在前端Web开发中,下载文件是一个很常见的需求,也有一些比较特殊的Case,比如下载文件请求是一个POST、url不是同源的、批量下载文件等。本文就介绍下几种download解决方案,以及特殊
|
在前端Web开发中,下载文件是一个很常见的需求,也有一些比较特殊的Case,比如下载文件请求是一个POST、url不是同源的、批量下载文件等。本文就介绍下几种download解决方案,以及特殊Case的最佳方案选择。 单个文件Download方案一:location.href or window.open
缺点: 1.只支持get请求,不支持post请求。 2.浏览器会根据header的content-type来判断是下载文件还是预览文件。 比如 txt png 等格式文件,会在当前tab或新tab中预览,而不是下载下来。 3.由于只支持get,会有url参数过长问题。 4.不能加request header,无法做权限验证等逻辑。 5.不支持自定义file name。 方案二:通过a标签的download属性通过HTML a标签的原生属性,使用浏览器下载。 https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/a#attr-download
优点:
缺点:
方案三:API请求API发送请求的方式,获取文件blog对象,然后通过URL.createObjectURL方法获取download url,然后用方案二的<a download />方式下载。
URL.createObjectURL 生成的url如果过多会有效率问题,可以在合适的时机(download后)释放掉。参考:developer.mozilla.org/zh-CN/docs/…
优点:
缺点:
多个文件批量Download有些需求是,点一个按钮需要把多个文件同时download下来,有以下几个方案可以实现。 方案一:按单个文件download方式,循环依次下载
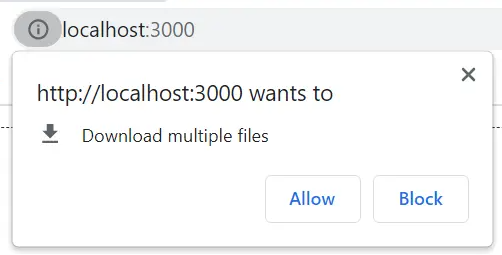
利用上面的方案二的<a download />方式下载,会触发浏览器是Download multiple files提示,如果选了Allow则会正常下载。
尝试每个download之间加延迟,依然会弹提示。这个应该是浏览器机制问题了,没办法避免了。 方案二:前端打包成zip download前端可以通过一个第三方库 jszip,可以把多个文件以blob、base64或纯文本等形式,按自定义的文件结构,压缩成一个zip文件,然后通过浏览器download下来。 官网:stuk.github.io/jszip/ 用法不难,直接看code:
jszip还支持一些别的类型文件压缩,比如纯文本、base64、binary等等,详见:https://stuk.github.io/jszip/documentation/api_jszip/file_data.html 由于走的是纯前端压缩,所以会有延迟问题,走到最后download时才会调起浏览器下载,所以页面可能需要一个效果来更新压缩进度。zip.generateAsync方法就支持第二个参数,支持进度更新:
方案三:后端压缩成zip,然后以文件流url形式,前端调用download后台加个api,然后把需要download的文件在后台压缩成zip,然后把文件流输出出来。然后就和单个文件download一样了。 因为后台会先压缩,会有延迟才会把blob返回前台,而且需要传多个文件信息,一般是post请求,所以建议使用单个文件下载的方案三通过API请求实现,在请求前后加上提示语或loading效果。 总结本文介绍了前端单个文件的下载方案,以及批量多个文件下载的解决方案。最后整理下方案建议: 单个文件下载:
批量文件下载:
|




2021-06-04
2019-01-10
2019-02-17
2021-09-12
2021-09-30