前言
面试官:
"你了解虚拟DOM(Virtual DOM)跟Diff算法吗,请描述一下它们";
我:
"额,...鹅,那个",完了,突然智商不在线,没组织好语言没答好或者压根就答不出来;
所以这次我总结一下相关的知识点,让你可以有一个清晰的认知之余也会让你在今后遇到这种情况可以坦然自若,应付自如,游刃有余。
虚拟DOM(Virtual DOM):
什么是虚拟DOM
一句话总结虚拟DOM就是一个用来描述真实DOM的javaScript对象,这样说可能不够形象,那我们来举个例子:
分别用代码来描述真实DOM以及虚拟DOM
真实DOM
|
1 2 3 4 5 |
<ul class="list"> <li>a</li> <li>b</li> <li>c</li> </ul> |
对应的虚拟DOM:
|
1 2 3 4 5 6 |
let vnode = h('ul.list', [ h('li','a'), h('li','b'), h('li','c'), ]) console.log(vnode) |
对应的虚拟DOM:

h函数生成的虚拟DOM这个JS对象(Vnode)的源码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
export interface VNodeData { props?: Props attrs?: Attrs class?: Classes style?: VNodeStyle dataset?: Dataset on?: On hero?: Hero attachData?: AttachData hook?: Hooks key?: Key ns?: string // for SVGs fn?: () => VNode // for thunks args?: any[] // for thunks [key: string]: any // for any other 3rd party module } export type Key = string | number const interface VNode = { sel: string | undefined, // 选择器 data: VNodeData | undefined, // VNodeData上面定义的VNodeData children: Array<VNode | string> | undefined, //子节点,与text互斥 text: string | undefined, // 标签中间的文本内容 elm: Node | undefined, // 转换而成的真实DOM key: Key | undefined // 字符串或者数字 } |
补充: 上面的h函数大家可能有点熟悉的感觉但是一时间也没想起来,没关系我来帮大伙回忆;
开发中常见的现实场景,render函数渲染:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
// 案例1 vue项目中的main.js的创建vue实例 new Vue({ router, store, render: h => h(App) }).$mount("#app"); //案例2 列表中使用render渲染 columns: [ { title: "操作", key: "action", width: 150, render: (h, params) => { return h('div', [ h('Button', { props: { size: 'small' }, style: { marginRight: '5px', marginBottom: '5px', }, on: { click: () => { this.toEdit(params.row.uuid); } } }, '编辑') ]); } } ] |
为什么要使用虚拟DOM:
MVVM框架解决视图和状态同步问题
模板引擎可以简化视图操作,没办法跟踪状态
虚拟DOM跟踪状态变化
参考github上virtual-dom的动机描述
- 虚拟DOM可以维护程序的状态,跟踪上一次的状态
- 通过比较前后两次状态差异更新真实DOM
跨平台使用
- 浏览器平台渲染DOM
- 服务端渲染SSR(Nuxt.js/Next.js),前端是vue向,后者是react向
- 原生应用(Weex/React Native)
- 小程序(mpvue/uni-app)等
真实DOM的属性很多,创建DOM节点开销很大
虚拟DOM只是普通JavaScript对象,描述属性并不需要很多,创建开销很小
复杂视图情况下提升渲染性能(操作dom性能消耗大,减少操作dom的范围可以提升性能)
灵魂发问:使用了虚拟DOM就一定会比直接渲染真实DOM快吗?
