所用到的技术有Jsoup,HttpClient。 Jsoup jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 HttpClient HTTP 协议可能是现在 Internet 上使
|
所用到的技术有Jsoup,HttpClient。 Jsoup jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 HttpClient HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。虽然在 JDK 的 java net包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。 爬取豆瓣电影数据 豆瓣电影网址。
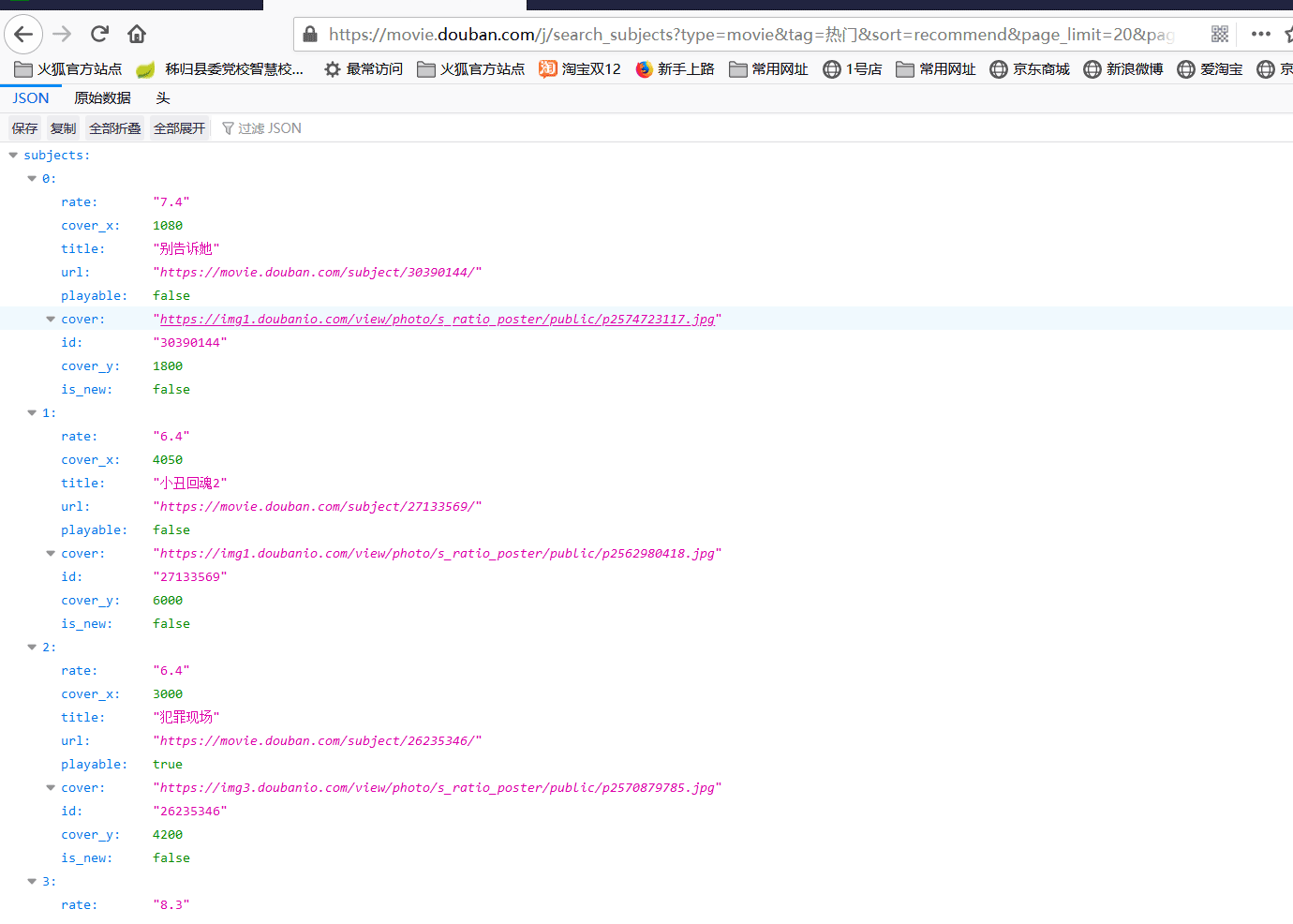
