引言
JSON 的 stringify 和 parse 两个方法在平时的工作中也很常用,如果没有一些特殊的类型,是实现数据深拷贝的一个原生方式。
下面就这两个方法的一个手动实现思路。
JSON.stringify
JSON.stringify 方法用于将 JavaScript 值转换为 JSON 字符串。该方法有三个参数:
- data: 需要转换的数据
- replacer:用于转换结果的对象或者数组,可以函数或者数组
- space:文本添加缩进、空格和换行符,可以是数字或者字符串,数字的最大值是 10,字符串的最大长度是 10
下面的测试只用到这些类型:
number,string,function,object,array,null,undefined,map,set,weakmap,weakset
但是 JavaScript 数据的严格类型远远不止这几个。
data
首先我们用 JSON.stringify 来打印结果:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
const testJson = {
4: 3,
n: 1,
s: 's',
f: () => { },
null: null,
unde: undefined,
arr: [1, 's', null, undefined, () => { }],
obj: {
n: '1',
s: 's'
},
map: new Map(),
set: new Set([1, 2, 3]),
wmap: new WeakMap(),
wset: new WeakSet()
}
const raws = JSON.stringify(testJson)
// {
// "4":3,"n":1,"s":"s","null":null,"arr":[1,"s",null,null,null],
// "obj":{"n":"1","s":"s"},"map":{},"set":{},"wmap":{},"wset":{}
// }
|
根据上面的结果,我们可以发现对象内的 function, undefined 被剔除了,map, set 等都被动的转换成了空对象。而数组内的 function 和 undefined 被替换成了 null。
所以我们可以根据上述规则写一个简单的 stringify 方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
const stringify = (data: any) => {
// 获取数据的严格类型
const type = getType(data)
let res = ''
switch (type) {
case 'Object':
// 处理对象
res = stringifyObject(data, indent, replacer, space)
break
case 'Array':
// 处理数组
res = stringifyArray(data, indent, space)
break
case 'Number':
res = `${data}`
break
case 'String':
res = `"${data}"`
break
case 'Null':
res = 'null'
break
case 'Set':
case 'WeakSet':
case 'Map':
case 'WeakMap':
res = '{}'
break
default:
return
}
return res
}
|
实现几个辅助函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 获取严格类型
const getType = (data: any) => {
return Object.prototype.toString.call(data).slice(8, -1)
}
// 处理对象方法
const stringifyObject = (data: Record<string, any>) => {
const vals: string[] = []
for (const key in data) {
// 递归处理
const val = stringify(data[key])
// 如果值为 undefined,我们则需要跳过
if (val !== undefined) {
vals.push(`"${key}":${val}`)
}
}
return `{${vals.join(',')}}`
}
// 处理数组方法
const stringifyArray = (data: any[]) => {
const vals: any[] = []
for (const val of data) {
// 递归处理,如果返回 undefined 则替换为 null
vals.push(stringify(val) || 'null')
}
return `[${vals.join(',')}]`
}
|
到这里就实现了 stringify 的简单版本。下面可以简单测试一下:
|
1
2
3
|
const raws = JSON.stringify(testJson)
const cuss = stringify(testJson)
console.log(raws === cuss) // true
|
后面还有两个参数,我们先实现第三个,第二个参数的作用等下在实现。
space
space 主要是用于添加空格、换行、缩进,但是只要 space 的值是合法的,换行符是默认加上一个的。所以我们要改下 stringify 的方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
type Replacer = ((key: string, value: any) => any) | null | (string | number)[]
export const stringify = (data: any, replacer?: Replacer, space?: number | string, indent = 1) => {
const type = getType(data)
if (typeof space === 'number') {
if (space <= 0) {
space = undefined
} else {
space = Math.min(10, space)
}
} else if (typeof space === 'string') {
space = space.substring(0, 10)
} else if (space) {
space = undefined
}
let res = ''
switch (type) {
case 'Object':
res = stringifyObject(data, indent, replacer, space)
break
case 'Array':
res = stringifyArray(data, indent, space)