答案当然是否定的,且听我说:
举例:当一个节点变更时DOMA->DOMB
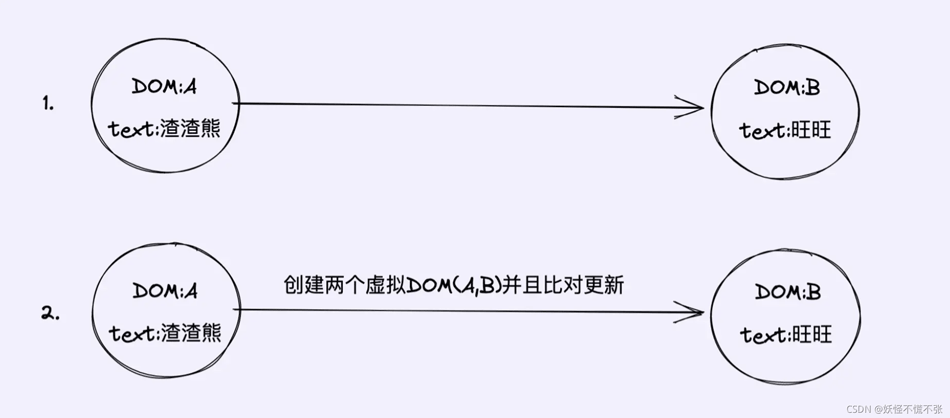
上述情况:
- 示例1:是创建一个DOMB然后替换掉DOMA;
- 示例2:去创建虚拟DOM+DIFF算法比对发现DOMB跟DOMA不是相同的节点,最后还是创建一个DOMB然后替换掉DOMA;
可以明显看出1是更快的,同样的结果,2还要去创建虚拟DOM+DIFF算啊对比
所以说使用虚拟DOM比直接操作真实DOM就一定要快这个说法是错误的,不严谨的
举例:当DOM树里面的某个子节点的内容变更时:
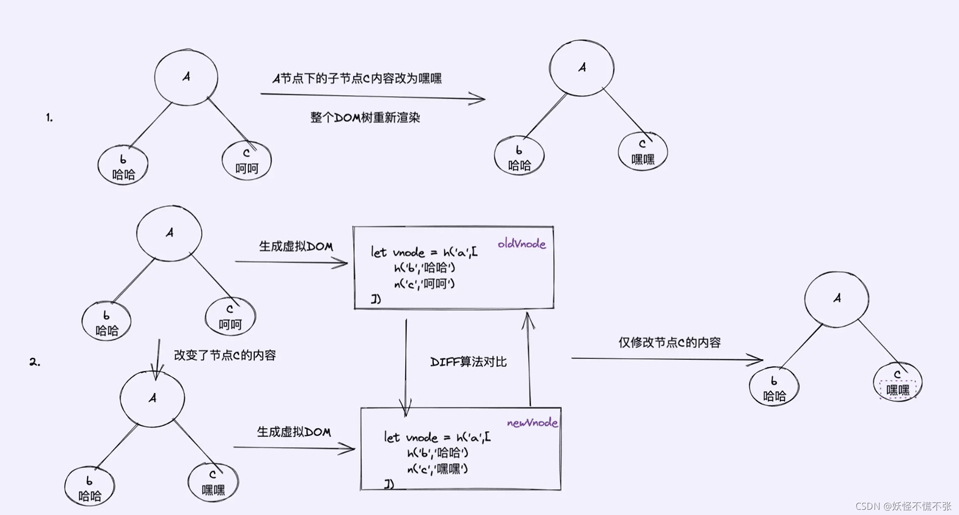
当一些复杂的节点,比如说一个父节点里面有多个子节点,当只是一个子节点的内容发生了改变,那么我们没有必要像示例1重新去渲染这个DOM树,这个时候虚拟DOM+DIFF算法就能够得到很好的体现,我们通过示例2使用虚拟DOM+Diff算法去找出改变了的子节点更新它的内容就可以了
总结:复杂视图情况下提升渲染性能,因为虚拟DOM+Diff算法可以精准找到DOM树变更的地方,减少DOM的操作(重排重绘)
虚拟dom库
Snabbdom
- Vue.js2.x内部使用的虚拟DOM就是改造的Snabbdom
- 大约200SLOC(single line of code)
- 通过模块可扩展
- 源码使用TypeScript开发
- 最快的Virtual DOM之一
virtual-dom
diff算法
在看完上述的文章之后相信大家已经对Diff算法有一个初步的概念,没错,Diff算法其实就是找出两者之间的差异;
diff 算法首先要明确一个概念就是 Diff 的对象是虚拟DOM(virtual dom),更新真实 DOM 是 Diff 算法的结果。
下面我将会手撕 snabbdom源码核心部分为大家打开Diff的心
snabbdom的核心
- init()设置模块.创建patch()函数
- 使用h()函数创建JavaScript对象(Vnode)描述真实DOM
- patch()比较新旧两个Vnode
- 把变化的内容更新到真实DOM树
init函数
init函数时设置模块,然后创建patch()函数,我们先通过场景案例来有一个直观的体现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
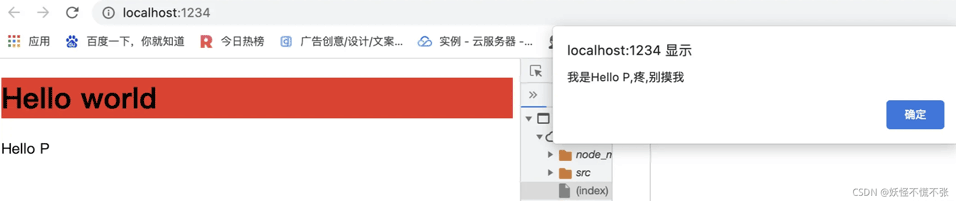
import {init} from 'snabbdom/build/package/init.js' import {h} from 'snabbdom/build/package/h.js' // 1.导入模块 import {styleModule} from "snabbdom/build/package/modules/style"; import {eventListenersModule} from "snabbdom/build/package/modules/eventListeners"; // 2.注册模块 const patch = init([ styleModule, eventListenersModule ]) // 3.使用h()函数的第二个参数传入模块中使用的数据(对象) let vnode = h('div', [ h('h1', {style: {backgroundColor: 'red'}}, 'Hello world'), h('p', {on: {click: eventHandler}}, 'Hello P') ]) function eventHandler() { alert('疼,别摸我') } const app = document.querySelector('#app') patch(app,vnode) |
当init使用了导入的模块就能够在h函数中用这些模块提供的api去创建虚拟DOM(Vnode)对象;在上文中就使用了样式模块以及事件模块让创建的这个虚拟DOM具备样式属性以及事件属性,最终通过patch函数对比两个虚拟dom(会先把app转换成虚拟dom),更新视图;
