获得锁的Client1在任务执行过程中,如果Duang的一声崩溃,则会断开与Zookeeper服务端的链接。根据临时节点的特性,相关联的节点Lock1会随之自动删除。
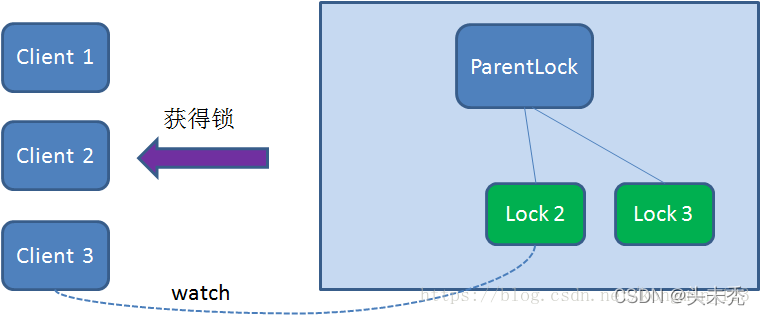
由于Client2一直监听着Lock1的存在状态,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。如果是最小,则Client2顺理成章获得了锁。
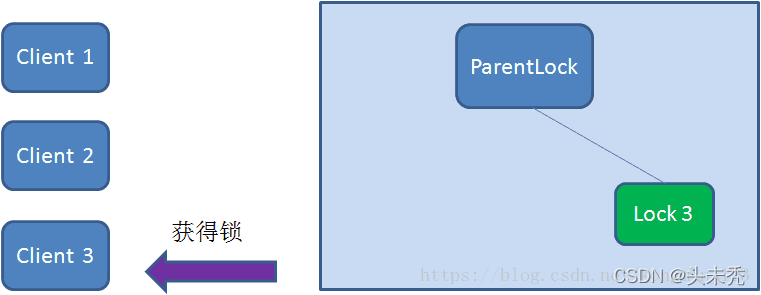
同理,如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Client3就会接到通知。
最终,Client3成功得到了锁。
使用Zookeeper实现分布式锁的大致流程就是这样。 分析 解决不可重入:客户端加锁时将主机和线程信息写入锁中,下一次再来加锁时直接和序列最小的节点对比,如果相同,则加锁成功,锁重入。 锁释放时机:由于我们创建的节点是顺序临时节点,当客户端获取锁成功之后突然session会话断开,ZK会自动删除这个临时节点。 单点问题:ZK是集群部署的,主要一半以上的机器存活,就可以保证服务可用性。 利用curator实现Zookeeper第三方客户端curator中已经实现了基于Zookeeper的分布式锁。利用curator加锁和解锁的代码如下:
最常用的锁:
基于缓存实现分布式锁,以Redis为例加锁
可以看到,我们加锁就一行代码:
这个setIfAbsent()方法一共五个形参:
总的来说,执行上面的setIfAbsent()方法就只会导致两种结果:
解锁
解锁的步骤:
注意到这里解锁其实是分为2个步骤,涉及到解锁操作的一个原子性操作问题。这也是为什么我们解锁的时候用Lua脚本来实现,因为Lua脚本可以保证操作的原子性。那么这里为什么需要保证这两个步骤的操作是原子操作呢? 设想:假设当前锁的持有者是竞争者1,竞争者1来解锁,成功执行第1步,判断自己就是锁持有者,这是还未执行第2步。这是锁过期了,然后竞争者2对这个key进行了加锁。加锁完成后,竞争者1又来执行第2步,此时错误产生了:竞争者1解锁了不属于自己持有的锁。可能会有人问为什么竞争者1执行完第1步之后突然停止了呢?这个问题其实很好回答,例如竞争者1所在的JVM发生了GC停顿,导致竞争者1的线程停顿。这样的情况发生的概率很低,但是请记住即使只有万分之一的概率,在线上环境中完全可能发生。因此必须保证这两个步骤的操作是原子操作。 分析
redis分布式锁,更详细的可以参考:分布式锁(Redisson)原理分析 三种方案比较
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。 |






2021-04-08
2021-10-03
2021-07-26
2019-10-11
2022-08-27