
Redis数据一致性的介绍

1、一致性 一致性是指系统中各节点数据保持一致。分布式系统中,可以理解为多个节点中的数据是一致的。 一致性根据严苛程度分类: 强一致性:写进去的数据是什么,读出来的数据就是什
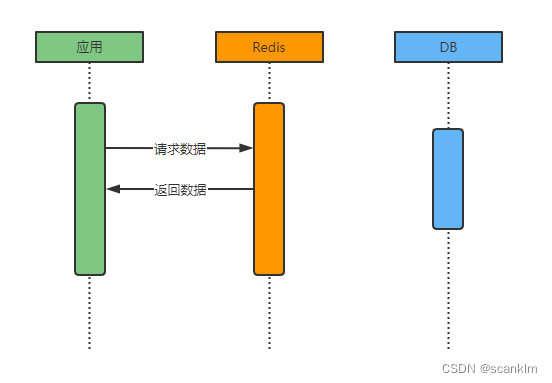
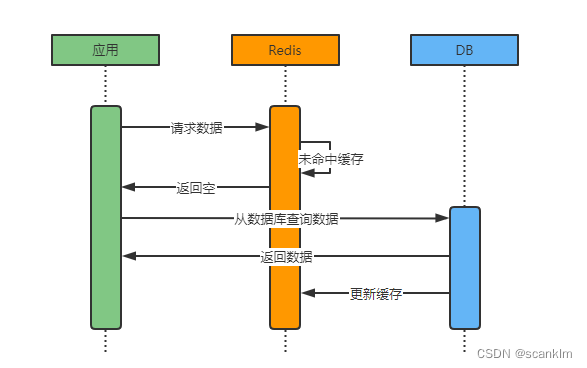
1、一致性一致性是指系统中各节点数据保持一致。分布式系统中,可以理解为多个节点中的数据是一致的。 一致性根据严苛程度分类: 强一致性:写进去的数据是什么,读出来的数据就是什么,对性能影响最大; 弱一致性:数据写入成功后,系统不保证能立刻读出最新的数据,也不承诺多久之后数据可以达到一致,但保证到某个时间级别后,数据能达到一致; 最终一致性:最终一致性是弱一致性的一个特例,最终一致性同样只保证数据写入成功后,在某个时间点后数据会达到一致。这个系统无法保证强一致性的时间片段被称为不一致窗口。不一致时间窗口的时间长短取决于很多因素,比如副本个数、网络延迟、系统负载等。 最终一致性是弱一致性中非常受大众推崇的一种一致性模型,也是目前业界在大型分布式系统的数据一致性上比较推崇的模型。 2、缓存使用场景对于大部分系统而言,高并发常见于读数据的场景,对于此场景我们可以使用缓存提升数据查询速度。当我们使用Redis作缓存的时候,常见场景如下所示: 缓存存在 如果数据在缓存中存在,则直接从缓存返回数据至应用,无需查询数据库
缓存不存在 如果数据在缓存中不存在,则需查询数据库获取数据并更新缓存。
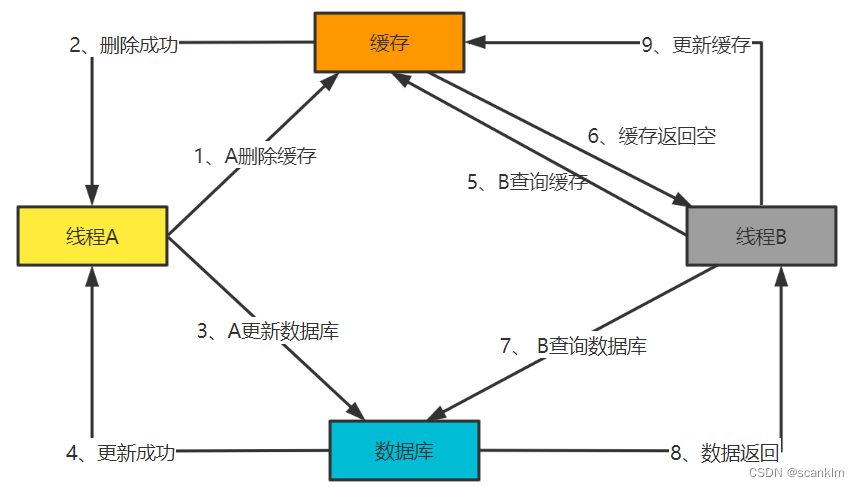
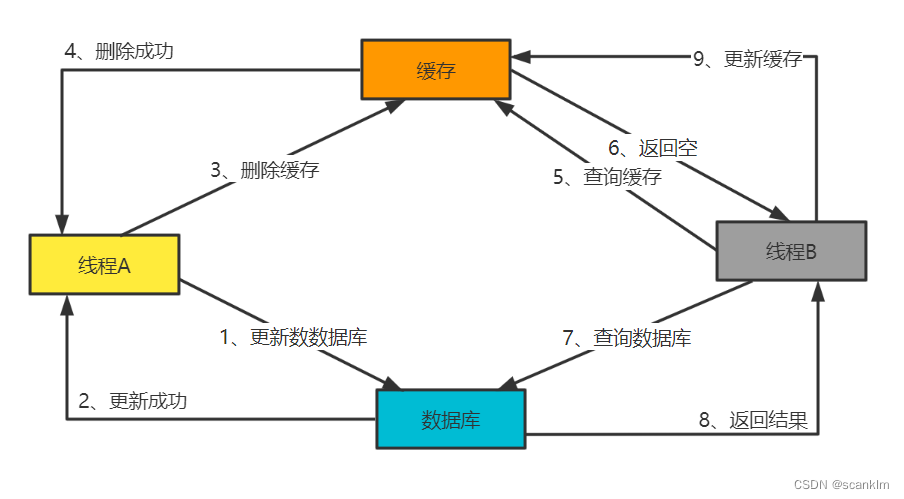
对于大部分系统而言最终数据都会存储在数据库中,也就是系统需已数据库中数据为准,那么对于上图缓存存在的场景下,当数据库中的数据发生变化时,就可能会出现数据不一致的问题。 实际情况下考虑网络、操作、异常等种种因素,根本无法保证可以同时更新所有副本数据使得数据保持一致。