我们再简单看看init的源码部分:
|
1 2 3 4 5 6 7 8 9 10 |
// src/package/init.ts /* 第一参数就是各个模块 第二参数就是DOMAPI,可以把DOM转换成别的平台的API, 也就是说支持跨平台使用,当不传的时候默认是htmlDOMApi,见下文 init是一个高阶函数,一个函数返回另外一个函数,可以缓存modules,与domApi两个参数, 那么以后直接只传oldValue跟newValue(vnode)就可以了*/ export function init (modules: Array<Partial<Module>>, domApi?: DOMAPI) { ... return function patch (oldVnode: VNode | Element, vnode: VNode): VNode {} } |
h函数
有些地方也会用createElement来命名,它们是一样的东西,都是创建虚拟DOM的,在上述文章中相信大伙已经对h函数有一个初步的了解并且已经联想了使用场景,就不作场景案例介绍了,直接上源码部分:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
// h函数 export function h (sel: string): VNode export function h (sel: string, data: VNodeData | null): VNode export function h (sel: string, children: VNodeChildren): VNode export function h (sel: string, data: VNodeData | null, children: VNodeChildren): VNode export function h (sel: any, b?: any, c?: any): VNode { var data: VNodeData = {} var children: any var text: any var i: number ... return vnode(sel, data, children, text, undefined) //最终返回一个vnode函数 }; // vnode函数 export function vnode (sel: string | undefined, data: any | undefined, children: Array<VNode | string> | undefined, text: string | undefined, elm: Element | Text | undefined): VNode { const key = data === undefined ? undefined : data.key return { sel, data, children, text, elm, key } //最终生成Vnode对象 } |
总结:h函数先生成一个vnode函数,然后vnode函数再生成一个Vnode对象(虚拟DOM对象)
补充:
在h函数源码部分涉及一个函数重载的概念,简单说明一下:
- 参数个数或参数类型不同的函数()
- JavaScript中没有重载的概念
- TypeScript中有重载,不过重载的实现还是通过代码调整参数
重载这个概念个参数相关,和返回值无关
实例1(函数重载-参数个数)
|
1 2 3 4 5 6 7 8 |
function add(a:number,b:number){ console.log(a+b) } function add(a:number,b:number,c:number){ console.log(a+b+c) } add(1,2) add(1,2,3) |
实例2(函数重载-参数类型)
|
1 2 3 4 5 6 7 8 |
function add(a:number,b:number){ console.log(a+b) } function add(a:number,b:string){ console.log(a+b) } add(1,2) add(1,'2') |
