线程锁
主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如Synchronized、Lock等。
进程锁
控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁
什么是分布式锁
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁;一个方法在同一时间只能被一个机器的一个线程执行。
分布式锁应具备的条件
- 多进程可见
- 互斥
- 高可用的获取锁与释放锁;
- 高性能的获取锁与释放锁;
- 具备锁失效机制,防止死锁;
- 具备可重入特性;
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败;
分布式锁常见的实现方式
基于Mysql
在数据库中创建一个表,表中包含方法名等字段,并在方法名name字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入一条记录,成功插入则获取锁,删除对应的行就是锁释放。
|
1
2
3
4
5
6
|
CREATE TABLE `method_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL COMMENT '锁定的方法名',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
|
这里主要是用method_name字段作为唯一索引来实现,唯一索引保证了该记录的唯一性,锁释放就直接删掉该条记录就行了。
|
1
|
INSERT INTO method_lock (method_name) VALUES ('methodName');
|
|
1
|
delete from method_lock where method_name ='methodName';
|
缺点
1、因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能。高并发状态下,数据库读写效率一般都非常缓慢。所以,数据库需要双机部署、数据同步、主备切换;
2、不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;
3、没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁。所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;
4、不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
5、在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。
基于Redis分布式锁
获取锁
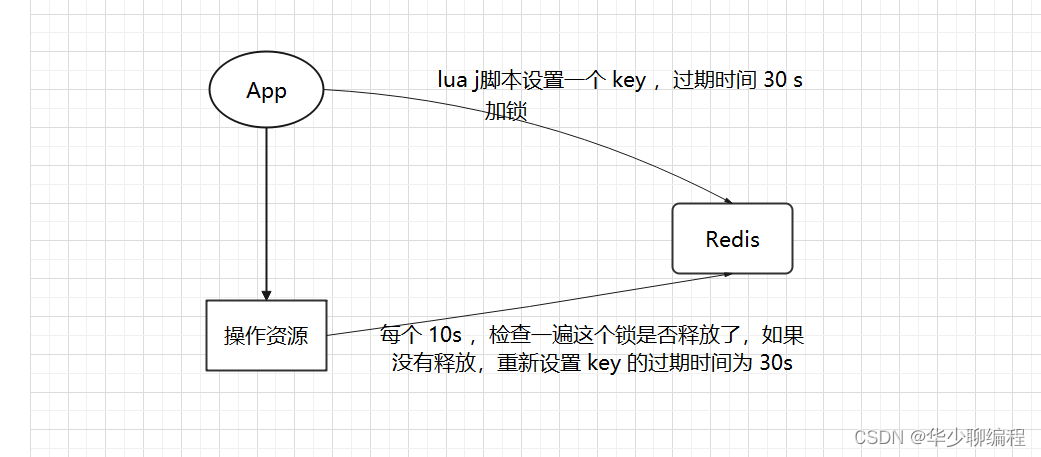
利用setnx这种互斥命令,利用锁超时时间进行到期释放避免死锁,且Redis具有高可用高性能等特点及优势。
Redis 的分布式锁, setnx 命令并设置过期时间就行吗?
