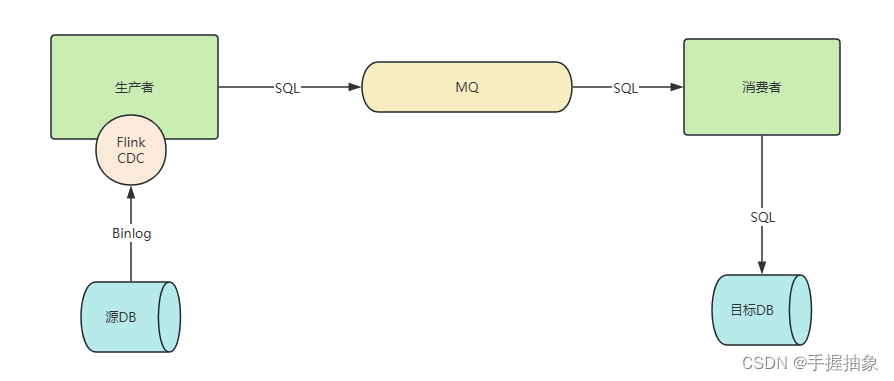
一、什么是 CDC ? CDC 是Change Data Capture(变更数据获取)的简称。 核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、 更新以及删除等),将这些变更按发生的顺序完整记录下
一、什么是 CDC ?CDC 是 Change Data Capture(变更数据获取) 的简称。 核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、 更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 二、Flink-CDC 是什么?CDC Connectors for Apache Flink是一组用于Apache Flink 的源连接器,使用变更数据捕获 (CDC) 从不同数据库获取变更。用于 Apache Flink 的 CDC 连接器将 Debezium 集成为捕获数据更改的引擎。所以它可以充分发挥 Debezium 的能力。 大概意思就是,Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、 PostgreSQL等数据库直接读取全量数据和增量变更数据的 source 组件。
Flink-CDC 开源地址: Apache/Flink-CDC Flink-CDC 中文文档:Apache Flink CDC | Apache Flink CDC 三、SpringBoot 整合 Flink-CDC3.1、如何集成到SpringBoot中?Flink 作业通常独立于一般的服务之外,专门编写代码,用 Flink 命令行工具来运行和停止。将Flink 作业集成到 Spring Boot 应用中并不常见,而且一般也不建议这样做,因为Flink作业一般运行在大数据环境中。 然而,在特殊需求下,我们可以做一些改变使 Flink 应用适应 Spring Boot 环境,比如在你的场景中使用 Flink CDC 进行 数据变更捕获。将 Flink 作业以本地项目的方式启动,集成在 Spring Boot应用中,可以使用到 Spring 的便利性。
3.2、集成举例1、CommandLineRunner
2、ApplicationRunner
这次用例采用 ApplicationRunner,不过要改变一下,让 Flink CDC 作为 Bean 来实现。 四、功能实现4.1、功能逻辑
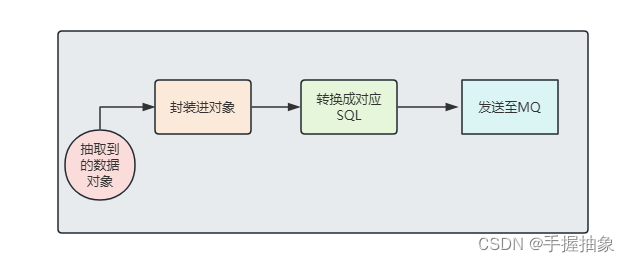
总体来讲,不太想把 Flink CDC单独拉出来,更想让它依托于一个服务上,彻底当成一个组件。 其中在生产者中,我们将要进行实现:
4.2、所需环境
4.3、Flink CDC POM依赖
上面是一些Flink CDC必须的依赖,当然如果需要实现其他数据库,可以替换其他数据库的CDC jar。怎么安排jar包的位置和其余需要的jar,这个可自行调整。 4.4、代码展示核心类
(1)通过 ApplicationRunner 接入 SpringBoot
(2)自定义 MySQL 消息读取序列化
(3)封装的变更对象
(4)定义 Flink 的 Sink
(5)数据转换类接口和实现类
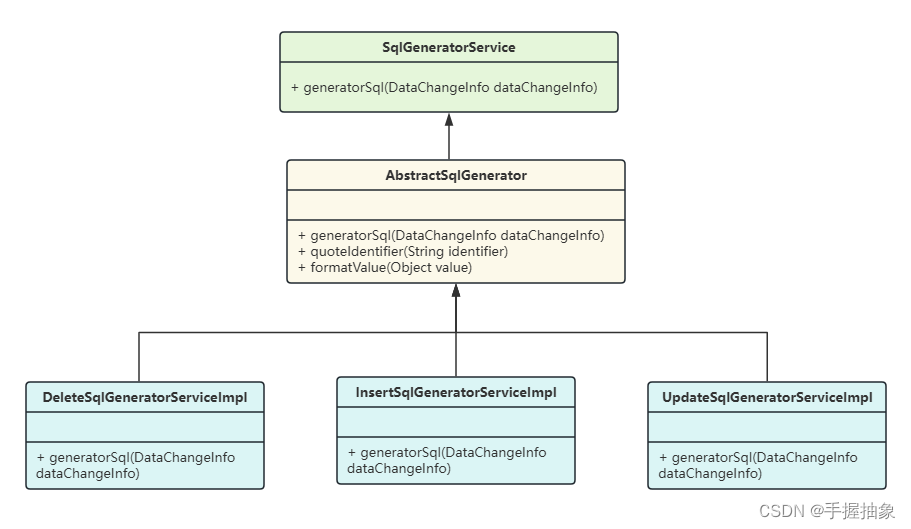
因为在 dataChangeInfo 中我们有封装对象的类型(CREATE、DELETE、UPDATE),所以我希望通过不同类来进行不同的工作。于是就有了下面的类结构:
根据 dataChangeInfo 的类型去生成对应的 SqlGeneratorServiceImpl。
值得注意的是,在 TableDataConvertServiceImpl 中,我们注入了一个 Map<String, SqlGeneratorService> sqlGeneratorServiceMap,通过它来进行具体实现类的获取。那么他是个什么东西呢?作用是什么呢?为什么可以通过它来获取呢? @Resource、@Autowired 标注作用于 Map 类型时,如果 Map 的 key 为 String 类型,则 Spring 会将容器中所有类型符合 Map 的 value 对应的类型的 Bean 增加进来,用 Bean 的 id 或 name 作为 Map 的 key。 那么可以看到下面第六步,在进行DeleteSqlGeneratorServiceImpl装配的时候进行指定了名字@Service("DELETE"),方便通过dataChangeInfo获取。 (6)转换类部分代码
核心代码如上所示,具体实现可自行设计。 五、源码获取Github:incremental-sync-flink-cdc |






2021-06-05
2021-05-27
2021-05-26
2021-06-05
2021-05-16