patch函数(核心)
要是看完前面的铺垫,看到这里你可能走神了,醒醒啊,这是核心啊,上高地了兄弟;
- pactch(oldVnode,newVnode)
- 把新节点中变化的内容渲染到真实DOM,最后返回新节点作为下一次处理的旧节点(核心)
- 对比新旧VNode是否相同节点(节点的key和sel相同)
- 如果不是相同节点,删除之前的内容,重新渲染
- 如果是相同节点,再判断新的VNode是否有text,如果有并且和oldVnode的text不同直接更新文本内容(patchVnode)
- 如果新的VNode有children,判断子节点是否有变化(updateChildren,最麻烦,最难实现)
源码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
return function patch(oldVnode: VNode | Element, vnode: VNode): VNode { let i: number, elm: Node, parent: Node const insertedVnodeQueue: VNodeQueue = [] // cbs.pre就是所有模块的pre钩子函数集合 for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]() // isVnode函数时判断oldVnode是否是一个虚拟DOM对象 if (!isVnode(oldVnode)) { // 若不是即把Element转换成一个虚拟DOM对象 oldVnode = emptyNodeAt(oldVnode) } // sameVnode函数用于判断两个虚拟DOM是否是相同的,源码见补充1; if (sameVnode(oldVnode, vnode)) { // 相同则运行patchVnode对比两个节点,关于patchVnode后面会重点说明(核心) patchVnode(oldVnode, vnode, insertedVnodeQueue) } else { elm = oldVnode.elm! // !是ts的一种写法代码oldVnode.elm肯定有值 // parentNode就是获取父元素 parent = api.parentNode(elm) as Node // createElm是用于创建一个dom元素插入到vnode中(新的虚拟DOM) createElm(vnode, insertedVnodeQueue) if (parent !== null) { // 把dom元素插入到父元素中,并且把旧的dom删除 api.insertBefore(parent, vnode.elm!, api.nextSibling(elm))// 把新创建的元素放在旧的dom后面 removeVnodes(parent, [oldVnode], 0, 0) } } for (i = 0; i < insertedVnodeQueue.length; ++i) { insertedVnodeQueue[i].data!.hook!.insert!(insertedVnodeQueue[i]) } for (i = 0; i < cbs.post.length; ++i) cbs.post[i]() return vnode } |
patchVnode
- 第一阶段触发prepatch函数以及update函数(都会触发prepatch函数,两者不完全相同才会触发update函数)
- 第二阶段,真正对比新旧vnode差异的地方
- 第三阶段,触发postpatch函数更新节点
源码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
