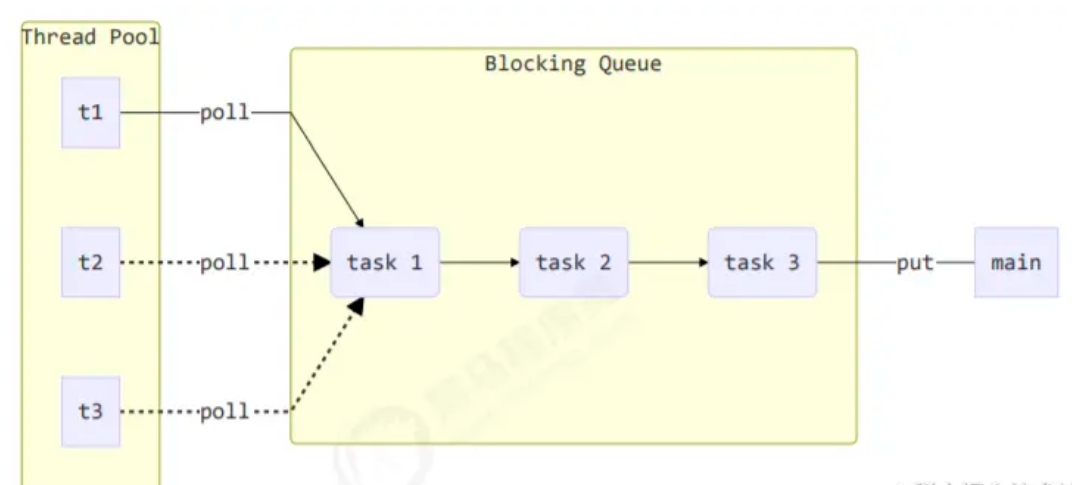
Java8的HashMap扩容过程主要就是集中在resize()方法中 final NodeK,V[] resize() { // ...省略不重要的} 其中,当HashMap扩容完毕之后,需要对原有的数据进行转移。因为容量变大了,部分元素的位置因此要变更,因而出现了下面的这个转移过程。 转移过程大致是
|
Java8的HashMap扩容过程主要就是集中在resize()方法中
其中,当HashMap扩容完毕之后,需要对原有的数据进行转移。因为容量变大了,部分元素的位置因此要变更,因而出现了下面的这个转移过程。 转移过程大致是:依次从旧数组里取值,然后从该值对应的链表上依次取出节点,对节点取模分别放入lo链表和hi链表,当链表中节点遍历完后,分别把lo链表和hi链表放入新数组的不同位置。 在看到如下第15行时,我在想,为什么(e.hash & oldCap)== 0时就放入lo链表,否则就是hi链表? 说到这个问题,那我们就要回顾下HashMap存入新元素的过程了。看下面的第45行,可以发现插入时是使用(n - 1) & hash来计算位置的,即数组长度-1,而扩容移位是使用数组长度n计算的,那这是为什么呢?
像我们看Java8的HashMap源码,应该都应该知道HashMap的底层数组长度都是2的n方的值 那么我们就假设一个底层数组长度为8的HashMap模拟进行插入元素和扩容移位的过程 长度n=8 ----> 0x1000 n-1 ----> 0x0111 此时写入两个元素,两个元素的hash值分别为hash1 = 0x0101,hash2 = 0x1101 hash1 & n-1 = 0x0101 hash2 & n-1 = 0x0101 两个hash取模后的结果是一致的,所以它们会在同一个地方组成链表 那么此时如果要进行扩容移位呢? hash1 & n = 0x0000 hash2 & n = 0x1000 此时两者的结果是不一样的,并且相差0x1000即10进制的8即数组长度.。 所以这也就是为什么上图15行只判断==0的原因,因为这个取模结果只有0和1两种值(数组长度是2的n次方,只有除了符号位外的最高位为1) 而两个取模结果等于数组长度,这也就是为什么上图第32和36行那么处理的原因。 |






2021-06-05
2021-05-27
2021-05-26
2021-06-05
2021-05-16