break
// 省略部分代码
}
// 省略部分代码
}
|
对于 space 的不同非法的值,我们可以在控制台上进行一些简单的测试就可以得出,像 -1 这种其实是不生效的。
而我处理的是只能是数字和字符串,数字必须是 1 - 10,字符串的最长长度是 10 位,其余的都重置为 undefined。
因为像数组和对象的这种嵌套,缩进其实是要跟着动的,这里就新增了 indent 字段,初始为 1,后续递归就 + 1。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
// 新增分隔符处理方法
const handleSeparator = (space: number | string, indent: number, prefix: string = '', suffix: string = '') => {
let separator = prefix + '\n'
if (typeof space === 'number') {
separator += ' '.repeat(space).repeat(indent)
} else {
separator += space.repeat(indent)
}
return separator + suffix
}
// 对象方法修改
const stringifyObject = (data: Record<string, any>, indent: number, replacer?: Replacer, space?: number | string) => {
const vals: string[] = []
for (const key in data) {
const val = stringify(data[key], null, space, indent + 1)
if (val !== undefined) {
vals.push(`"${key}":${space ? ' ' : ''}${val}`)
}
}
// 新增 space 处理
if (space) {
const val = vals.join(handleSeparator(space, indent, ','))
if (!val) {
return '{}'
}
const front = handleSeparator(space, indent, '{')
const back = handleSeparator(space, indent - 1, '', '}')
return front + val + back
}
return `{${vals.join(',')}}`
}
// 数组处理方法
const stringifyArray = (data: any[], indent: number, space?: number | string) => {
const vals: any[] = []
for (const val of data) {
vals.push(stringify(val) || 'null')
}
// 新增 space 处理
if (space) {
const front = handleSeparator(space, indent, '[')
const val = vals.join(handleSeparator(space, indent, ','))
const back = handleSeparator(space, indent - 1, '', ']')
return front + val + back
}
return `[${vals.join(',')}]`
}
|
replacer
replacer 参数有两个类型,数组类型是用来过滤对象类型内的字段,只保留数组内的 key,而函数类型有点奇怪,有点不明白,函数的参数是 key 和 value,初始的 key 为空, value 就是当前的对象的值。
所以这里我们需要修改两处地方:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
export const stringify = (data: any, replacer?: Replacer, space?: number | string, indent = 1) => {
// 如果 replacer 为函数的话,直接返回函数运行后的值
if (typeof replacer === 'function') {
return replacer('', data)
}
const type = getType(data)
// 省略部分代码
}
const stringifyObject = (data: Record<string, any>, indent: number, replacer?: Replacer, space?: number | string) => {
const filter = getType(replacer) === 'Array' ? replacer : null
const vals: string[] = []
for (const key in data) {
const val = stringify(data[key], null, space, indent + 1)
if (
val !== undefined &&
(
// 如果是数组,则当前的 key 必须是在 replacer 数组内
!filter ||
(filter as (string | number)[]).includes(key) ||
(filter as (string | number)[]).includes(+key)
)
) {
vals.push(`"${key}":${space ? ' ' : ''}${val}`)
}
}
// 省略部分代码
}
|
到这里, stringify 的方法差不多了。下面是完整代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
type Replacer = ((key: string, value: any) => any) | null | (string | number)[]
const getType = (data: any) => {
return Object.prototype.toString.call(data).slice(8, -1)
}
const handleSeparator = (space: number | string, indent: number, prefix: string = '', suffix: string = '') => {
let separator = prefix + '\n'
if (typeof space === 'number') {
separator += ' '.repeat(space).repeat(indent)
} else {
separator += space.repeat(indent)