function patchVnode(oldVnode: VNode, vnode: VNode, insertedVnodeQueue: VNodeQueue) { const hook = vnode.data?.hook hook?.prepatch?.(oldVnode, vnode) const elm = vnode.elm = oldVnode.elm! const oldCh = oldVnode.children as VNode[] const ch = vnode.children as VNode[] if (oldVnode === vnode) return if (vnode.data !== undefined) { for (let i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode) vnode.data.hook?.update?.(oldVnode, vnode) } if (isUndef(vnode.text)) { // 新节点的text属性是undefined if (isDef(oldCh) && isDef(ch)) { // 当新旧节点都存在子节点 if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue) //并且他们的子节点不相同执行updateChildren函数,后续会重点说明(核心) } else if (isDef(ch)) { // 只有新节点有子节点 // 当旧节点有text属性就会把''赋予给真实dom的text属性 if (isDef(oldVnode.text)) api.setTextContent(elm, '') // 并且把新节点的所有子节点插入到真实dom中 addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue) } else if (isDef(oldCh)) { // 清除真实dom的所有子节点 removeVnodes(elm, oldCh, 0, oldCh.length - 1) } else if (isDef(oldVnode.text)) { // 把''赋予给真实dom的text属性 api.setTextContent(elm, '') } } else if (oldVnode.text !== vnode.text) { //若旧节点的text与新节点的text不相同 if (isDef(oldCh)) { // 若旧节点有子节点,就把所有的子节点删除 removeVnodes(elm, oldCh, 0, oldCh.length - 1) } api.setTextContent(elm, vnode.text!) // 把新节点的text赋予给真实dom } hook?.postpatch?.(oldVnode, vnode) // 更新视图 } |
看得可能有点蒙蔽,下面再上一副思维导图:

diff算法简介
传统diff算法
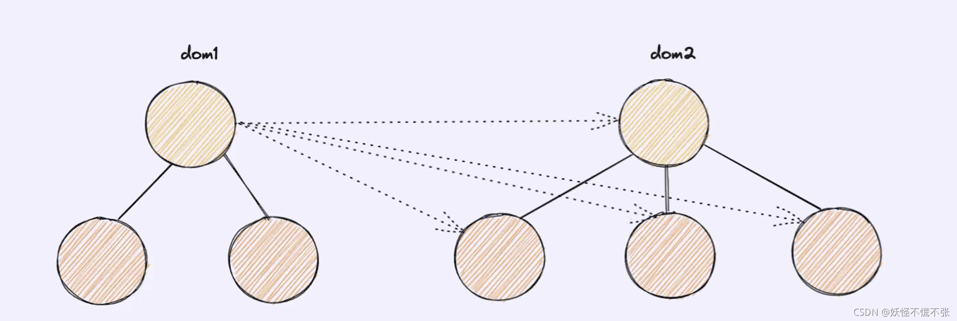
- 虚拟DOM中的Diff算法
- 传统算法查找两颗树每一个节点的差异
- 会运行n1(dom1的节点数)*n2(dom2的节点数)次方去对比,找到差异的部分再去更新
snabbdom的diff算法优化
- Snbbdom根据DOM的特点对传统的diff算法做了优化
- DOM操作时候很少会跨级别操作节点
- 只比较同级别的节点

下面我们就会介绍updateChildren函数怎么去对比子节点的异同,也是Diff算法里面的一个核心以及难点;
updateChildren(核中核:判断子节点的差异)
这个函数我分为三个部分,部分1:声明变量,部分2:同级别节点比较,部分3:循环结束的收尾工作(见下图);
同级别节点比较的五种情况:
- oldStartVnode/newStartVnode(旧开始节点/新开始节点)相同
- oldEndVnode/newEndVnode(旧结束节点/新结束节点)相同
- oldStartVnode/newEndVnode(旧开始节点/新结束节点)相同
- oldEndVnode/newStartVnode(旧结束节点/新开始节点)相同
- 特殊情况当1,2,3,4的情况都不符合的时候就会执行,在oldVnodes里面寻找跟newStartVnode一样的节点然后位移到oldStartVnode,若没有找到在就oldStartVnode创建一个