打开浏览器f12,地址栏中输入该地址访问,可以看到请求响应的页面,对应可以找到电影数据的请求地址,数据请求地址
可以看到数据请求地址响应过来的是一个JSON格式的数据,之后我们看到请求地址上的参数type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0。其中type是电影tag是标签,sort是按照热门进行排序的,page_limit是每页20条数据,page_start是从第几条数据开始查询(下标从0开始)。但是这不是我们想要的,我们需要去找豆瓣电影数据的总入口地址是下面这个
创建SpringBoot项目爬取数据 把爬取到的数据保存到数据库中,电影图片保存在本地磁盘中,这里持久层用的是JPA,所以需要引入对应的依赖。pom.xml中依赖代码如下。
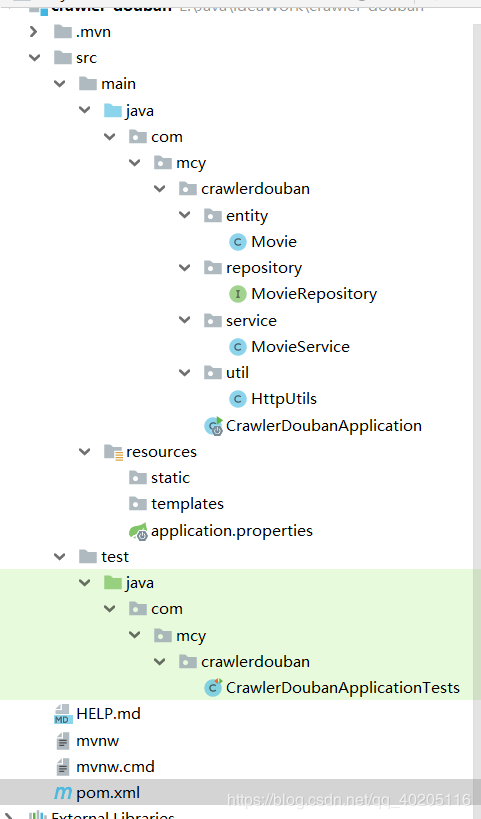