|
1
2
|
setnx [key] [value]
expire [key] 30
|
虽然setnx是原子性的,但是setnx + expire就不是了,也就是说setnx和expire是分两步执行的,【加锁和超时】两个操作是分开的,如果expire执行失败了,那么锁同样得不到释放。
获取锁的原子性问题
|
1
2
3
4
5
6
|
# 设置某个 key 的值并设置多少毫秒或秒 过期
set <key> <value> PX <多少毫秒> NX
或
set <key> <value> EX <多少秒> NX
# 设置一个键为lock,值为thread,ex表示以秒为单位,px以微秒为单位,nx表示不存在该key的时候才能设置
set lock thread1 nx ex 10
|
当且仅当key值lock不存在时,set一个key为lock,val为thread1的字符串,返回1;若key存在,则什么都不做,返回0。
Java的实现
|
1
2
3
4
5
6
7
|
public boolean tryLock(long timeoutSec) {
// 获取线程标识,ID_PREFIX为
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁,name为自定义的业务名称
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
|
释放锁
|
1
2
|
# 将对应的键删除即可
del [key]
|
释放错误的锁
假设如下三个线程是同一个用户的业务线程,即假设线程1、线程2、线程3申请的分布式锁key一样:
- 线程1获取成功了一个分布式锁,由于一些问题,线程1执行超时了,分布式锁被超期释放。
- 在锁释放后,有一个线程2又来获取锁,并且成功。
- 在线程2执行过程中,线程1运行结束,由于不知道自己锁已经被超期释放,所以它直接手动释放锁,错误的释放了线程2的锁。
- 这时如果又有一个线程3前来获取锁,就能获取成功;而线程2此时也持有锁。
所以,设置锁的过期时间时,还需要设置唯一编号。在编程实现释放锁的时候,需要判断当前释放的锁的值是否与之前的一致;若一致,则删除;不一致,则不操作。
代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
|
public void unlock() {
// 获取线程标识
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标识
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标识是否一致
if (threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
|
删除锁的原子性问题
- 线程1在时限内完成了业务,它开始执行删除锁的操作。
- 线程1判断完当前锁的标识(对应的value)一样后,由于一些问题,线程1被阻塞,该key超期被删除了
- 线程2过来申请分布式锁,并且成功
- 此时,线程1才正式对分布式锁执行删除,由于可能是同一个用户的业务线程,线程1与线程2的申请的分布式锁key一样,所以线程1调用的删除锁操作将线程2的锁删掉了(悲!故技重施!)…
所以,我们还得确保获取和删除操作之间的原子性。可以借助Lua脚本保证原子性,释放锁的核心逻辑【GET、判断、DEL】,写成 Lua 脚本,让Redis调用。
使用Lua脚本改进Redis释放分布式锁
Lua中Redis的调用函数
|
1
|
redis.call('命令名称','key','其他参数',...)
|
比如我们执行set name jack命令,可以使用:
|
1
|
redis.call('set','name','jack')
|
使用Redis调用Lua脚本
调用方法
|
1
2
|
# script脚本语句;numkeys脚本需要的key类型的参数个数
eval script numkeys key [key ...] arg [arg ...]
|
例如,执行redis.call('set', 'name', 'Jack')脚本设置redis键值,语法如下:
|
1
|
eval "return redis.call('set', 'name', 'Jack')" 0
|
如果key和value不想写死,可以使用如下格式
|
1
|
eval "return redis.call('set', KEYS[1], ARGV[1])" 1 name Jack
|
Lua中,数组下标从1开始,此处1标识只有一个key类型的参数,其他参数都会放入ARGV数组。在脚本中,可以通过KEYS数组和ARGV数组获取参数
Lua脚本(unlock.lua)
|
1
2
3
4
|
if(redis.call('get', KEYS[1]) == ARGV[1]) then
return redis.call('del', KEYS[1])