}
return separator + suffix
}
const stringifyObject = (data: Record<string, any>, indent: number, replacer?: Replacer, space?: number | string) => {
const filter = getType(replacer) === 'Array' ? replacer : null
const vals: string[] = []
for (const key in data) {
const val = stringify(data[key], null, space, indent + 1)
if (
val !== undefined &&
(
!filter ||
(filter as (string | number)[]).includes(key) ||
(filter as (string | number)[]).includes(+key)
)
) {
vals.push(`"${key}":${space ? ' ' : ''}${val}`)
}
}
if (space) {
const val = vals.join(handleSeparator(space, indent, ','))
if (!val) {
return '{}'
}
const front = handleSeparator(space, indent, '{')
const back = handleSeparator(space, indent - 1, '', '}')
return front + val + back
}
return `{${vals.join(',')}}`
}
const stringifyArray = (data: any[], indent: number, space?: number | string) => {
const vals: any[] = []
for (const val of data) {
vals.push(stringify(val) || 'null')
}
if (space) {
const front = handleSeparator(space, indent, '[')
const val = vals.join(handleSeparator(space, indent, ','))
const back = handleSeparator(space, indent - 1, '', ']')
return front + val + back
}
return `[${vals.join(',')}]`
}
export const stringify = (data: any, replacer?: Replacer, space?: number | string, indent = 1) => {
if (typeof replacer === 'function') {
return replacer('', data)
}
const type = getType(data)
if (typeof space === 'number') {
if (space <= 0) {
space = undefined
} else {
space = Math.min(10, space)
}
} else if (typeof space === 'string') {
space = space.substring(0, 10)
} else if (space) {
space = undefined
}
let res = ''
switch (type) {
case 'Object':
res = stringifyObject(data, indent, replacer, space)
break
case 'Array':
res = stringifyArray(data, indent, space)
break
case 'Number':
res = `${data}`
break
case 'String':
res = `"${data}"`
break
case 'Null':
res = 'null'
break
case 'Set':
case 'WeakSet':
case 'Map':
case 'WeakMap':
res = '{}'
break
default:
return
}
return res
}
|
JSON.parse
stringify 方法的实现还是比较简单的,在一些笔试中还有可能会有相关需要实现的题。
而 JSON.parse 则是需要将合法的 json 字符串转换成对象,这里就需要用到一个概念:有限状态自动机
有限状态自动机
这里只做简单的介绍:有限状态机(Finite State Machine),是指任意时刻都处于有限状态集合中的某一状态。当其获得一个输入字符时,将从当前状态转换到另一个状态或者仍然保持当前状态。
可以结合当前 json 字符串的场景来简单理解一下:
我们有如下一个字符串:
|
1
|
const str = '{"4":3,"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
|
然后定义几个状态:
|
1
2
3
4
5
6
7
8
|
const State = {
INIT: 'INIT', // 初始状态
OBJECTSTART: 'OBJECTSTART', // 开始解析对象
ARRAYSTART: 'ARRAYSTART', // 开始解析数组
OBJVALSTART: 'OBJVALSTART', // 开始解析对象的属性与值
OBJVALEND: 'OBJVALEND', // 对象属性与值解析结束
ARRVALSTART: 'ARRVALSTART' // 开始解析数组值
}
|
因为 json 字符串是非常规则的字符串,所以我们可以结合正则表达式来提取相关步骤的数据,在字符串中的 ' '\t\n\r 等也是可以的,所以在正则中需要考虑并且替换。
|
1
2
3
4
5
6
7
8
9
|
const parse = (data: string | number | null) => {
if (typeof data === 'number' || data === null) {
return data
}
// 将字符串转换为地址引用,方便后面字符串数据的消费
const context = { data }
// 具体解析方法
return parseData(context)
}
|
然后定义几个辅助函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
// 字符串的消费函数 - 就是截取已匹配完的数据,返回剩余字符串
const advance = (context: { data: string }, num: number) => {
context.data = context.data.slice(num)
