
Redis内存碎片率调优处理方式

1.背景概述 在生产环境中Redis Cluster集群触发了内存碎片化的告警(碎片率1.5),集群节点分布三台宿主机六个节点三主三从架构,Redis版本是6.2.X。 2.redis内存碎片的形成 内存碎片形成的原因主
1.背景概述在生产环境中Redis Cluster集群触发了内存碎片化的告警(碎片率>1.5),集群节点分布三台宿主机六个节点三主三从架构,Redis版本是6.2.X。 2.redis内存碎片的形成内存碎片形成的原因主要有2点:
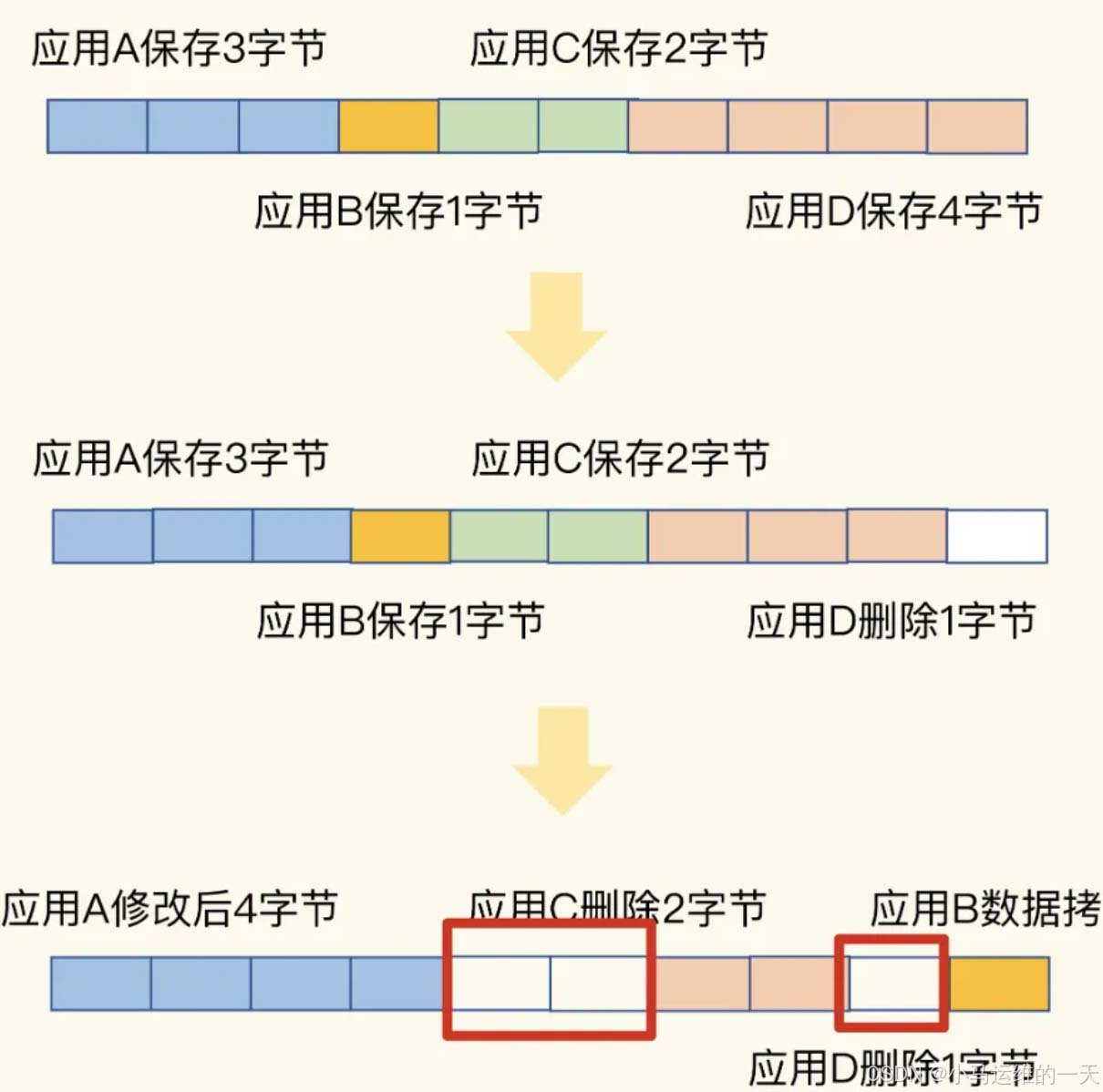
内因: 内存分配器会按照固定大小来分配内存,而不是按需分配。例如Linux下默认是4KB,开启内存大页机制后就变成2MB。 Redis中使用jemalloc分配器来分配内存。它会按照一系列固定大小的内存来进行分配。例如当Redis中需要申请一个20B大小的空间来保存数据,那么jemalloc分配器就会分配32B: 倘若此时应用还要写入5B大小的数据,那么无需申请额外的空间。 倘若此时应用还要写入20B大小的数据,那么必须在申请额外的空间了,此时就会有产生内存碎片的风险(之前分配的32B中,10B就是内存碎片了) 外因: 我们有一个Redis实例,里面有着不同大小的键值对,那么根据内存分配器的分配机制来看。就有可能分配着不同大小的连续内存空间。 另一方面,我们对键值对也有可能有着不同的操作,增删改查。 如图所示
上图中,白色部分的就是内存碎片,可以看出大小不一的键值对以及修改删除操作导致产生了内存碎片。 3.清理内存碎片清理内存碎片之前,首先应该做的就是判断是否有内存碎片: 我们可以登录Redis后使用INFO MEMORY命令查看。mem_fragmentation_ratio参数的值就是内存碎片化的值。 mem_fragmentation_ratio代表Redis实例当前的内存碎片率。其计算公式为:
针对mem_fragmentation_ratio,有两个参考:
那么如何清理内存碎片呢(一般不会重启实例,因为生产上往往不允许这种神操作出现),在Redis4.0版本以后,Redis提供了内置的内存碎片清理机制。
以上参数可根据主机资源配置及应用场景自行调整。 除此之外,值得注意的是,虽然Redis提供了这样的自动内存清理机制,能够带来清理内存碎片的好处,但是与此同时的必定有着其对应的牺牲,也就是性能影响问题。 Redis提供了内置的内存碎片清理机制的使用前提是在编译的过程中添加了内存分配器参数MALLOC=jemalloc
4.扩展当然我们在生产环境使用Redis过程中也可以使用自带的命令进行内存使用情况的诊断,便于我们及时对问题进行优化处理。 我们可以使用MEMORY help查看:
MEMORY STATSredis的内存使用不只包含全部的key-value数据,还有描述这些key-value的元信息,以及许多管理功能的消耗,好比持久化、主从复制,经过MEMORY STATS能够更好的了解到redis的内存使用情况
一共有15项内容,内存使用量均以字节为单位 1. peak.allocated redis启动到如今,最多使用过多少内存。 2. total.allocated 当前使用的内存总量。 3. startup.allocated redis启动初始化时使用的内存,有不少读者会比较奇怪,为何个人redis启动之后什么都没作就已经占用了几十MB的内存? 这是由于redis自己不只存储key-value,还有其余的内存消耗,好比共享变量、主从复制、持久化和db元信息,下面各项会有详细介绍。 4. replication.backlog 主从复制backlog使用的内存,默认10MB,backlog只在主从断线重连时发挥做用,主从复制自己并不依赖此项。 5. clients.slaves 主从复制中全部slave的读写缓冲区,包括output-buffer(也即输出缓冲区)使用的内存和querybuf(也即输入缓冲区),这里简单介绍一下主从复制:app redis把一次事件循环中,全部对数据库发生更改的内容先追加到slave的output-buffer中,在事件循环结束后统一发送给slave。 那么主从之间就不免会有数据的延迟,若是主从之间链接断开,重连时为了保证数据的一致性就要作一次全量同步,这显然是不够高效的。 backlog就是为此而设计,master在backlog中缓存一部分主从复制的增量数据,断线重连时若是slave的偏移量在backlog中,那就能够只把偏移量以后的增量数据同步给slave便可,避免了全量同步的开销。 6. clients.normal 除slave外全部其余客户端的读写缓冲区。 有时候一些客户端读取不及时,就会形成output-buffer积压占用内存过多的状况,能够经过配置项client-output-buffer-limit来限制,当超过阈值以后redis就会主动断开链接以释放内存,slave亦是如此。 7. aof.buffer 此项为aof持久化使用的缓存和aofrewrite时产生的缓存之和,固然若是关闭了appendonly那这项就一直为0:less redis并非在有写入时就当即作持久化的,而是在一次事件循环内把全部的写入数据缓存起来,待到事件循环结束后再持久化到磁盘。 aofrewrite时缓存增量数据使用的内存,只在aofrewrite时才会使用。 能够看出这一项的大小与写入流量成正比。ide 8. db.0 redis每一个db的元信息使用的内存,这里只使用了db0,因此只打印了db0的内存使用状态,当使用其余db时也会有相应的信息。优化 db的元信息有如下三项:
overhead.hashtable.main: db的元信息也便是以上三项之和,计算公式为: hashtable + dictEntry + redisObject overhead.hashtable.expires: 对于key的过时时间,redis并无把它和value放在一块儿,而是单独用一个hashtable来存储,可是expires这张hash表记录的是key-expire信息,因此不须要`redisObject`来描述value,其元信息也就少了一项,计算公式为: hashtable + dictEntry 9. overhead.total 3-8项之和:startup.allocated+replication.backlog+clients.slaves+clients.normal+aof.buffer+dbx 10. dataset.bytes 全部数据所使用的内存——也即total.allocated - overhead.total——当前内存使用量减去管理类内存使用量。 11. dataset.percentage 全部数据占比,这里并无直接使用total.allocated作分母,而是除去了redis启动初始化的内存,计算公式为: 100 * dataset.bytes / (total.allocated - startup.allocated) 12. keys.count redis当前存储的key总量 13. keys.bytes-per-key 平均每一个key的内存大小,直觉上应该是用dataset.bytes除以keys.count便可,可是redis并无这么作,而是把管理类内存也平摊到了每一个key的内存使用中,计算公式为: (total.allocated - startup.allocated) / keys.count 14. peak.percentage 当前使用内存与历史最高值比例 15. fragmentation 内存碎片率 MEMORY USAGE使用方法:MEMORY USAGE <key> [SAMPLES <count>] 命令参数很少,经过字面意思也能够看出来是评估指定key的内存使用状况。samples是可选参数默认为5,以hash为例看下:
首先相似于上一节中的overhead.hashtable.main,要计算hash的元信息内存,包括hash表的大小以及全部dictEntry的内存占用信息。 与overhead.hashtable.main不一样的是,每一个dictEntry中key-value都是字符串,因此没redisObject的额外消耗。 在评估真正的数据内存大小时redis并无去遍历全部key,而是采用的抽样估算:随机抽取samples个key-value对计算其平均内存占用,再乘以key-value对的个数即获得结果。 试想一下若是要精确计算内存占用,那么就须要遍历全部的元素,当元素不少时就是使redis阻塞,因此请合理设置samples的大小。 其余数据结构的计算方式相似于hash,此处就再也不赘述。 MEMORY DOCTOR此项子命令是做者给出的关于redis内存使用方面的建议,在不一样的容许状态下会有不一样的分析结果。 首先是没问题的状况 运行状态良好
内存使用峰值1.5倍于目前内存使用量,此时内存碎片率可能会比较高,须要注意:
内存碎片率太高超过1.4,须要注意:
MEMORY MALLOC-STATS打印内存分配器状态,只在使用jemalloc时有用。 MEMORY PURGE请求分配器释放内存,只对jemalloc生效。 |
您可能感兴趣的文章 :

-
Redis数据类型Streams的介绍
Redis Streams 是 Redis 5.0 引入的一种新的数据类型,它提供了一种强大的日志结构化数据存储方式。Streams 类型非常适合用于构建消息队列、事 -
Redis怎么处理Hash冲突
在 Redis 中,哈希表是一种常见的数据结构,通常用于存储对象的属性,对于哈希表,最常遇到的是哈希冲突,那么,当 Redis遇到Hash冲突会如 -
Redis实现分布式锁时需要考虑的问题解决方案
分布式系统中的多个节点经常需要对共享资源进行并发访问,若没有有效的协调机制,可能会导致数据竞争、资源冲突等问题。分布式锁应 -
Redis连接池监控(连接池是否已满)与优化方法
Redis作为一个高性能的内存数据库,广泛应用于各类高并发场景中。然而,在使用Redis时,连接池的管理至关重要,特别是在高并发应用中, -

Redis在Ubuntu系统上的安装步骤
1. 先切换到 root 用户 在 Ubuntu 20.04 中,可以通过以下步骤切换到 root 用户: 输入以下命令,以 root 用户身份登录: 1 sudo su - 按回车键,并输 -
redis生成全局id的实现步骤
使用redis生成全局id 在现代软件开发中,生成全局唯一的标识符是非常常见的需求。这些全局唯一ID在分布式系统中尤其重要,用于标识各种 -
Redis分布式锁及4种常见实现方法
线程锁 主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有



-
解决redis sentinel频繁主备切换的问题
2021-04-08
-
Redis三种集群模式介绍
2021-10-03
-
Redis内存碎片率调优处理方式
2024-09-30
-
springboot使用Redis作缓存使用教程
2021-07-26
-
异步redis队列实现 数据入库的方法
2019-10-11