执行过程是一个循环,在每次循环里,只要执行了上述的情况的五种之一就会结束一次循环
循环结束的收尾工作:直到oldStartIdx>oldEndIdx || newStartIdx>newEndIdx(代表旧节点或者新节点已经遍历完)
为了更加直观的了解,我们再来看看同级别节点比较的五种情况的实现细节:
新开始节点和旧开始节点(情况1)

- 若情况1符合:(从新旧节点的开始节点开始对比,oldCh[oldStartIdx]和newCh[newStartIdx]进行sameVnode(key和sel相同)判断是否相同节点)
- 则执行patchVnode找出两者之间的差异,更新图;如没有差异则什么都不操作,结束一次循环
- oldStartIdx++/newStartIdx++
新结束节点和旧结束节点(情况2)
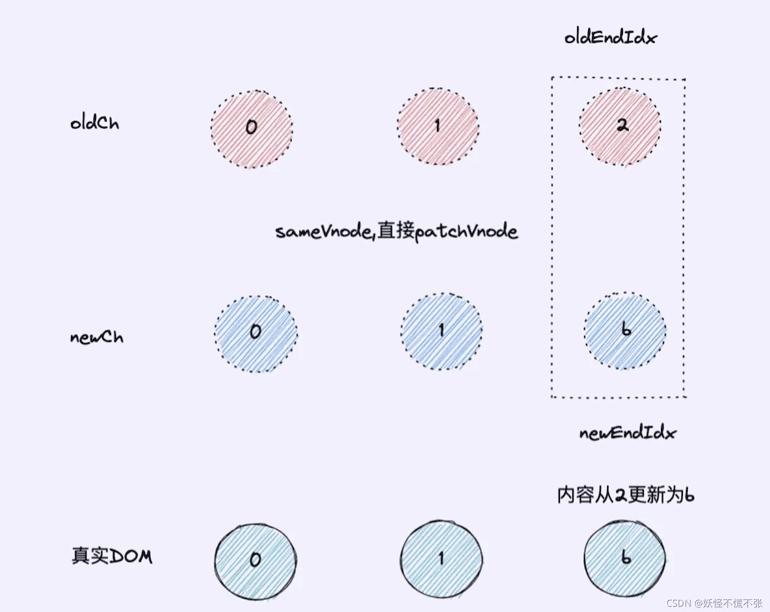
- 若情况1不符合就判断情况2,若符合:(从新旧节点的结束节点开始对比,oldCh[oldEndIdx]和newCh[newEndIdx]对比,执行sameVnode(key和sel相同)判断是否相同节点)
- 执行patchVnode找出两者之间的差异,更新视图,;如没有差异则什么都不操作,结束一次循环
- oldEndIdx–/newEndIdx–
旧开始节点/新结束节点(情况3)
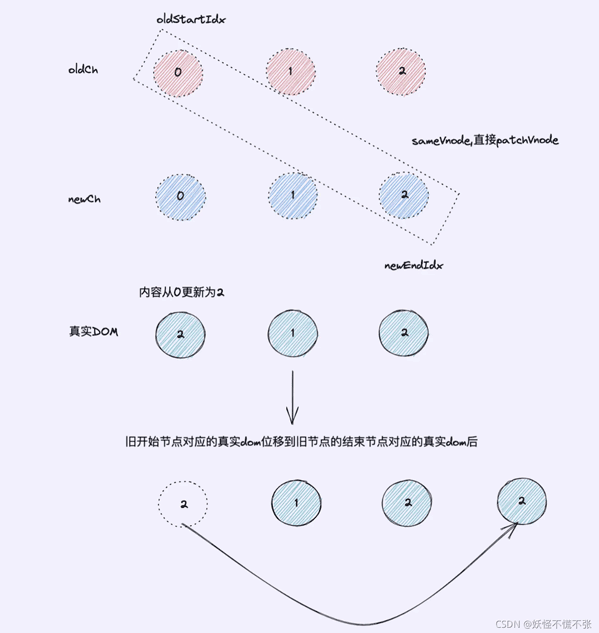
- 若情况1,2都不符合,就会尝试情况3:(旧节点的开始节点与新节点的结束节点开始对比,oldCh[oldStartIdx]和newCh[newEndIdx]对比,执行sameVnode(key和sel相同)判断是否相同节点)
- 执行patchVnode找出两者之间的差异,更新视图,如没有差异则什么都不操作,结束一次循环
- oldCh[oldStartIdx]对应的真实dom位移到oldCh[oldEndIdx]对应的真实dom后
- oldStartIdx++/newEndIdx–;
旧结束节点/新开始节点(情况4)

- 若情况1,2,3都不符合,就会尝试情况4:(旧节点的结束节点与新节点的开始节点开始对比,oldCh[oldEndIdx]和newCh[newStartIdx]对比,执行sameVnode(key和sel相同)判断是否相同节点)
- 执行patchVnode找出两者之间的差异,更新视图,如没有差异则什么都不操作,结束一次循环
- oldCh[oldEndIdx]对应的真实dom位移到oldCh[oldStartIdx]对应的真实dom前
- oldEndIdx–/newStartIdx++;
新开始节点/旧节点数组中寻找节点(情况5)

从旧节点里面寻找,若寻找到与newCh[newStartIdx]相同的节点(且叫对应节点[1]),执行patchVnode找出两者之间的差异,更新视图,如没有差异则什么都不操作,结束一次循环
对应节点[1]对应的真实dom位移到oldCh[oldStartIdx]对应的真实dom前

若没有寻找到相同的节点,则创建一个与newCh[newStartIdx]节点对应的真实dom插入到oldCh[oldStartIdx]对应的真实dom前
newStartIdx++
下面我们再介绍一下结束循环的收尾工作(oldStartIdx>oldEndIdx || newStartIdx>newEndIdx):

新节点的所有子节点先遍历完(newStartIdx>newEndIdx),循环结束
新节点的所有子节点遍历结束就是把没有对应相同节点的子节点删除
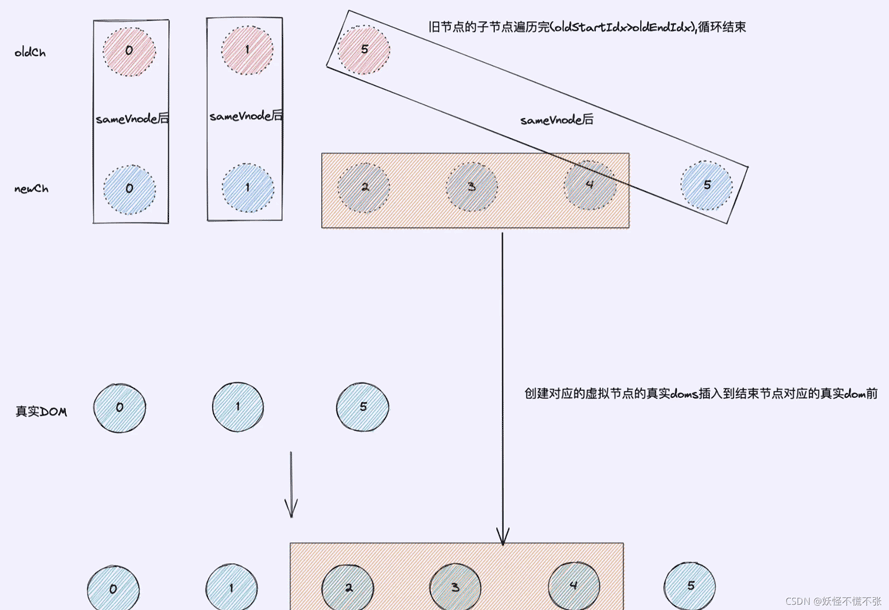
旧节点的所有子节点先遍历完(oldStartIdx>oldEndIdx),循环结束
旧节点的所有子节点遍历结束就是在多出来的子节点插入到旧节点结束节点前;(源码:newCh[newEndIdx + 1].elm),就是对应的旧结束节点的真实dom,newEndIdx+1是因为在匹配到相同的节点需要-1,所以需要加回来就是结束节点
最后附上源码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