end
return 0
|
参考完整代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
import cn.hutool.core.lang.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLock {
private String name;
private StringRedisTemplate stringRedisTemplate;
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
// 加载脚本
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
// 加载工程resourcecs下的unlock.lua文件
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);
}
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
public boolean tryLock(long timeoutSec) {
// 获取线程标识
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
public void unlock() {
// 调用Lua脚本
stringRedisTemplate.execute(UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId());
}
}
|
业务调用使用方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
/**
* 业务service导入
*/
@Resource
private RedissonClient redissonClient;
/**
* 业务方法内
*/
SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);
// 创建锁对象
RLock lock = redissonClient.getLock("lock:order:" + userId);
// 尝试获取锁
boolean isLock = lock.tryLock();
// 判断是否成功
if (!isLock) {
// 获取失败
return Result.fail("不允许重复下单");
}
try {
// 需要锁执行的业务代码部分
} finally {
// 释放锁
lock.unlock();
}
|
当前还存在的问题
- 不可重入:同一个线程无法多次获取同一把锁(线程1在执行方法1的时候调用了方法2,而方法2也需要锁)
- 不可重试:获取锁只尝试一次就返回false,没有重试机制;当前直接返回结果。
- 超时释放:锁超时释放虽然可以避免死锁,但是如果业务执行耗时较长,也会导致锁释放,存在安全隐患。
- 主从一致性:如果redis提供了主从集群,主存同步存在延迟。当主结点宕机时,从节点尚未同步主结点锁数据,则会造成锁失效。
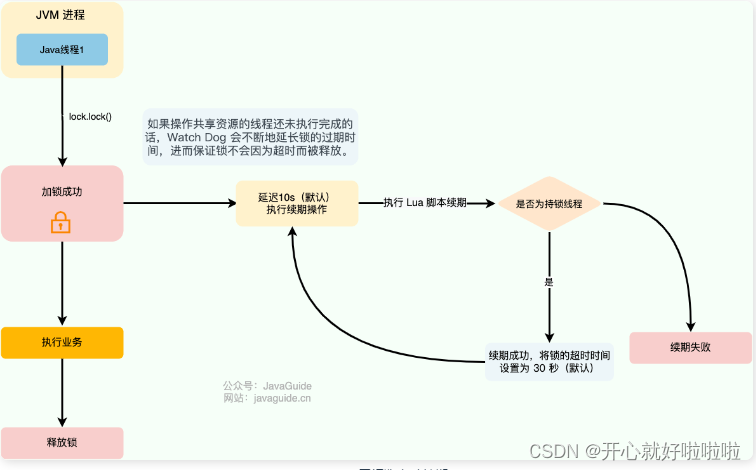
Redisson框架中就实现了WatchDog(看门狗),加锁时没有指定加锁时间时会启用 watchdog 机制,默认加锁 30 秒,每 10 秒钟检查一次,如果存在就重新设置过期时间。
RedLock应对主从一致性问题
Redis 的作者提出一种解决方案 Redlock ,基于多个 Redis 节点,不再需要部署从库和哨兵实例,只部署主库。但主库要部署多个,官方推荐至少 5 个实例。
流程:
-
Client先获取「当前时间戳T1」
-
Client依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
-
如果Client从 >=3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
-
加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
-
加锁失败,Client向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
为什么要向多个Redis申请锁?
向多台Redis申请锁,即使部分服务器异常宕机,剩余的Redis加锁成功,整个锁服务依旧可用。
为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
加锁操作的针对的是分布式中的多个节点,所以耗时肯定是比单个实例耗时更,还要考虑网络延迟、丢包、超时等情况发生,网络请求次数越多,异常的概率越大。
所以即使 N/2+1 个节点加锁成功,但如果加锁的累计耗时已经超过了锁的过期时间,那么此时的锁已经没有意义了
释放锁操作为什么要针对所有结点?
