一. Dispatchers.IO 1.Dispatchers.IO 在协程中,当需要执行IO任务时,会在上下文中指定Dispatchers.IO来进行线程的切换调度。 而IO实际上是CoroutineDispatcher类型的对象,实际的值为DefaultScheduler类的
一. Dispatchers.IO1.Dispatchers.IO在协程中,当需要执行IO任务时,会在上下文中指定Dispatchers.IO来进行线程的切换调度。 而IO实际上是CoroutineDispatcher类型的对象,实际的值为DefaultScheduler类的常量对象IO,代码如下:
2.DefaultScheduler类DefaultScheduler类继承自ExperimentalCoroutineDispatcher类,内部提供了类型为LimitingDispatcher的IO对象,代码如下:
3.LimitingDispatcher类LimitingDispatcher类继承自ExecutorCoroutineDispatcher类,实现了TaskContext接口和Executor接口。 LimitingDispatcher类的核心是构造方法中类型为ExperimentalCoroutineDispatcher的dispatcher对象。 LimitingDispatcher类看起来是一个标准的线程池,但实际上LimitingDispatcher类只对类参数中传入的dispatcher进行包装和功能扩展。如同名字中的litmit一样,LimitingDispatcher类主要用于对任务执行数量进行限制,代码如下:
dispatcher的dispatch方法定义在ExperimentalCoroutineDispatcher类中。 4.ExperimentalCoroutineDispatcher类ExperimentalCoroutineDispatcher类继承自ExecutorCoroutineDispatcher类,代码如下:
在ExperimentalCoroutineDispatcher类的dispatch方法内部,通过调用类型为CoroutineScheduler的对象的dispatch方法实现。 二.CoroutineScheduler类1.CoroutineScheduler类的继承关系在对CoroutineScheduler类的dispatch方法分析之前,首先分析一下CoroutineScheduler类的继承关系,代码如下:
2.CoroutineScheduler类的全局变量接下来对CoroutineScheduler类中重要的全局变量进行分析,代码如下:
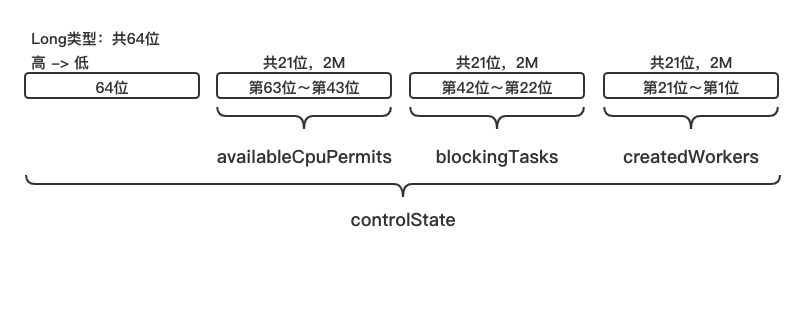
CoroutineScheduler类中对线程的状态与权限控制:
availableCpuPermits的初始值为参数中核心线程数corePoolSize的值,表示CoroutineScheduler类中最多只有corePoolSize个核心线程。执行纯CPU任务的线程每次执行任务之前需要在availableCpuPermits中进行记录与申请。blockingTasks表示执行非纯CPU任务的数量。这部分线程在执行时不需要CPU令牌。createdWorkers表示当前线程池中所有线程的数量,每个线程在创建或终止时都需要通过在这里进行记录。这些变量的具体关系如下: createdWorkers = blockingTasks + corePoolSize - availableCpuPermits CPU令牌是线程池自定义的概念,不代表时间片,只是为了保证核心线程的数量。 三.Worker类与WorkerState类在分析CoroutineScheduler类的dispatch方法之前,还需要分析一下CoroutineScheduler类中的两个重要的内部类Worker类以及其对应的状态类WorkerState类。 Worker是一个线程池中任务的核心执行者,几乎在所有的线程池中都存在Worker的概念。 1.WorkerState类首先分析一下WorkerState类,代码如下:
2.Worker类的继承关系与全局变量接下来对Worker类的继承关系以及其中重要的全局变量进行分析,代码如下:
3.Worker类的run方法接下来分析Worker类的核心方法——run方法的实现,代码入下:
4.Worker类的任务寻找机制接下来分析Worker线程如何寻找任务,代码如下:
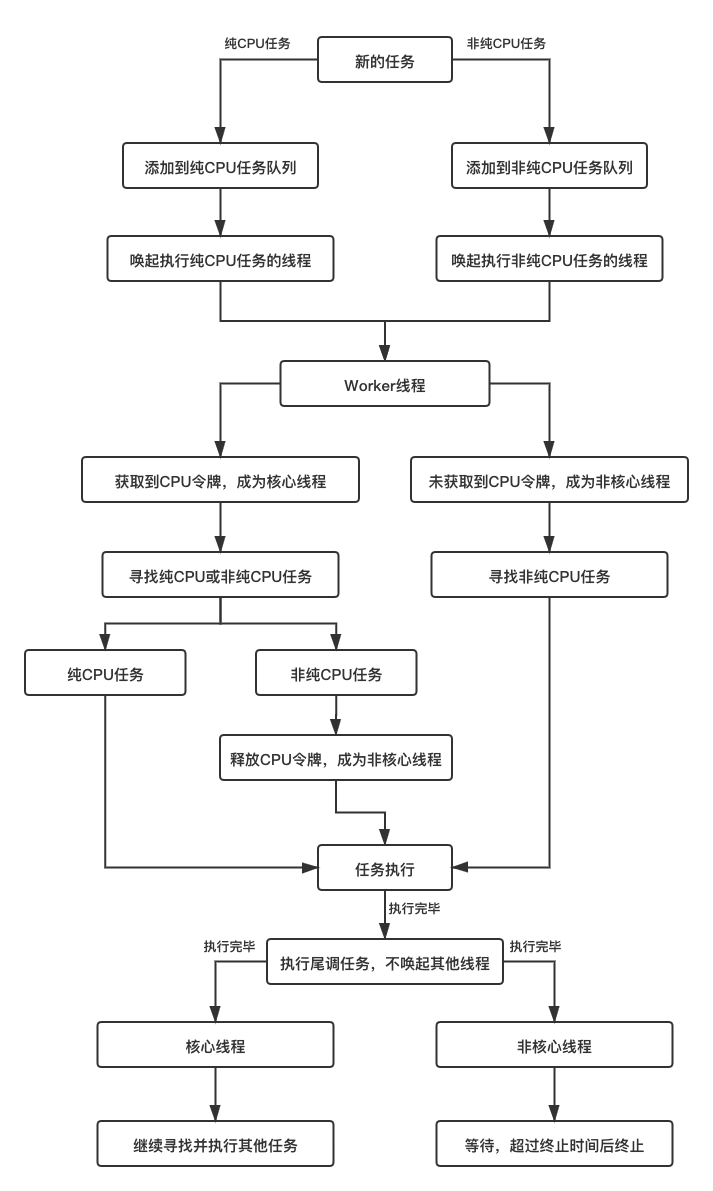
通过对这部分代码的分析,可以知道线程在寻找任务时,首先会尝试获取CPU令牌,成为核心线程。如果线程成为了核心线程,则随机从本地或全局的两个队列中获取一个任务,获取不到则去随机偷取一个任务。如果没有获取到CPU令牌,则优先在本地获取任务,获取不到则在全局非CPU任务队列中获取任务,获取不到则去偷取一个非CPU任务。 如果偷取的任务没有达到最小的可偷取时间,则返回需要等待的时间。如果偷取任务成功,则直接加入到本地队列中。偷取的核心过程,会在后面进行分析。 5.Worker类的任务执行机制接下来分析任务被获取到后如何被执行,代码如下:
四.CoroutineScheduler类的dispatch方法了解Worker类的工作机制后,接下来分析CoroutineScheduler类的dispatch方法,代码如下:
通过对上面的代码进行分析,可以知道CoroutineScheduler类的dispatch方法,首先会对任务进行封装。正常情况下,任务都会根据类型添加到全局队列中,接着根据任务类型,随机唤起一个执行对应类型任务的线程去执行任务。 当任务执行完毕后,会回调任务中自带的afterTask方法。根据之前对LimitingDispatcher的分析,可以知道,此时tailDispatch参数为true,同时当前的线程也是Worker线程,因此会被直接添加到线程的本地队列中,由于任务有对应的线程执行,因此跳过了唤起其他线程执行任务的阶段。这里我们可以称这个机制为尾调机制。 为什么CoroutineScheduler类中要设计一个尾调机制呢? 在传统的线程池的线程充足情况下,一个任务到来时,会被分配一个线程。假设前后两个任务A与B有依赖关系,需要在执行A再执行B,这时如果两个任务同时到来,执行A任务的线程会直接执行,而执行B线程的任务可能需要被阻塞。而一旦线程阻塞会造成线程资源的浪费。而协程本质上就是多个小段程序的相互协作,因此这种场景会非常多,通过这种机制可以保证任务的执行顺序,同时减少资源浪费,而且可以最大限度的保证一个连续的任务执行在同一个线程中。 至此,Dispatchers.IO线程池的工作原理全部分析完毕。 五.浅谈WorkQueue类1.add方法接下来分析一些更加细节的过程。首先分析一下Worker线程本地队列调用的add方法是如何添加任务的,代码如下:
2.任务偷取机制根据之前对Worker类的分析,任务偷取的核心代码锁定在了WorkQueue类的两个方法上:一个是偷取非纯CPU任务的tryStealBlockingFrom方法,另一个可以偷所有类型任务的tryStealFrom方法,代码如下:
六.总结1.两个线程池CoroutineScheduler类是核心的线程池,用于任务的执行。LimitingDispatcher类对CoroutineScheduler类进行代理,是CoroutineScheduler类尾调机制的使用者,对任务进行初步排队。 2.四种队列LimitingDispatcher类中的任务队列。CoroutineScheduler类中的两个全局队列。Worker类中的本地队列。 3.尾调机制一个任务执行完,可以通过回调,在同一个Worker线程中再存储一个待执行任务,该任务将在Worker线程本地队列目前已存在的任务,执行完毕后再执行。 4.任务分类与权限控制所有任务分成纯CPU任务和非纯CPU任务两种,对应着核心线程和非核心线程。 所有线程在执行前都先尝试成为核心线程,核心线程可以从两种任务中任意选择执行,非核心线程只能执行非纯CPU任务。核心线程如果选择执行非纯CPU任务会变成非核心线程 5.任务偷取机制WorkQueue类根据随机算法提供任务偷取机制,一个Worker线程可以从其他Worker线程的本地队列中偷取任务。 6.执行梳理图
|





2022-04-23
2022-01-26
2021-11-15
2021-08-02
2019-12-15