项目目录结构如下。
首先我们在entity包中建立实体对象,字段为豆瓣电影的基本信息(有些信息是详情页面的信息)。 Movie实体类。
在src/main/resources下找到application.properties文件,在该配置文件中配置数据库链接信息,需要在数据库中新建一个名为douban的数据库。
创建MovieRepository数据访问层接口
创建MovieService类,里边有一个保存数据的方法。
创建一个HttpUtils获取网页数据和保存图片的工具类。 创建连接池和配置连接池信息。
根据请求地址获取响应信息方法,获取成功后返回响应信息。
根据链接下载图片保存到本地方法。
HttpUtils工具类全部代码。
在项目的test类中编写代码获取数据保存到数据库中。 先通过@Resource注解将MovieService类对应的实现类注入进来。
设置请求地址https://movie.douban.com/j/search_subjects
之后在定义两个Map,用于存储请求头和请求参数信息。 网页请求头。
请求参数,type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0 设置请求参数和请求头代码如下。
通过HttpUtils类doGetHtml方法获取该请求响应的数据。
请求响应数据格式。
可以看出是一个json格式的数据,我们可以通过阿里巴巴的Fastjson一个json解析库,把它解析成为一个List格式数据。Fastjson基本用法
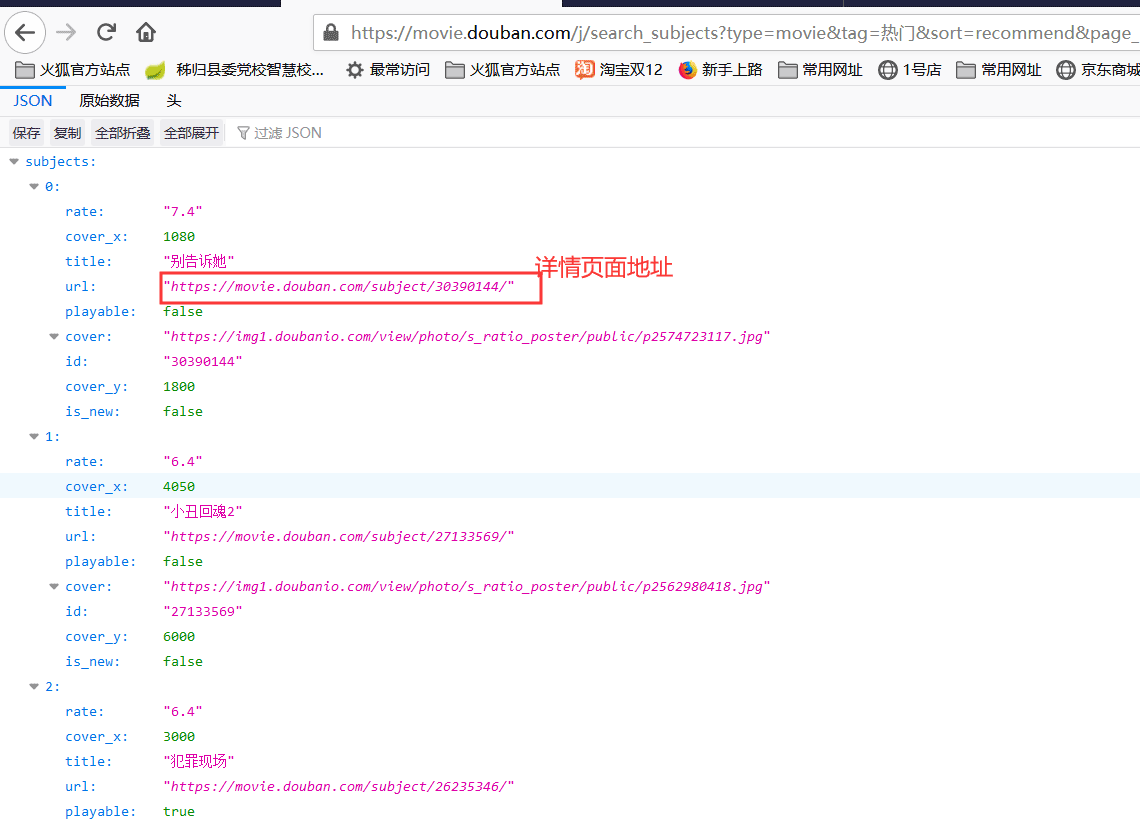
因为每页查询是是20条数据,我们用一个for循环遍历一下这一页的数据。可以获得电影的标题,评分,图片链接和详情页面的链接,上面JSON数据中的cover属性值为图片的地址。通过图片的链接我们可以调用HttpUtils类的doGetImage方法把图片保存到本地磁盘。