function updateChildren(parentElm, oldCh, newCh, insertedVnodeQueue) { let oldStartIdx = 0; // 旧节点开始节点索引 let newStartIdx = 0; // 新节点开始节点索引 let oldEndIdx = oldCh.length - 1; // 旧节点结束节点索引 let oldStartVnode = oldCh[0]; // 旧节点开始节点 let oldEndVnode = oldCh[oldEndIdx]; // 旧节点结束节点 let newEndIdx = newCh.length - 1; // 新节点结束节点索引 let newStartVnode = newCh[0]; // 新节点开始节点 let newEndVnode = newCh[newEndIdx]; // 新节点结束节点 let oldKeyToIdx; // 节点移动相关 let idxInOld; // 节点移动相关 let elmToMove; // 节点移动相关 let before; // 同级别节点比较 while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { if (oldStartVnode == null) { oldStartVnode = oldCh[++oldStartIdx]; // Vnode might have been moved left } else if (oldEndVnode == null) { oldEndVnode = oldCh[--oldEndIdx]; } else if (newStartVnode == null) { newStartVnode = newCh[++newStartIdx]; } else if (newEndVnode == null) { newEndVnode = newCh[--newEndIdx]; } else if (sameVnode(oldStartVnode, newStartVnode)) { // 判断情况1 patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue); oldStartVnode = oldCh[++oldStartIdx]; newStartVnode = newCh[++newStartIdx]; } else if (sameVnode(oldEndVnode, newEndVnode)) { // 情况2 patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue); oldEndVnode = oldCh[--oldEndIdx]; newEndVnode = newCh[--newEndIdx]; } else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right情况3 patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue); api.insertBefore(parentElm, oldStartVnode.elm, api.nextSibling(oldEndVnode.elm)); oldStartVnode = oldCh[++oldStartIdx]; newEndVnode = newCh[--newEndIdx]; } else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left情况4 patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue); api.