为了清除干净所有的锁。在之前申请锁的操作过程中,锁虽然已经加在Redis上,但是在获取结果的时候,出现网络等方面的问题,导致显示失败。所以在释放锁的时候,不管以前有没有加锁成功,都要释放所有节点相关锁。
Zookeeper
ZooKeeper 的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做 Znode。
-
Client尝试创建一个 znode 节点,比如/lock,比如Client1先到达就创建成功了,相当于拿到了锁
-
其它的客户端会创建失败(znode 已存在),获取锁失败。
-
Client2可以进入一种等待状态,等待当/lock 节点被删除的时候,ZooKeeper 通过 watch 机制通知它
-
持有锁的Client1访问共享资源完成后,将 znode 删掉,锁释放掉了
-
Client2继续完成获取锁操作,直到获取到锁为止
ZooKeeper不需要考虑过期时间,而是用【临时节点】,Client拿到锁之后,只要连接不断,就会一直持有锁。即使Client崩溃,相应临时节点Znode也会自动删除,保证了锁释放。
Zookeeper 是检测客户端是否崩溃
每个客户端都与 ZooKeeper 维护着一个 Session,这个 Session 依赖定期的心跳(heartbeat)来维持。
如果 Zookeeper 长时间收不到客户端的心跳,就认为这个 Session 过期了,也会把这个临时节点删除。
当然这也并不是完美的解决方案
以下场景中Client1和Client2在窗口时间内可能同时获得锁:
-
Client 1 创建了 znode 节点/lock,获得了锁。
-
Client 1 进入了长时间的 GC pause。(或者网络出现问题、或者 zk 服务检测心跳线程出现问题等等)
-
Client 1 连接到 ZooKeeper 的 Session 过期了。znode 节点/lock 被自动删除。
-
Client 2 创建了 znode 节点/lock,从而获得了锁。
-
Client 1 从 GC pause 中恢复过来,它仍然认为自己持有锁。
Zookeeper 的优点
Zookeeper 的缺点
Etcd
Etcd是一个Go语言实现的非常可靠的kv存储系统,常在分布式系统中存储着关键的数据,通常应用在配置中心、服务发现与注册、分布式锁等场景。
Etcd特性
- Lease机制:即租约机制(TTL,Time To Live),etcd可以为存储的kv对设置租约,当租约到期,kv将失效删除;同时也支持续约,keepalive
- Revision机制:每个key带有一个Revision属性值,etcd每进行一次事务对应的全局Revision值都会+1,因此每个key对应的Revision属性值都是全局唯一的。通过比较Revision的大小就可以知道进行写操作的顺序
- 在实现分布式锁时,多个程序同时抢锁,根据Revision值大小依次获得锁,避免“惊群效应”,实现公平锁
- Prefix机制:也称为目录机制,可以根据前缀获得该目录下所有的key及其对应的属性值
- Watch机制:watch支持watch某个固定的key或者一个前缀目录,当watch的key发生变化,客户端将收到通知
满足分布式锁的特性:
- 租约机制(Lease):用于支撑异常情况下的锁自动释放能力
- 前缀和 Revision 机制:用于支撑公平获取锁和排队等待的能力
- 监听机制(Watch):用于支撑抢锁能力
- 集群模式:用于支撑锁服务的高可用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
func main() {
config := clientv3.Config{
Endpoints: []string{"xxx.xxx.xxx.xxx:2379"},
DialTimeout: 5 * time.Second,
}
// 获取客户端连接
client, err := clientv3.New(config)
if err != nil {
fmt.Println(err)
return
}
// 1. 上锁(创建租约,自动续租,拿着租约去抢占一个key )
// 用于申请租约
lease := clientv3.NewLease(client)
// 申请一个10s的租约
leaseGrantResp, err := lease.Grant(context.TODO(), 10) //10s
if err != nil {
fmt.Println(err)
return
}
// 拿到租约的id
leaseID := leaseGrantResp.ID
// 准备一个用于取消续租的context
ctx, cancelFunc := context.WithCancel(context.TODO())
// 确保函数退出后,自动续租会停止
defer cancelFunc()
// 确保函数退出后,租约会失效
defer lease.Revoke(context.TODO(), leaseID)
// 自动续租
keepRespChan, err := lease.KeepAlive(ctx, leaseID)
if err != nil {
fmt.Println(err)
return
}
// 处理续租应答的协程
go func() {
select {
case keepResp := <-keepRespChan:
if keepRespChan == nil {
fmt.Println("lease has expired")
goto END
} else {
// 每秒会续租一次
fmt.Println("收到自动续租应答", keepResp.ID)
}
}
END:
}()
// if key 不存在,then设置它,else抢锁失败
kv := clientv3.NewKV(client)
// 创建事务
txn := kv.Txn(context.TODO())
// 如果key不存在
txn.If(clientv3.Compare(clientv3.CreateRevision("/cron/lock/job7"), "=", 0)).
Then(clientv3.OpPut("/cron/jobs/job7", "", clientv3.WithLease(leaseID))).
Else(clientv3.OpGet("/cron/jobs/job7")) //如果key存在
// 提交事务
txnResp, err := txn.Commit()
if err != nil {
fmt.Println(err)
return
}
// 判断是否抢到了锁
if !txnResp.Succeeded {
fmt.Println("锁被占用了:", string(txnResp.Responses[0].GetResponseRange().Kvs[0].Value))
return
}
// 2. 处理业务(锁内,很安全)
fmt.Println("处理任务")
time.Sleep(5 * time.Second)
// 3. 释放锁(取消自动续租,释放租约)
// defer会取消续租,释放锁
}
|
clientv3提供的concurrency包也实现了分布式锁
- 首先concurrency.NewSession方法创建Session对象
- 然后Session对象通过concurrency.NewMutex 创建了一个Mutex对象
- 加锁和释放锁分别调用Lock和UnLock
笔记Zookeeper和Etcd部分参考:https://mp.weixin.qq.com/s/wL9MRnx8HVXNFOt6ZTWELw
线程锁
主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如Synchronized、Lock等。
进程锁
控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁
什么是分布式锁
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁;一个方法在同一时间只能被一个机器的一个线程执行。
分布式锁应具备的条件
- 多进程可见
- 互斥
- 高可用的获取锁与释放锁;
- 高性能的获取锁与释放锁;
- 具备锁失效机制,防止死锁;
- 具备可重入特性;
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败;
分布式锁常见的实现方式
基于Mysql
在数据库中创建一个表,表中包含方法名等字段,并在方法名name字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入一条记录,成功插入则获取锁,删除对应的行就是锁释放。
|
1
2
3
4
5
6
|
CREATE TABLE `method_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL COMMENT '锁定的方法名',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
|
这里主要是用method_name字段作为唯一索引来实现,唯一索引保证了该记录的唯一性,锁释放就直接删掉该条记录就行了。
|
1
|
INSERT INTO method_lock (method_name) VALUES ('methodName');
|
|
1
|
delete from method_lock where method_name ='methodName';
|
缺点
1、因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能。高并发状态下,数据库读写效率一般都非常缓慢。所以,数据库需要双机部署、数据同步、主备切换;
2、不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;
3、没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁。所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;
4、不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
5、在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。
基于Redis分布式锁
获取锁
利用setnx这种互斥命令,利用锁超时时间进行到期释放避免死锁,且Redis具有高可用高性能等特点及优势。
Redis 的分布式锁, setnx 命令并设置过期时间就行吗?
|
1
2
|
setnx [key] [value]
expire [key] 30
|
虽然setnx是原子性的,但是setnx + expire就不是了,也就是说setnx和expire是分两步执行的,【加锁和超时】两个操作是分开的,如果expire执行失败了,那么锁同样得不到释放。
获取锁的原子性问题
|
1
2
3
4
5
6
|
# 设置某个 key 的值并设置多少毫秒或秒 过期
set <key> <value> PX <多少毫秒> NX
或
set <key> <value> EX <多少秒> NX
# 设置一个键为lock,值为thread,ex表示以秒为单位,px以微秒为单位,nx表示不存在该key的时候才能设置
set lock thread1 nx ex 10
|
当且仅当key值lock不存在时,set一个key为lock,val为thread1的字符串,返回1;若key存在,则什么都不做,返回0。
Java的实现
|
1
2
3
4
5
6
7
|