}
// 是否结束状态机
const isEnd = (ctx: { data: string }) => {
// 如果没有数据了,则结束
if (!ctx.data) {
return false
}
const match = /^(}|\])[ \t\n\r]*/.exec(ctx.data)
if (match) {
if (
match[1] === '}' && getType(res) !== 'Object' ||
match[1] === ']' && getType(res) !== 'Array'
) {
throw Error('解析错误')
}
advance(ctx, match[0].length)
return false
}
return true
}
// 解析对象属性值
const parseObjValue = (context: { data: string }) => {
const match = /^[ \n\t\r]*((".*?")|([0-9A-Za-z]*))[ \t\n\r]?/.exec(context.data)
if (match) {
advance(context, match[0].length)
const valMatch = /^"(.*?)"$/.exec(match[1])
if (valMatch) {
return valMatch[1]
}
if (match[1] === 'null') {
return null
}
if (isNaN(+match[1])) {
throw Error('解析错误')
}
return Number(match[1])
}
new Error('解析错误')
}
// 解析数组值
const parseArrValue = (context: { data: string }) => {
const refMatch = /^({|\][ \n\t\r]*)/.exec(context.data)
// 开启新的状态机
if (refMatch) {
return parseData(context)
}
const match = /^((".*?")|([0-9a-zA-Z]*))[ \n\t\r]*[,]?[ \n\t\r]*/.exec(context.data)
if (match) {
advance(context, match[0].length)
const valMatch = /^"(.*?)"$/.exec(match[1])
if (valMatch) {
return valMatch[1]
}
if (match[1] === 'null') {
return null
}
if (isNaN(+match[1])) {
throw Error('解析错误')
}
return Number(match[1])
}
throw Error('解析错误')
}
|
在上面定义状态的时候,解析对象、数组和数组值的时候只有开始状态,而没有结束状态。只是结束状态统一放入 isEnd 函数中,。
解析流程
下面开始定义 parseData 函数:
第一步
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
const parseData = (ctx: { data: string }) => {
let res: any = ''
let currentState = State.INIT
while (isEnd(ctx)) {
switch (CurrentState) {
case State.INIT:
{
const match = /^[ \t\n\r]*/.exec(ctx.data)
if (match?.[0].length) {
advance(ctx, match[0].length)
}
if (ctx.data[0] === '{') {
res = {}
currentState = State.OBJECTSTART
} else if (ctx.data[0] === '[') {
res = []
currentState = State.ARRAYSTART
} else {
res = parseObjValue(ctx)
}
}
break
case State.OBJECTSTART:
break
case State.OBJVALSTART:
break
case State.OBJVALEND:
break
case State.ARRAYSTART:
break
case State.ARRVALSTART:
break
// no default
}
}
return res
}
|
INIT 中,先去掉前面的空格、换行等字符,示例:
|
1
2
|
const str1 = ' \t\n\r{"4":3,"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
const str2 = '{"4":3,"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
|
然后再判读第一个字符是什么:
- 如果是 {,则将状态转移到 OBJECTSTART,将 res 赋值一个空对象
- 如果是 [,则将状态转移到 ARRAYSTART,将 res 赋值一个空数组
- 如果都不是,则就是一个值,可以用对象解析属性值的方法来解析,判读是否是合法的字符串
所以这里的状态转移到了对象解析 OBJECTSTART:
第二步
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
const parseData = (ctx: { data: string }) => {
let res: any = ''
let currentState = State.INIT
while (isEnd(ctx)) {
switch (CurrentState) {
case State.INIT:
// 省略部分代码
break
case State.OBJECTSTART:
{
const match = /^{[ \t\n\r]*/.exec(ctx.data)
if (match) {
advance(ctx, match[0].length)
currentState = State.OBJVALSTART
}
}
break
case State.OBJVALSTART:
break
case State.OBJVALEND:
break
case State.ARRAYSTART:
break
case State.ARRVALSTART:
break
// no default
}
}
return res
}
|
OBJECTSTART 中,消费掉 '{',将状态转移到 OBJVALSTART, 剩余字符数据:
|
1
|
const str = '"4":3,"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
