前言 有玩过爬虫的人应该都有过在又臭又长的HTML中找寻信息的经历,虽然有各种工具和各种框架可以辅助查找,但是解析HTML的规则也是人想的,制定规则也是十分麻烦的。 恰好在个人
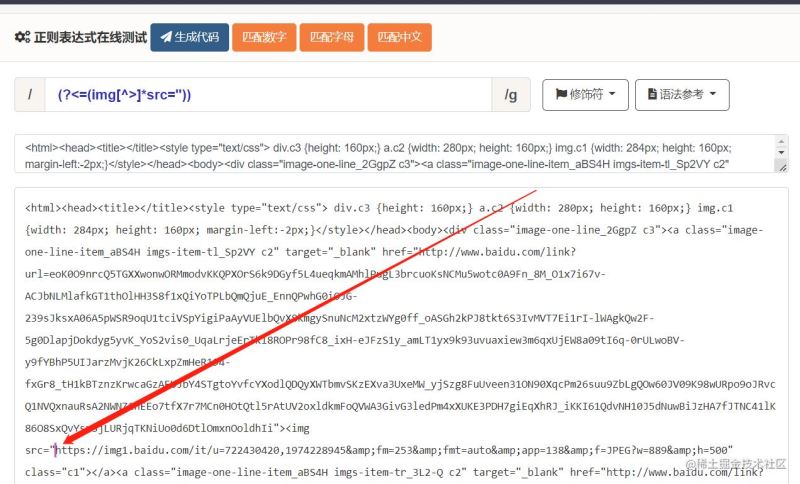
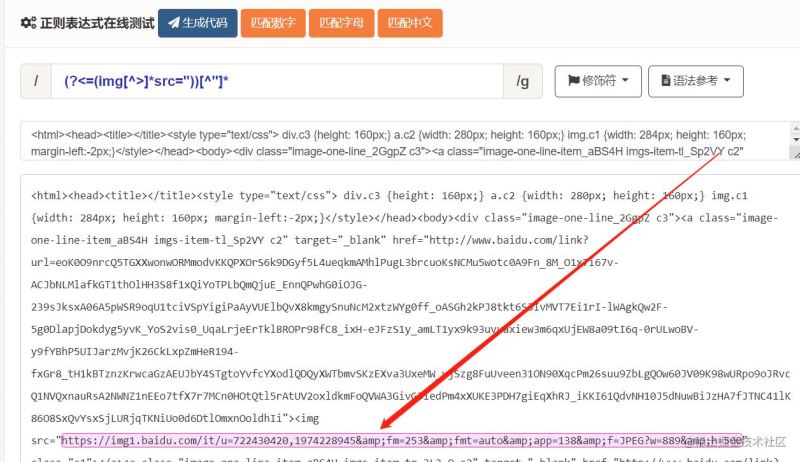
前言有玩过爬虫的人应该都有过在又臭又长的HTML中找寻信息的经历,虽然有各种工具和各种框架可以辅助查找,但是解析HTML的规则也是人想的,制定规则也是十分麻烦的。 分析每个网站中展示图片的地方,无非就是img标签或者style中background-image和background,先解决img标签中的图片。 然后,就是匹配src后面的地址,匹配地址的方法已经有许多文章描述过了,不再多说,但本文中用了一个比较取巧的方式去匹配。 总的思路就是先匹配src的位置,在获取图片地址。 正则表达式
可以看到,能够成功找到图片地址的开头位置。
|




2021-06-04
2019-05-27
2022-10-12
2022-10-12
2019-06-26