public boolean tryLock(long timeoutSec) {
// 获取线程标识,ID_PREFIX为
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁,name为自定义的业务名称
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
|
释放锁
|
1
2
|
# 将对应的键删除即可
del [key]
|
释放错误的锁
假设如下三个线程是同一个用户的业务线程,即假设线程1、线程2、线程3申请的分布式锁key一样:
- 线程1获取成功了一个分布式锁,由于一些问题,线程1执行超时了,分布式锁被超期释放。
- 在锁释放后,有一个线程2又来获取锁,并且成功。
- 在线程2执行过程中,线程1运行结束,由于不知道自己锁已经被超期释放,所以它直接手动释放锁,错误的释放了线程2的锁。
- 这时如果又有一个线程3前来获取锁,就能获取成功;而线程2此时也持有锁。
所以,设置锁的过期时间时,还需要设置唯一编号。在编程实现释放锁的时候,需要判断当前释放的锁的值是否与之前的一致;若一致,则删除;不一致,则不操作。
代码示例:
|
1
2
3
4
5
6
7
8
9
10
11
|
public void unlock() {
// 获取线程标识
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标识
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标识是否一致
if (threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
|
删除锁的原子性问题
- 线程1在时限内完成了业务,它开始执行删除锁的操作。
- 线程1判断完当前锁的标识(对应的value)一样后,由于一些问题,线程1被阻塞,该key超期被删除了
- 线程2过来申请分布式锁,并且成功
- 此时,线程1才正式对分布式锁执行删除,由于可能是同一个用户的业务线程,线程1与线程2的申请的分布式锁key一样,所以线程1调用的删除锁操作将线程2的锁删掉了(悲!故技重施!)…
所以,我们还得确保获取和删除操作之间的原子性。可以借助Lua脚本保证原子性,释放锁的核心逻辑【GET、判断、DEL】,写成 Lua 脚本,让Redis调用。
使用Lua脚本改进Redis释放分布式锁
Lua中Redis的调用函数
|
1
|
redis.call('命令名称','key','其他参数',...)
|
比如我们执行set name jack命令,可以使用:
|
1
|
redis.call('set','name','jack')
|
使用Redis调用Lua脚本
调用方法
|
1
2
|
# script脚本语句;numkeys脚本需要的key类型的参数个数
eval script numkeys key [key ...] arg [arg ...]
|
例如,执行redis.call('set', 'name', 'Jack')脚本设置redis键值,语法如下:
|
1
|
eval "return redis.call('set', 'name', 'Jack')" 0
|
如果key和value不想写死,可以使用如下格式
|
1
|
eval "return redis.call('set', KEYS[1], ARGV[1])" 1 name Jack
|
Lua中,数组下标从1开始,此处1标识只有一个key类型的参数,其他参数都会放入ARGV数组。在脚本中,可以通过KEYS数组和ARGV数组获取参数
Lua脚本(unlock.lua)
|
1
2
3
4
|
if(redis.call('get', KEYS[1]) == ARGV[1]) then
return redis.call('del', KEYS[1])
end
return 0
|
参考完整代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
import cn.hutool.core.lang.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import java.util.Collections;
import java.util.concurrent.TimeUnit;
public class SimpleRedisLock {
private String name;
private StringRedisTemplate stringRedisTemplate;
private static final String KEY_PREFIX = "lock:";
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
// 加载脚本
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
// 加载工程resourcecs下的unlock.lua文件
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);
}
public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) {
this.name = name;
this.stringRedisTemplate = stringRedisTemplate;
}
public boolean tryLock(long timeoutSec) {
// 获取线程标识