|
第三步
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
const parseData = (ctx: { data: string }) => {
let res: any = ''
let currentState = State.INIT
while (isEnd(ctx)) {
switch (CurrentState) {
case State.INIT:
// 省略部分代码
break
case State.OBJECTSTART:
// 省略部分代码
break
case State.OBJVALSTART:
{
const match = /^"(.*?)"[ \n\t\r]*:[ \n\t\r]*/.exec(ctx.data)
if (match) {
advance(ctx, match[0].length)
if (ctx.data[0] === '{' || ctx.data[0] === '[') {
res[match[1]] = parseData(ctx)
} else {
res[match[1]] = parseObjValue(ctx)
}
currentState = State.OBJVALEND
}
}
break
case State.OBJVALEND:
break
case State.ARRAYSTART:
break
case State.ARRVALSTART:
break
// no default
}
}
return res
}
|
先获取 key: 等数组并消费,剩余字符数据:
|
1
|
const str = '3,"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
|
先判读后续字符的第一个字符是什么:
- 如果是 { 或者 [,则开启一个新的状态机
- 否则直接用 parseObjValue 解析值
最后将状态转移至 OBJVALEND。
第四步
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
const parseData = (ctx: { data: string }) => {
let res: any = ''
let currentState = State.INIT
while (isEnd(ctx)) {
switch (CurrentState) {
case State.INIT:
// 省略部分代码
break
case State.OBJECTSTART:
// 省略部分代码
break
case State.OBJVALSTART:
// 省略部分代码
break
case State.OBJVALEND:
{
const match = /^[ \t\n\r]*([,}\]])[ \t\n\r]*/.exec(ctx.data)
if (match) {
if (match[1] === ',') {
currentState = State.OBJVALSTART
}
advance(ctx, match[0].length)
}
}
break
case State.ARRAYSTART:
break
case State.ARRVALSTART:
break
// no default
}
}
return res
}
|
如果后面匹配出来的字符是 ,,则表示后续还有其它的对象属性,我们需要将状态重新转移到 OBJVALSTART, 如果是其它的 } 或者 ],则会在此次消费完毕,然后在 isEnd 中会退出状态机。
后续剩余字符的变化会依照上数状态的变化而进行字符消费:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
const str = '3,"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
// 1
const str = ',"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
// 2
const str = '"s":"s","null":null,"arr":[1,"s",null],"obj":{}}'
// 省略 s 和 null
// 3 开启新的状态机
const str = '[1,"s",null],"obj":{}}'
// 4 结束状态机
const str = '],"obj":{}}'
// 5 开启新的状态机
const str = '{}}'
// 6 结束状态机
const str = '}}'
// 7 结束状态机
const str = '}'
|
数组的处理
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
const parseData = (ctx: { data: string }) => {
let res: any = ''
let currentState = State.INIT
while (isEnd(ctx)) {
switch (CurrentState) {
case State.INIT:
// 省略部分代码
break
case State.OBJECTSTART:
// 省略部分代码
break
case State.OBJVALSTART:
// 省略部分代码
break
case State.OBJVALEND:
// 省略部分代码
break
case State.ARRAYSTART:
{
const match = /^\[[ \t\n\r]*/.exec(ctx.data)
if (match) {
advance(ctx, match[0].length)
currentState = State.ARRVALSTART
}
}
break
case State.ARRVALSTART:
res.push(parseArrValue(ctx))
break
// no default
}
}
return res
}
|
如果第一个字符为 [,则会开启新的状态机,状态也会转换为 ARRAYSTART,然后在 ARRAYSTART 状态内进行数组值的转换。
到这里整个 JSON.parse 的实现思路差不多,但是上述的流程应该有没考虑到的地方,但是大体差不多,只是边界的处理问题。测试示例:
|
1
2
3
4
5
6
7
|
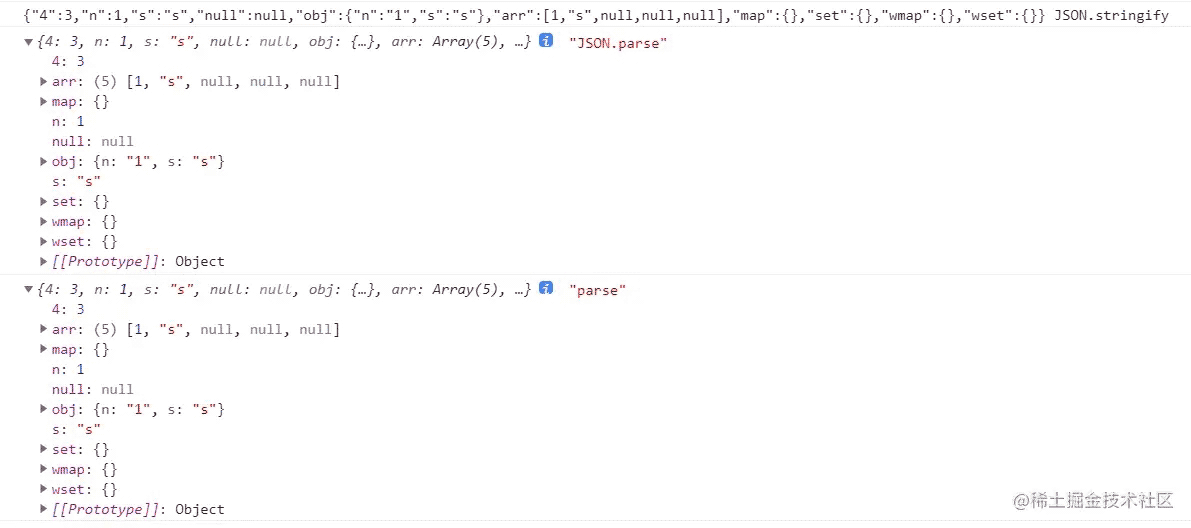
// 数据使用上面的 testJson
const raws = JSON.stringify(testJson)
const rawp = JSON.parse(raws)
const cusp = parse(raws)
console.log(raws, 'JSON.stringify')
console.log(rawp, 'JSON.parse')
console.log(cusp, 'parse')
|