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm); oldEndVnode = oldCh[--oldEndIdx]; newStartVnode = newCh[++newStartIdx]; } else { // 情况5 if (oldKeyToIdx === undefined) { oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx); } idxInOld = oldKeyToIdx[newStartVnode.key]; if (isUndef(idxInOld)) { // New element // 创建新的节点在旧节点的新节点前 api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm); } else { elmToMove = oldCh[idxInOld]; if (elmToMove.sel !== newStartVnode.sel) { // 创建新的节点在旧节点的新节点前 api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm); } else { // 在旧节点数组中找到相同的节点就对比差异更新视图,然后移动位置 patchVnode(elmToMove, newStartVnode, insertedVnodeQueue); oldCh[idxInOld] = undefined; api.insertBefore(parentElm, elmToMove.elm, oldStartVnode.elm); } } newStartVnode = newCh[++newStartIdx]; } } // 循环结束的收尾工作 if (oldStartIdx <= oldEndIdx || newStartIdx <= newEndIdx) { if (oldStartIdx > oldEndIdx) { // newCh[newEndIdx + 1].elm就是旧节点数组中的结束节点对应的dom元素 // newEndIdx+1是因为在之前成功匹配了newEndIdx需要-1 // newCh[newEndIdx + 1].elm,因为已经匹配过有相同的节点了,它就是等于旧节点数组中的结束节点对应的dom元素(oldCh[oldEndIdx + 1].elm) before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm; // 把新节点数组中多出来的节点插入到before前 addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue); } else { // 这里就是把没有匹配到相同节点的节点删除掉 removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx); } } } |
key的作用
- Diff操作可以更加快速;
- Diff操作可以更加准确;(避免渲染错误)
- 不推荐使用索引作为key
以下我们看看这些作用的实例:
Diff操作可以更加准确;(避免渲染错误):
实例:a,b,c三个dom元素中的b,c间插入一个z元素
没有设置key

当设置了key:

Diff操作可以更加准确;(避免渲染错误)
实例:a,b,c三个dom元素,修改了a元素的某个属性再去在a元素前新增一个z元素
没有设置key:


因为没有设置key,默认都是undefined,所以节点都是相同的,更新了text的内容但还是沿用了之前的dom,所以实际上a->z(a原本打勾的状态保留了,只改变了text),b->a,c->b,d->c,遍历完毕发现还要增加一个dom,在最后新增一个text为d的dom元素
设置了key:


当设置了key,a,b,c,d都有对应的key,a->a,b->b,c->c,d->d,内容相同无需更新,遍历结束,新增一个text为z的dom元素
不推荐使用索引作为key:
设置索引为key:
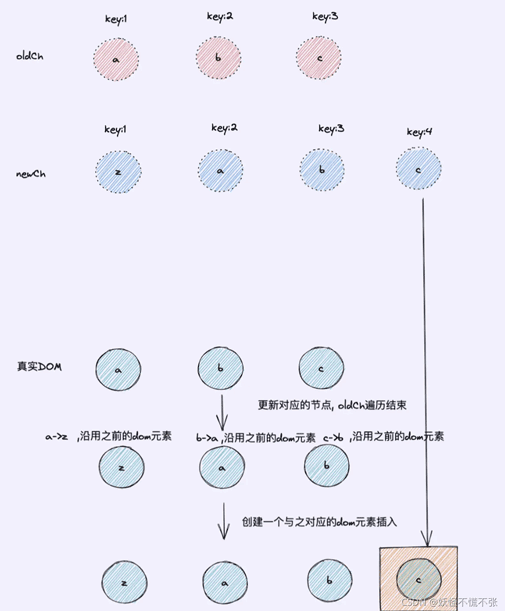
这明显效率不高,我们只希望找出不同的节点更新,而使用索引作为key会增加运算时间,我们可以把key设置为与节点text为一致就可以解决这个问题: