需求 读200+的CSV/EXCEL文件,按文件名称存到不同数据库 前期准备 环境 maven + jdk8 + mysql 代码展示 pom文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
需求读200+的CSV/EXCEL文件,按文件名称存到不同数据库 前期准备环境 maven + jdk8 + mysql 代码展示pom文件
关键代码及思路多线程处理数据,否则8k万数据太慢了 创建线程池,个数的大小一般取决于自己电脑配置,以及I/O还是CPU密集型。
数据进行分批处理,如果数据一次过大,可能导致sql拼接失败或者程序连接超时的问题。
获取文件数据
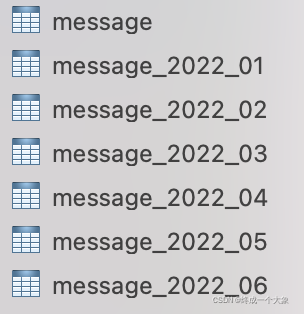
根据文件名创建相应数据库
注意:如果在主线程完成之后,没有对主线程进行阻塞,会导致线程池中的线程没跑完就直接结束了,需要遍历线程集合来阻塞主线程
关键的SQL语句saveOrUpdateBatch 这里选用Mysql提供的ON DUPLICATE KEY UPDATE来实现更新或者插入,如果primary key 或者 unique key不存在就插入,否则就更新。注意:primary key 和 unique key都存在的时候可能会导致数据的更新的异常,这里建议选其中一个最为键,否则容易死锁!见方案选型
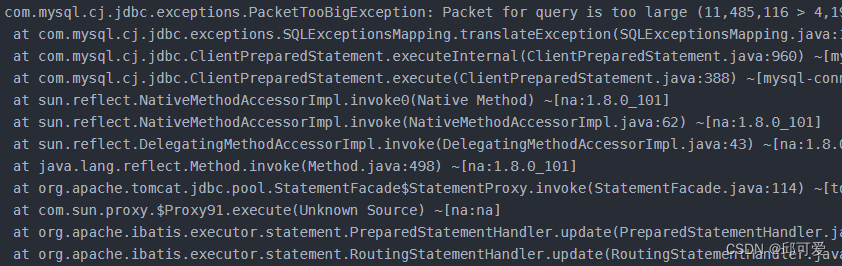
方案选型此方案时间过久,10多个小时大概能完成100w+的数据; 在程序中查询数据库中现存的数据,然后对这些数据进行更新,其余的进行插入 此方案程序代码看起来较繁琐。 选用 ON DUPLICATE KEY UPDATE & 多线程来实现批量处理。 问题 在处理最后一些数据时,报异常:获取不到数据库连接,连接超时
解决方案 修改application.yml的sql配置
当即存在primary key 以及 unique key时,出现了死锁 如果一个表定义有多个唯一键(包括唯一索引、主键)时,是不安全的。
解决方案 见上面关键SQL,删除了primary key 留下了unique key重新建表。 见上面关键SQL,删除了primary key 留下了unique key重新建表。 批量数据入库,当SQL语句拼接过长,超过了设置的最大的限制。
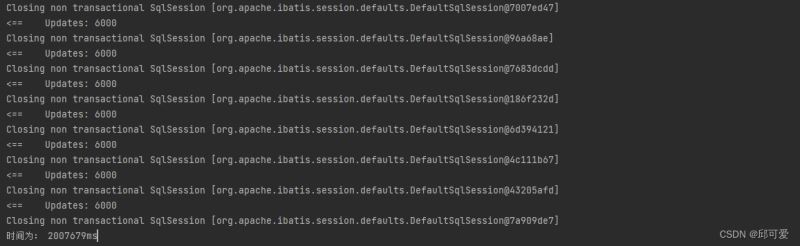
解决方案 批量数据入库时,稍微减少数据量再进行插入,如6000条数据减为4000数据之后再批量入库。 运行结果 相比之前一天200W+数据有了质的提升,半小时完成了所有数据的预处理以及入库。
|







2021-06-05
2021-05-27
2021-05-26
2021-06-05
2021-05-16