结果:
完整代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
|
const State = {
INIT: 'INIT',
OBJECTSTART: 'OBJECTSTART',
ARRAYSTART: 'ARRAYSTART',
OBJVALSTART: 'OBJVALSTART',
OBJVALEND: 'OBJVALEND',
ARRVALSTART: 'ARRVALSTART'
}
const isEnd = (ctx: { data: string }, res: any) => {
if (!ctx.data) {
return false
}
const match = /^(}|\])[ \t\n\r]*/.exec(ctx.data)
if (match) {
if (
match[1] === '}' && getType(res) !== 'Object' ||
match[1] === ']' && getType(res) !== 'Array'
) {
throw Error('解析错误')
}
advance(ctx, match[0].length)
return false
}
return true
}
const advance = (context: { data: string }, num: number) => {
context.data = context.data.slice(num)
}
const parseObjValue = (context: { data: string }) => {
const match = /^[ \n\t\r]*((".*?")|([0-9A-Za-z]*))[ \t\n\r]?/.exec(context.data)
if (match) {
advance(context, match[0].length)
const valMatch = /^"(.*?)"$/.exec(match[1])
if (valMatch) {
return valMatch[1]
}
if (match[1] === 'null') {
return null
}
if (isNaN(+match[1])) {
throw Error('解析错误')
}
return Number(match[1])
}
new Error('解析错误')
}
const parseArrValue = (context: { data: string }) => {
const refMatch = /^({|\][ \n\t\r]*)/.exec(context.data)
if (refMatch) {
return parseData(context)
}
const match = /^((".*?")|([0-9a-zA-Z]*))[ \n\t\r]*[,]?[ \n\t\r]*/.exec(context.data)
if (match) {
advance(context, match[0].length)
const valMatch = /^"(.*?)"$/.exec(match[1])
if (valMatch) {
return valMatch[1]
}
if (match[1] === 'null') {
return null
}
if (isNaN(+match[1])) {
throw Error('解析错误')
}
return Number(match[1])
}
throw Error('解析错误')
}
const parseData = (ctx: { data: string }) => {
let res: any = ''
let currentState = State.INIT
while (isEnd(ctx, res)) {
switch (currentState) {
case State.INIT:
{
const match = /^[ \t\n\r]*/.exec(ctx.data)
if (match?.[0].length) {
advance(ctx, match[0].length)
}
if (ctx.data[0] === '{') {
res = {}
currentState = State.OBJECTSTART
} else if (ctx.data[0] === '[') {
res = []
currentState = State.ARRAYSTART
} else {
res = parseObjValue(ctx)
}
}
break
case State.OBJECTSTART:
{
const match = /^{[ \t\n\r]*/.exec(ctx.data)
if (match) {
advance(ctx, match[0].length)
currentState = State.OBJVALSTART
}
}
break
case State.OBJVALSTART:
{
const match = /^"(.*?)"[ \n\t\r]*:[ \n\t\r]*/.exec(ctx.data)
if (match) {
advance(ctx, match[0].length)
if (ctx.data[0] === '{' || ctx.data[0] === '[') {
res[match[1]] = parseData(ctx)
} else {
res[match[1]] = parseObjValue(ctx)
}
currentState = State.OBJVALEND
}
}
break
case State.OBJVALEND:
{
const match = /^[ \t\n\r]*([,}\]])[ \t\n\r]*/.exec(ctx.data)
if (match) {
if (match[1] === ',') {
currentState = State.OBJVALSTART
}
advance(ctx, match[0].length)
}
}
break
case State.ARRAYSTART:
{
const match = /^\[[ \t\n\r]*/.exec(ctx.data)
if (match) {
advance(ctx, match[0].length)
currentState = State.ARRVALSTART
}
}
break
case State.ARRVALSTART:
res.push(parseArrValue(ctx))
break
// no default
}
}
return res
}
export const parse = (data: string | number | null) => {
if (typeof data === 'number' || data === null) {
return data
}
const context = { data }
return parseData(context)
}
|
|