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
public void unlock() {
// 调用Lua脚本
stringRedisTemplate.execute(UNLOCK_SCRIPT,
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId());
}
}
|
业务调用使用方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
/**
* 业务service导入
*/
@Resource
private RedissonClient redissonClient;
/**
* 业务方法内
*/
SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);
// 创建锁对象
RLock lock = redissonClient.getLock("lock:order:" + userId);
// 尝试获取锁
boolean isLock = lock.tryLock();
// 判断是否成功
if (!isLock) {
// 获取失败
return Result.fail("不允许重复下单");
}
try {
// 需要锁执行的业务代码部分
} finally {
// 释放锁
lock.unlock();
}
|
当前还存在的问题
- 不可重入:同一个线程无法多次获取同一把锁(线程1在执行方法1的时候调用了方法2,而方法2也需要锁)
- 不可重试:获取锁只尝试一次就返回false,没有重试机制;当前直接返回结果。
- 超时释放:锁超时释放虽然可以避免死锁,但是如果业务执行耗时较长,也会导致锁释放,存在安全隐患。
- 主从一致性:如果redis提供了主从集群,主存同步存在延迟。当主结点宕机时,从节点尚未同步主结点锁数据,则会造成锁失效。
Redisson框架中就实现了WatchDog(看门狗),加锁时没有指定加锁时间时会启用 watchdog 机制,默认加锁 30 秒,每 10 秒钟检查一次,如果存在就重新设置过期时间。
RedLock应对主从一致性问题
Redis 的作者提出一种解决方案 Redlock ,基于多个 Redis 节点,不再需要部署从库和哨兵实例,只部署主库。但主库要部署多个,官方推荐至少 5 个实例。
流程:
-
Client先获取「当前时间戳T1」
-
Client依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
-
如果Client从 >=3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
-
加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
-
加锁失败,Client向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
为什么要向多个Redis申请锁?
向多台Redis申请锁,即使部分服务器异常宕机,剩余的Redis加锁成功,整个锁服务依旧可用。
为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
加锁操作的针对的是分布式中的多个节点,所以耗时肯定是比单个实例耗时更,还要考虑网络延迟、丢包、超时等情况发生,网络请求次数越多,异常的概率越大。
所以即使 N/2+1 个节点加锁成功,但如果加锁的累计耗时已经超过了锁的过期时间,那么此时的锁已经没有意义了
释放锁操作为什么要针对所有结点?
为了清除干净所有的锁。在之前申请锁的操作过程中,锁虽然已经加在Redis上,但是在获取结果的时候,出现网络等方面的问题,导致显示失败。所以在释放锁的时候,不管以前有没有加锁成功,都要释放所有节点相关锁。
Zookeeper
ZooKeeper 的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做 Znode。
-
Client尝试创建一个 znode 节点,比如/lock,比如Client1先到达就创建成功了,相当于拿到了锁
-
其它的客户端会创建失败(znode 已存在),获取锁失败。
-
Client2可以进入一种等待状态,等待当/lock 节点被删除的时候,ZooKeeper 通过 watch 机制通知它
-
持有锁的Client1访问共享资源完成后,将 znode 删掉,锁释放掉了
-
Client2继续完成获取锁操作,直到获取到锁为止
ZooKeeper不需要考虑过期时间,而是用【临时节点】,Client拿到锁之后,只要连接不断,就会一直持有锁。即使Client崩溃,相应临时节点Znode也会自动删除,保证了锁释放。
Zookeeper 是检测客户端是否崩溃
每个客户端都与 ZooKeeper 维护着一个 Session,这个 Session 依赖定期的心跳(heartbeat)来维持。
如果 Zookeeper 长时间收不到客户端的心跳,就认为这个 Session 过期了,也会把这个临时节点删除。
当然这也并不是完美的解决方案
以下场景中Client1和Client2在窗口时间内可能同时获得锁:
-
Client 1 创建了 znode 节点/lock,获得了锁。
-
Client 1 进入了长时间的 GC pause。(或者网络出现问题、或者 zk 服务检测心跳线程出现问题等等)
-
Client 1 连接到 ZooKeeper 的 Session 过期了。znode 节点/lock 被自动删除。
-
Client 2 创建了 znode 节点/lock,从而获得了锁。