因此,如何在最大程度上保证各副本数据一致的同时也不影响系统性能,成了各系统需要均衡的问题。 3、数据同步策略为保证缓存数据与数据库数据一致,主要考虑如下两种策略实现: 1、先删除缓存,再更新数据库; 2、先更新数据库,再删除缓存; 当然除了这两种策略之外,还有其他策略如将删除缓存改为更新缓存,但考虑高频繁更新及热冷数据场景下缓存使用效率问题,个人不推荐更新缓存方式,所以此处不做展开。 3.1 先删除缓存,在更新数据库操作流程如图
如上图,若先删除缓存,再更新数据库,则可能存在如下问题: 若步骤5、6、7顺序发生在步骤3、4之前或步骤3更新失败,则步骤8中线程B查询出的数据为旧数据,导致重新写入缓存的也为旧数据。 3.1.1 解决思路失败重试 + 延时双删
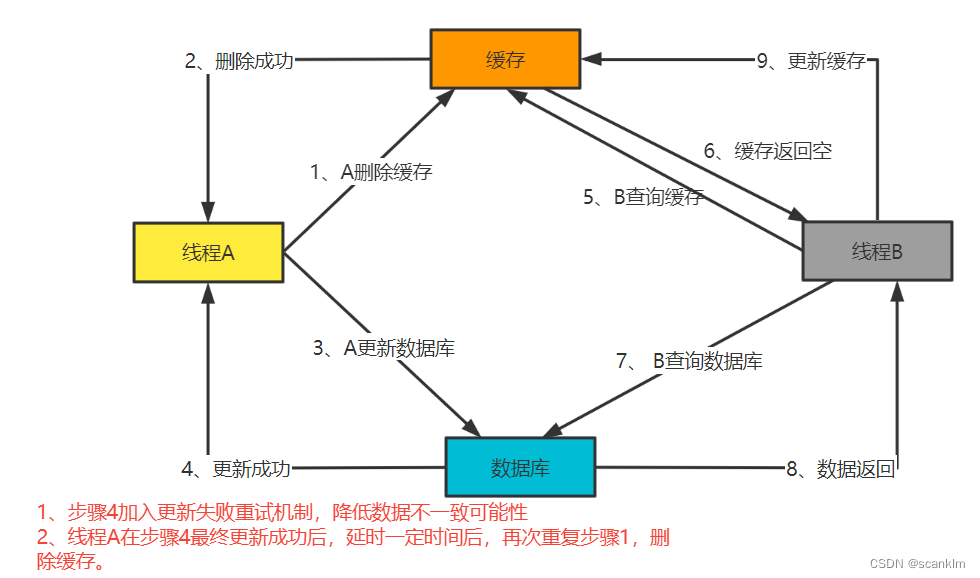
如图中红色部分所述,线程A在步骤4数据更新成功后,延迟一段时间,再次删除缓存,这样即可解决并发场景下线程B并发操作导致缓存与数据库数据不一致问题。延迟时间视实际业务场景对时间敏感度而定。 3.2 先更新数据库,再删除缓存操作流程如图
如上图,若先更新数据库,再删除缓存,则可能存在如下问题: 步骤5、6发生在步骤3之前或步骤3删除缓存失败,则线程B通过步骤5会拿到缓存数据,但此时获取到的缓存数据仍为旧数据。 3.2.1 解决思路订阅binlog 数据库的每一步操作均会写入binlog日志,可以通过监听binlog,实时感知数据变化情况,根据数据变化情况删除redis并添加重试机制,直至redis删除成功。 引入消息队列 上图步骤3中若Redis删除失败,则将Redis key放入消息队列,消费端监听消息队列并删除Redis直至删除成功; 总结需要注意的是3.1.1 和 3.2.1中描述的解决方案也只能保证最终数据一致性,无法保证强一致性,如上述各场景中若线程A操作异常,在通过3.1.1 和 3.2.1的方式解决问题之前,其他线程仍有可能获取到脏数据。 |
您可能感兴趣的文章 :

-
mysql日常锁表之flush_tables介绍
