我们目前在工作中遇到一个性能问题,我们有个定时任务需要处理大量的数据,为了提升吞吐量,所以部署了很多台机器,但这个任务在运行前需要从别的服务那拉取大量的数据,随着
|
我们目前在工作中遇到一个性能问题,我们有个定时任务需要处理大量的数据,为了提升吞吐量,所以部署了很多台机器,但这个任务在运行前需要从别的服务那拉取大量的数据,随着数据量的增大,如果同时多台机器并发拉取数据,会对下游服务产生非常大的压力。之前已经增加了单机限流,但无法解决问题,因为这个数据任务运行中只有不到10%的时间拉取数据,如果单机限流限制太狠,虽然集群总的请求量控制住了,但任务吞吐量又降下来。如果限流阈值太高,多机并发的时候,还是有可能压垮下游。 所以目前唯一可行的解决方案就是分布式限流。 我目前是选择直接使用Redisson库中的RRateLimiter实现了分布式限流,关于Redission可能很多人都有所耳闻,它其实是在Redis能力上构建的开发库,除了支持Redis的基础操作外,还封装了布隆过滤器、分布式锁、限流器……等工具。今天要说的RRateLimiter及时其实现的限流器。接下来本文将详细介绍下RRateLimiter的具体使用方式、实现原理还有一些注意事项,最后简单谈谈我对分布式限流底层原理的理解。 RRateLimiter使用RRateLimiter的使用方式异常的简单,参数也不多。只要创建出RedissonClient,就可以从client中获取到RRateLimiter对象,直接看代码示例。
rateLimiter.trySetRate就是设置限流参数,RateType有两种,OVERALL是全局限流 ,PER_CLIENT是单Client限流(可以认为就是单机限流),这里我们只讨论全局模式。而后面三个参数的作用就是设置在多长时间窗口内(rateInterval+IntervalUnit),许可总量不超过多少(rate),上面代码中我设置的值就是1小时内总许可数不超过100个。然后调用rateLimiter的tryAcquire()或者acquire()方法即可获取许可。
使用起来还是很简单的嘛,以上代码中的两种方式都是同步调用,但Redisson还同样提供了异步方法acquireAsync()和tryAcquireAsync(),使用其返回的RFuture就可以异步获取许可。 RRateLimiter的实现接下来我们顺着tryAcquire()方法来看下它的实现方式,在RedissonRateLimiter类中,我们可以看到最底层的tryAcquireAsync()方法。
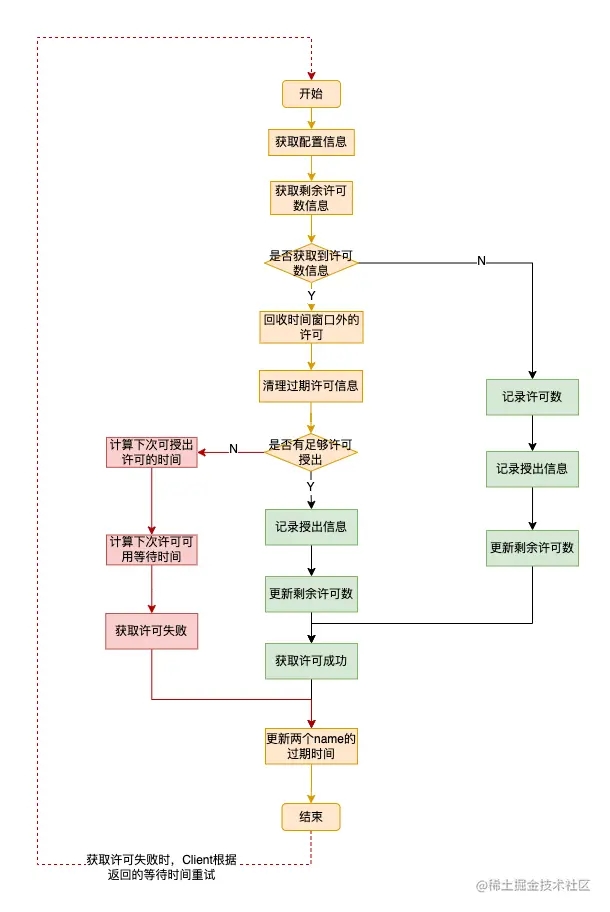
映入眼帘的就是一大段lua代码,其实这段Lua代码就是限流实现的核心,我把这段lua代码摘出来,并加了一些注释,我们来详细看下。
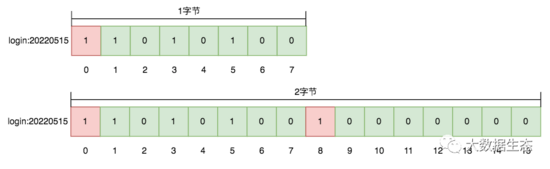
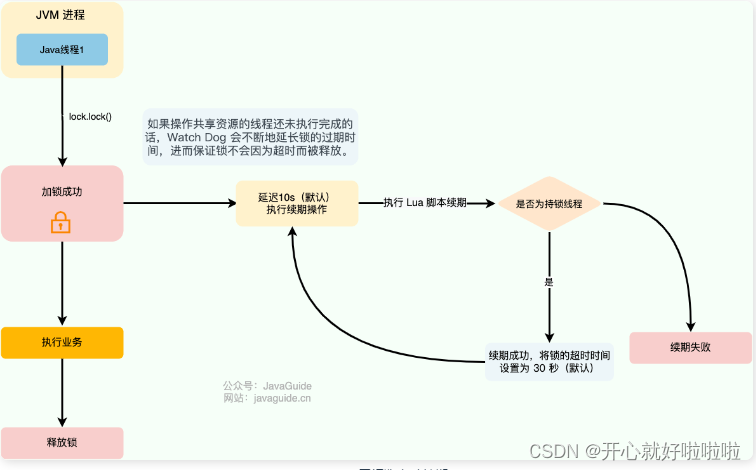
即便是加了注释,相信你还是很难一下子看懂这段代码的,接下来我就以其在Redis中的数据存储形式,然辅以流程图让大家彻底了解其实现实现原理。 首先用RRateLimiter有个name,在我代码中就是xindoo.limiter,用这个作为KEY你就可以在Redis中找到一个map,里面存储了limiter的工作模式(type)、可数量(rate)、时间窗口大小(interval),这些都是在limiter创建时写入到的redis中的,在上面的lua代码中也使用到了。 其次还俩很重要的key,valueName和permitsName,其中在我的代码实现中valueName是{xindoo.limiter}:value ,它存储的是当前可用的许可数量。我代码中permitsName的具体值是{xindoo.limiter}:permits,它是一个zset,其中存储了当前所有的许可授权记录(含有许可授权时间戳),其中SCORE直接使用了时间戳,而VALUE中包含了8字节的随机值和许可的数量,如下图:
{xindoo.limiter}:permits这个zset中存储了所有的历史授权记录,直到了这些信息,相信你也就理解了RRateLimiter的实现原理,我们还是将上面的那大段Lua代码的流程图绘制出来,整个执行的流程会更直观。
看到这大家应该能理解这段Lua代码的逻辑了,可以看到Redis用了多个字段来存储限流的信息,也有各种各样的操作,那Redis是如何保证在分布式下这些限流信息数据的一致性的? 答案是不需要保证,在这个场景下,信息天然就是一致性的。原因是Redis的单进程数据处理模型,在同一个Key下,所有的eval请求都是串行的,所有不需要考虑数据并发操作的问题。在这里,Redisson也使用了HashTag,保证所有的限流信息都存储在同一个Redis实例上。 RRateLimiter使用时注意事项了解了RRateLimiter的底层原理,再结合Redis自身的特性,我想到了RRateLimiter使用的几个局限点(问题点)。 RRateLimiter是非公平限流器这个是我查阅资料得知,并且在自己代码实践的过程中也得到了验证,具体表现就是如果多个实例(机器)取竞争这些许可,很可能某些实例会获取到大部分,而另外一些实例可怜巴巴仅获取到少量的许可,也就是说容易出现旱的旱死 涝的涝死的情况。在使用过程中,你就必须考虑你能否接受这种情况,如果不能接受就得考虑用某些方式尽可能让其变公平。 Rate不要设置太大从RRateLimiter的实现原理你也看出了,它采用的是滑动窗口的模式来限流的,而且记录了所有的许可授权信息,所以如果你设置的Rate值过大,在Redis中存储的信息(permitsName对应的zset)也就越多,每次执行那段lua脚本的性能也就越差,这对Redis实例也是一种压力。个人建议如果你是想设置较大的限流阈值,倾向于小Rate+小时间窗口的方式,而且这种设置方式请求也会更均匀一些。 限流的上限取决于Redis单实例的性能从原理上看,RRateLimiter在Redis上所存储的信息都必须在一个Redis实例上,所以它的限流QPS的上限就是Redis单实例的上限,比如你Redis实例就是1w QPS,你想用RRateLimiter实现一个2w QPS的限流器,必然实现不了。 那有没有突破Redis单实例性能上限的方式?单限流器肯定是实现不了的,我们可以拆分多个限流器,比如我搞10个限流器,名词用不一样的,然后每台机器随机使用一个限流器限流,实际的流量不就被分散到不同的限流器上了吗,总的限流上线不也就上来了。 分布式限流的本质分布式限流的本质实际上就是协同,协同的本质就是信息交换,信息交换最重要的的就是信息的准确性和一致性。 更简单粗暴理解,分布式限流的本质原理其实还是分布式数据一致性的原理,而限流只是数据结果的一种决策。所以只要以任何方式能让信息同步,且保证信息的正确性就可以实现一个分布式限流器了,这就是我理解的本质思路。 其实从上面的RRateLimiter的实现原理也可以看出来,它不就是存储了一些信息吗! 那我不用Redis,而是使用mysql行不行。实际肯定是可以的,只要将的上面Lua代码中的所有操作都放到一个事务里,且事务的级别改成串行化,依旧能实现RRateLimiter同样的功能。如果你具备Mysql相关知识的话,肯定也能基于Mysql将RRateLimiter的API封装出来,但是封装出来的限流器,其限流的上限就取决于Mysql实例的性能上限。 最近chatGPT比较火,我也问了下它对分布式限流本质原理的理解,下面是它的回答,大家觉得怎么样? 分布式限流的本质原理是通过在分布式系统中共享限流状态来限制系统中单位时间内的请求数量,从而避免系统因流量过大而崩溃。 这是通过使用一些共享的存储组件,如数据库,缓存,分布式锁等来实现的。在每次请求时,系统会检查当前的请求数量是否超过了预先设定的限制,如果超过了限制,请求就会被拒绝;如果未超过限制,请求就会被允许。 通过使用分布式限流技术,系统可以在高并发情况下保持稳定的性能,并避免因流量过大而导致的系统崩溃。 |




2021-04-08
2021-10-03
2021-07-26
2019-10-11
2022-08-27