上面请求的数据只能获取到标题,评分和图片,然而我们还有获取导演,主演,和电影时长。这些信息我们点开上面请求到的json数据的url属性值,会打开详情页面,详情页面中有导演,主演,和电影时长信息。
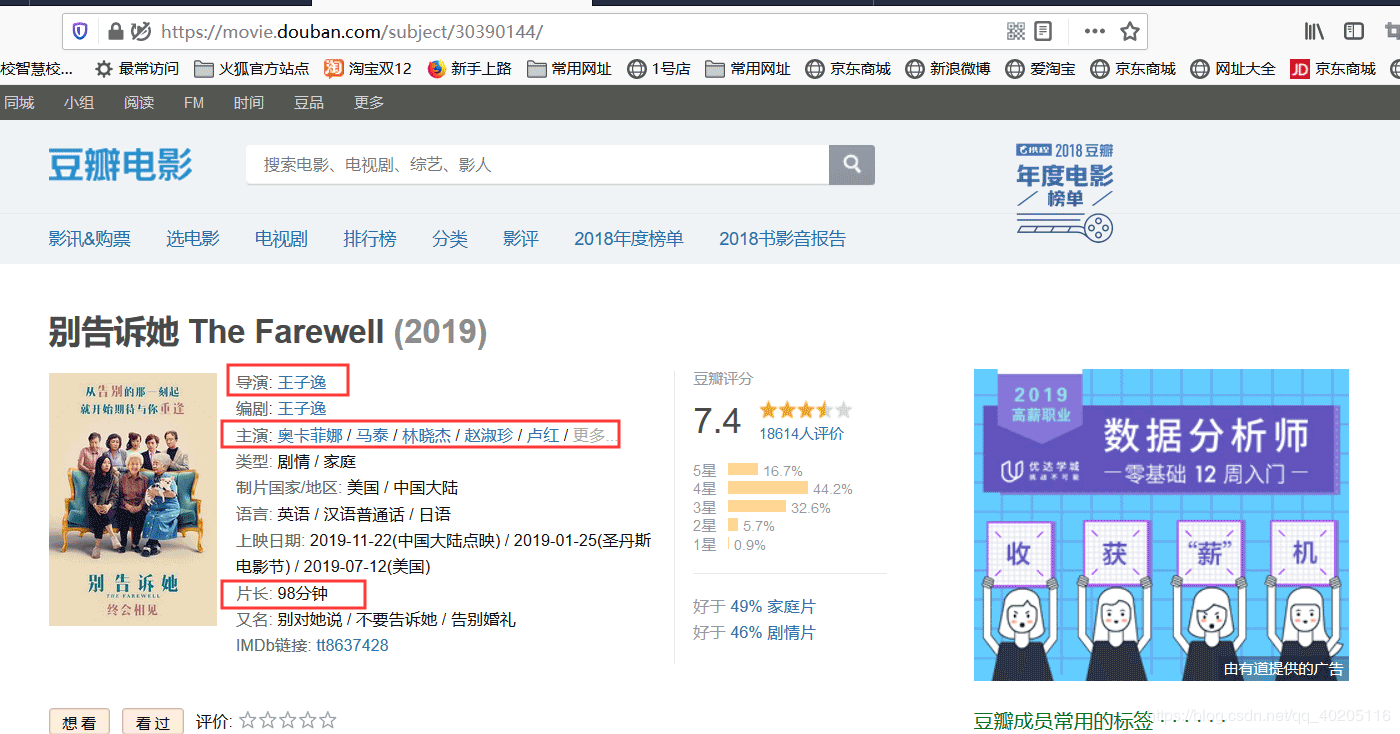
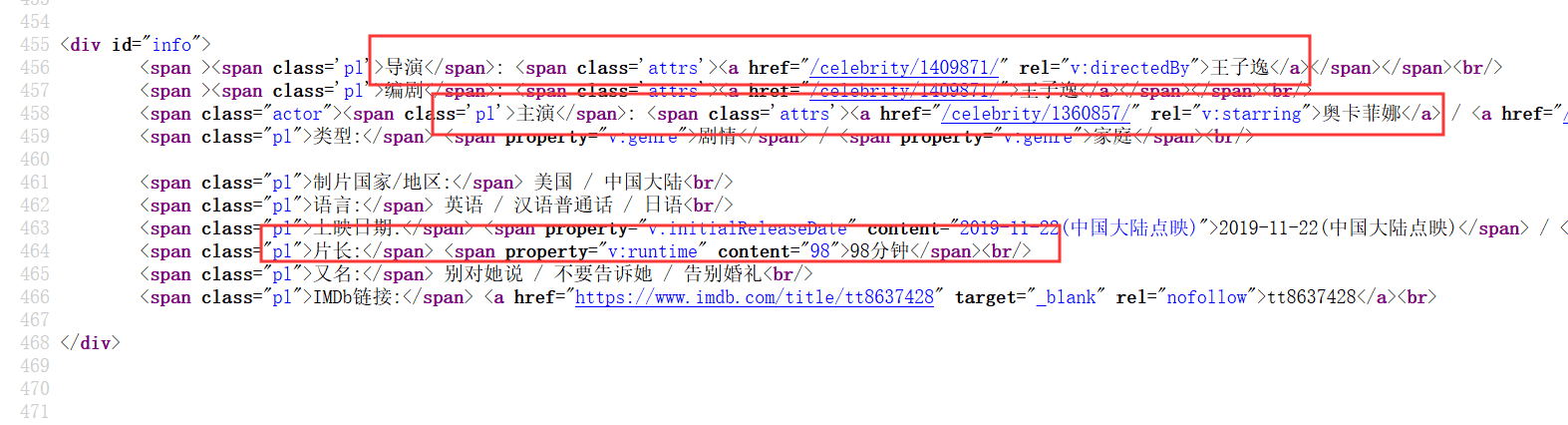
打开的详情页面,我们可以看到导演,主演和电影时长等信息。
我们查询详情页面的源代码,可以看到导演,主演,电影时长等信息的位置。
我们在通过HttpUtils类doGetHtml方法获取详情页面的数据,利用Jsoup进行解析,Jsoup是一个可以让java代码解析HTML代码的一个工具,可以参考一下Jsoup官网文档,找到主演,导演和电影时长信息。到这里我们需要的全部信息都获取到了,最后把数据保存起来。