1. Flush tables简介 官方手册中关于Flush tables的介绍 Closes all open tables, forces all tables in use to be closed, and flushes the query cache. FLUSH TABLES also remove -
Mysql中的secure_file_priv参数设置方法
secure_file_priv是MySQL中的系统变量,用于限制文件的读取和写入。 该参数的设置可以通过my.ini(windows版本)/my.cnf(Linux版本)中设置。 修改完参数 -
Redis数据类型Streams的介绍
Redis Streams 是 Redis 5.0 引入的一种新的数据类型,它提供了一种强大的日志结构化数据存储方式。Streams 类型非常适合用于构建消息队列、事 -
Redis怎么处理Hash冲突
在 Redis 中,哈希表是一种常见的数据结构,通常用于存储对象的属性,对于哈希表,最常遇到的是哈希冲突,那么,当 Redis遇到Hash冲突会如 -
Redis实现分布式锁时需要考虑的问题解决方案
分布式系统中的多个节点经常需要对共享资源进行并发访问,若没有有效的协调机制,可能会导致数据竞争、资源冲突等问题。分布式锁应 -
Redis连接池监控(连接池是否已满)与优化方法
Redis作为一个高性能的内存数据库,广泛应用于各类高并发场景中。然而,在使用Redis时,连接池的管理至关重要,特别是在高并发应用中, -

Redis在Ubuntu系统上的安装步骤
1. 先切换到 root 用户 在 Ubuntu 20.04 中,可以通过以下步骤切换到 root 用户: 输入以下命令,以 root 用户身份登录: 1 sudo su - 按回车键,并输



-
解决redis sentinel频繁主备切换的问题
2021-04-08
-
Redis三种集群模式介绍
2021-10-03
-
Redis内存碎片率调优处理方式
2024-09-30
-
springboot使用Redis作缓存使用教程
2021-07-26
-
异步redis队列实现 数据入库的方法
2019-10-11