-
Client 1 从 GC pause 中恢复过来,它仍然认为自己持有锁。
Zookeeper 的优点
Zookeeper 的缺点
Etcd
Etcd是一个Go语言实现的非常可靠的kv存储系统,常在分布式系统中存储着关键的数据,通常应用在配置中心、服务发现与注册、分布式锁等场景。
Etcd特性
- Lease机制:即租约机制(TTL,Time To Live),etcd可以为存储的kv对设置租约,当租约到期,kv将失效删除;同时也支持续约,keepalive
- Revision机制:每个key带有一个Revision属性值,etcd每进行一次事务对应的全局Revision值都会+1,因此每个key对应的Revision属性值都是全局唯一的。通过比较Revision的大小就可以知道进行写操作的顺序
- 在实现分布式锁时,多个程序同时抢锁,根据Revision值大小依次获得锁,避免“惊群效应”,实现公平锁
- Prefix机制:也称为目录机制,可以根据前缀获得该目录下所有的key及其对应的属性值
- Watch机制:watch支持watch某个固定的key或者一个前缀目录,当watch的key发生变化,客户端将收到通知
满足分布式锁的特性:
- 租约机制(Lease):用于支撑异常情况下的锁自动释放能力
- 前缀和 Revision 机制:用于支撑公平获取锁和排队等待的能力
- 监听机制(Watch):用于支撑抢锁能力
- 集群模式:用于支撑锁服务的高可用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
func main() {
config := clientv3.Config{
Endpoints: []string{"xxx.xxx.xxx.xxx:2379"},
DialTimeout: 5 * time.Second,
}
// 获取客户端连接
client, err := clientv3.New(config)
if err != nil {
fmt.Println(err)
return
}
// 1. 上锁(创建租约,自动续租,拿着租约去抢占一个key )
// 用于申请租约
lease := clientv3.NewLease(client)
// 申请一个10s的租约
leaseGrantResp, err := lease.Grant(context.TODO(), 10) //10s
if err != nil {
fmt.Println(err)
return
}
// 拿到租约的id
leaseID := leaseGrantResp.ID
// 准备一个用于取消续租的context
ctx, cancelFunc := context.WithCancel(context.TODO())
// 确保函数退出后,自动续租会停止
defer cancelFunc()
// 确保函数退出后,租约会失效
defer lease.Revoke(context.TODO(), leaseID)
// 自动续租
keepRespChan, err := lease.KeepAlive(ctx, leaseID)
if err != nil {
fmt.Println(err)
return
}
// 处理续租应答的协程
go func() {
select {
case keepResp := <-keepRespChan:
if keepRespChan == nil {
fmt.Println("lease has expired")
goto END
} else {
// 每秒会续租一次
fmt.Println("收到自动续租应答", keepResp.ID)
}
}
END:
}()
// if key 不存在,then设置它,else抢锁失败
kv := clientv3.NewKV(client)
// 创建事务
txn := kv.Txn(context.TODO())
// 如果key不存在
txn.If(clientv3.Compare(clientv3.CreateRevision("/cron/lock/job7"), "=", 0)).
Then(clientv3.OpPut("/cron/jobs/job7", "", clientv3.WithLease(leaseID))).
Else(clientv3.OpGet("/cron/jobs/job7")) //如果key存在
// 提交事务
txnResp, err := txn.Commit()
if err != nil {
fmt.Println(err)
return
}
// 判断是否抢到了锁
if !txnResp.Succeeded {
fmt.Println("锁被占用了:", string(txnResp.Responses[0].GetResponseRange().Kvs[0].Value))
return
}
// 2. 处理业务(锁内,很安全)
fmt.Println("处理任务")
time.Sleep(5 * time.Second)
// 3. 释放锁(取消自动续租,释放租约)
// defer会取消续租,释放锁
}
|
clientv3提供的concurrency包也实现了分布式锁
- 首先concurrency.NewSession方法创建Session对象
- 然后Session对象通过concurrency.NewMutex 创建了一个Mutex对象
- 加锁和释放锁分别调用Lock和UnLock
笔记Zookeeper和Etcd部分参考:https://mp.weixin.qq.com/s/wL9MRnx8HVXNFOt6ZTWELw