测试类全部代码如下。
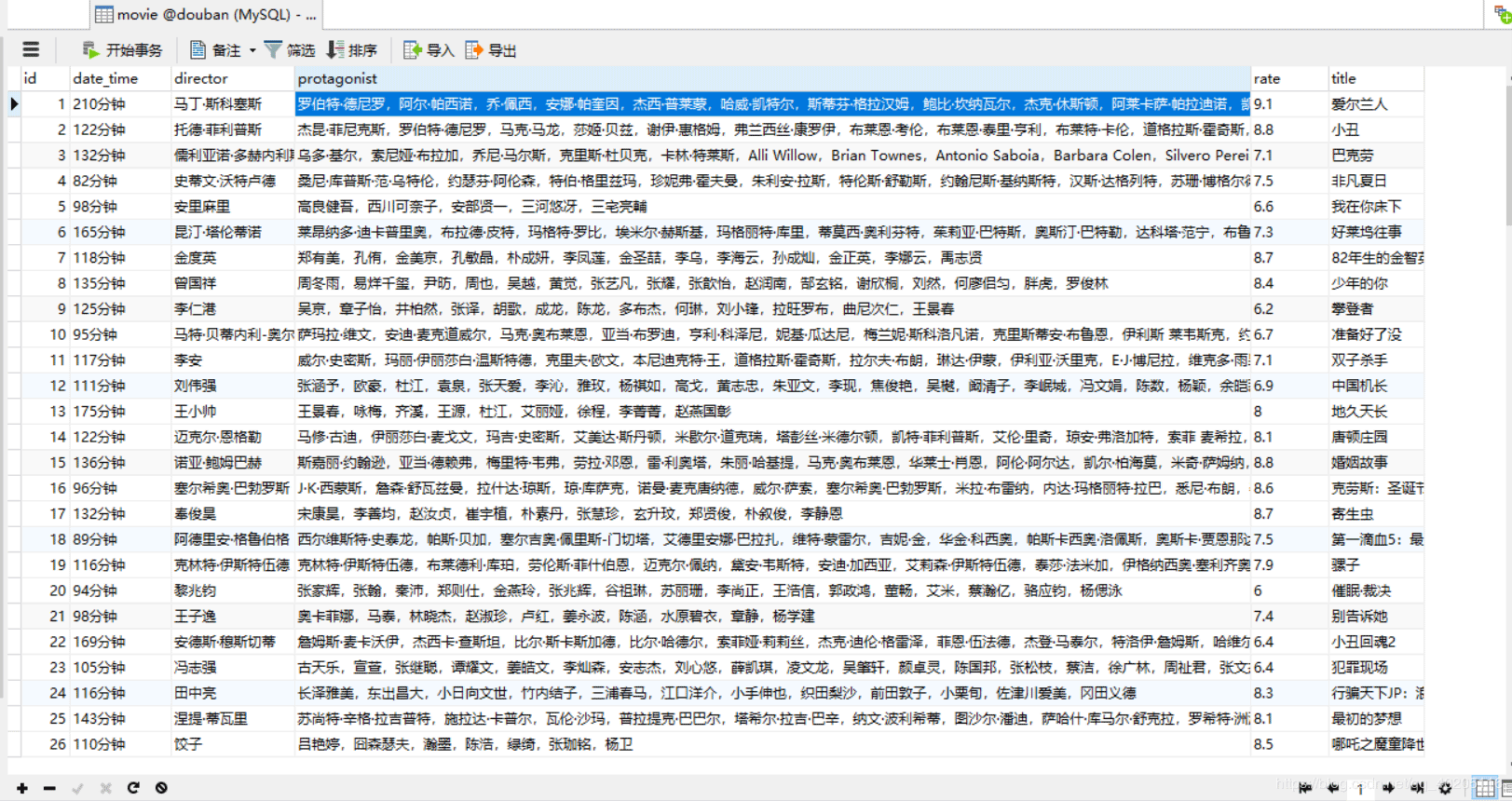
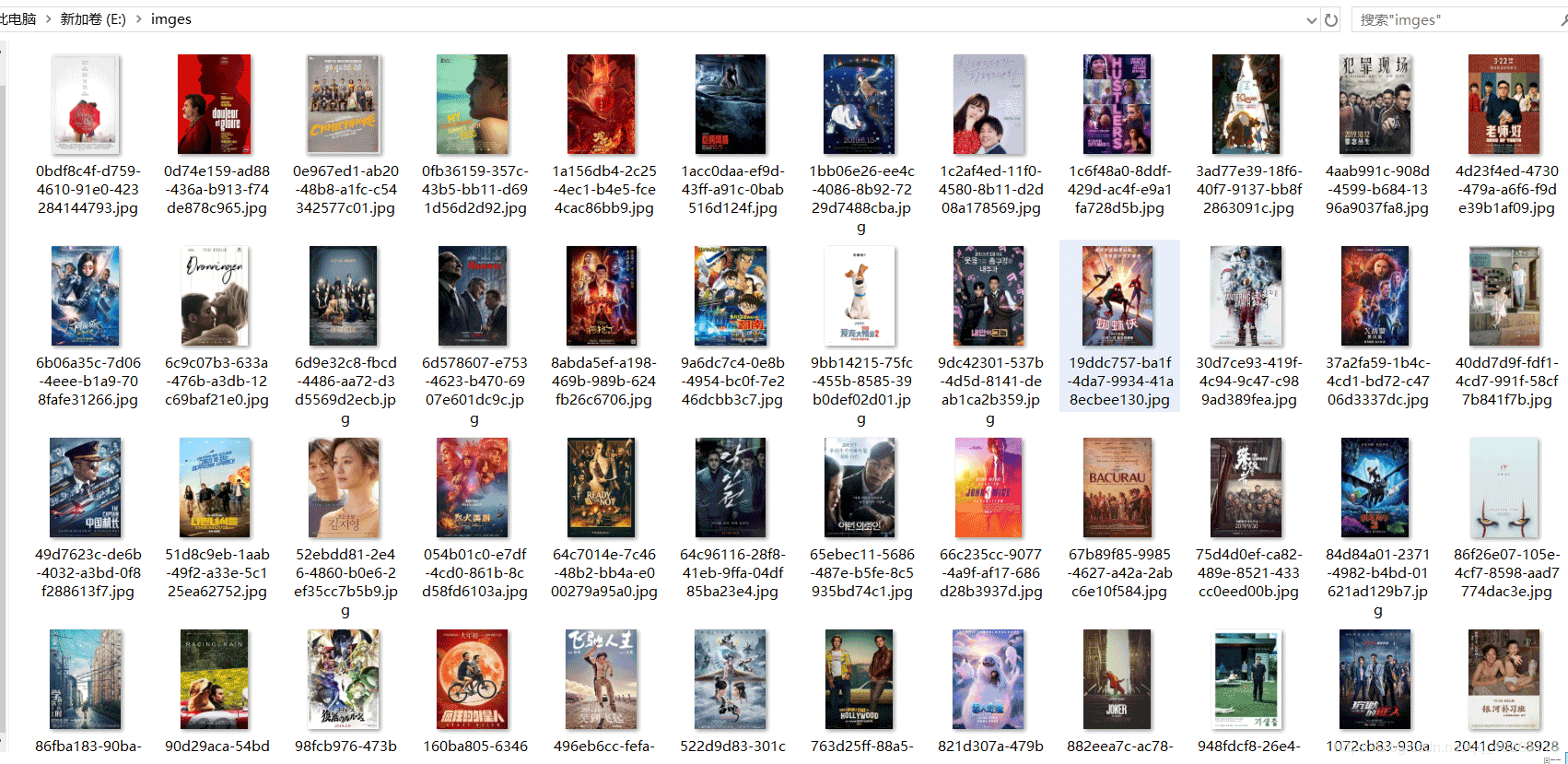
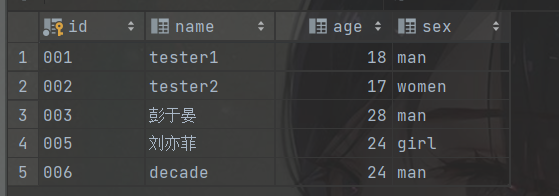
最后我们在mysql数据库中新建一个名为douban的数据库,启动项目,JPA会自动在数据库中新建一张movie表,存放获取到的电影数据。在本地磁盘也会保存电影图片,如图。
电影图片,保存的位置和HttpUtils的doGetImage方法中设置的保存地址一样。
最后放上下载地址https://github.com/machaoyin/crawler-douban |






2021-06-05
2021-05-27
2021-05-26
2021-06-05
2021-05-16