1.正则表达式的基本语法 1.1两个特殊符号 ^ 和 $ ^ 正则表达式的起始符 ^tom 表示所有以tom开头的字符串 $ 正则表达式的结束符 lucy$ 表示所有以lucy结束的字符串 ^$ 结合使用 ^tom$ 表示以
1.正则表达式的基本语法1.1两个特殊符号 ‘^’ 和 ‘$’^ 正则表达式的起始符
$ 正则表达式的结束符
^$ 结合使用
不使用 ^$
1.2 出现次数的表示符号 * + ?* 表示出现 0次 或者 至少1次 + 表示出现 至少1次 ? 表示出现 0次 或者 1次
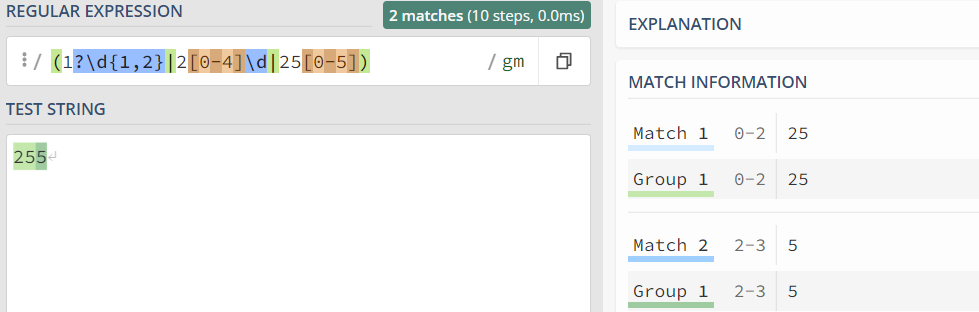
1.3 指定出现次数的范围 {}使用{m,n} 表示出现次数的范围 m–至少出现m次 n–最多出现n次 举例如下
1.4 “或” 操作 |
1.5 替代任意字符的 . 英文句号
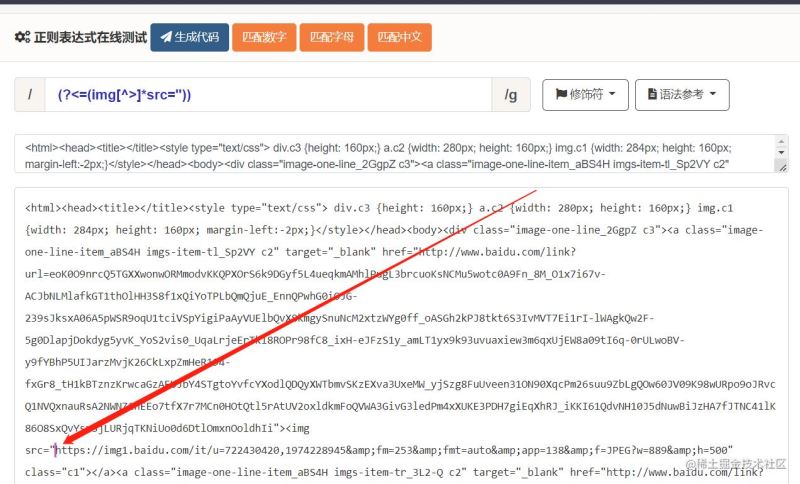
1.6 方括号的使用 [][] 方括号表示某些字符允许在一个字符串中某一个特定位置出现
方括号[]中使用 ^ ,表示不希望出现字符,简称过滤字符,而且 ^ 必须用在[]中的第一位
1.7 小括号 () 的作用1.7.1 限定量词作用的范围
1.7.2 分支结构
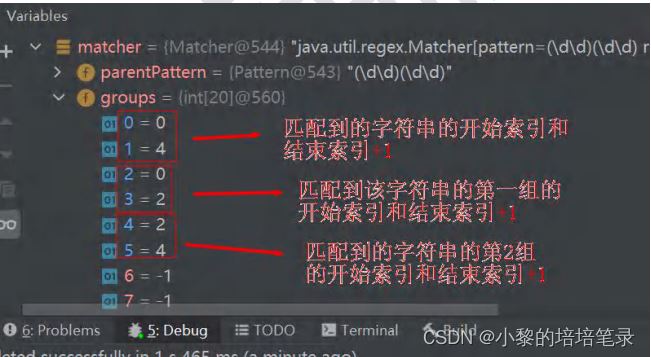
1.7.3 引用分组这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。 而要使用它带来的好处,必须配合使用实现环境的API。 以日期为例。假设格式是yyyy-mm-dd的,我们可以先写一个简单的正则:
1.7.4提取数据
1.7.5替换比如,想把yyyy-mm-dd格式,替换成mm/dd/yyyy怎么做?
1.7.6反向引用
还是以日期为例。 比如要写一个正则支持匹配如下三种格式: 2016-06-12 2016/06/12 2016.06.12 最先可能想到的正则是:
其中/和.需要转义。虽然匹配了要求的情况,但也匹配"2016-06/12"这样的数据。 假设我们想要求分割符前后一致怎么办?此时需要使用反向引用:
注意里面的\1,表示的引用之前的那个分组(-|/|.)。不管它匹配到什么(比如-),\1都匹配那个同样的具体某个字符。 我们知道了\1的含义后,那么\2和\3的概念也就理解了,即分别指代第二个和第三个分组。 看到这里,此时,恐怕你会有三个问题。 括号嵌套怎么办? 以左括号(开括号)为准。比如:
我们可以看看这个正则匹配模式: 第一个字符是数字,比如说1, 第二个字符是数字,比如说2, 第三个字符是数字,比如说3, 接下来的是\1,是第一个分组内容,那么看第一个开括号对应的分组是什么,是123, 接下来的是\2,找到第2个开括号,对应的分组,匹配的内容是1, 接下来的是\3,找到第3个开括号,对应的分组,匹配的内容是23, 最后的是\4,找到第3个开括号,对应的分组,匹配的内容是3。 这个问题,估计仔细看一下,就该明白了。 \10表示什么呢? 另外一个疑问可能是,即\10是表示第10个分组,还是\1和0呢?答案是前者,虽然一个正则里出现\10比较罕见。测试如下:
引用不存在的分组会怎样? 因为反向引用,是引用前面的分组,但我们在正则里引用了不存在的分组时,此时正则不会报错,只是匹配反向引用的字符本身。例如\2,就匹配"\2"。注意"\2"表示对2进行了转意。
chrome浏览器打印的结果:
1.7.7非捕获分组之前文中出现的分组,都会捕获它们匹配到的数据,以便后续引用,因此也称他们是捕获型分组。 如果只想要括号最原始的功能,但不会引用它,即,既不在API里引用,也不在正则里反向引用。此时可以使用非捕获分组(?:p),例如本文第一个例子可以修改为:
1.7.8 操作实例字符串trim方法模拟
将每个单词的首字母转换为大写
驼峰化
中划线化
html转义和反转义
匹配成对标签
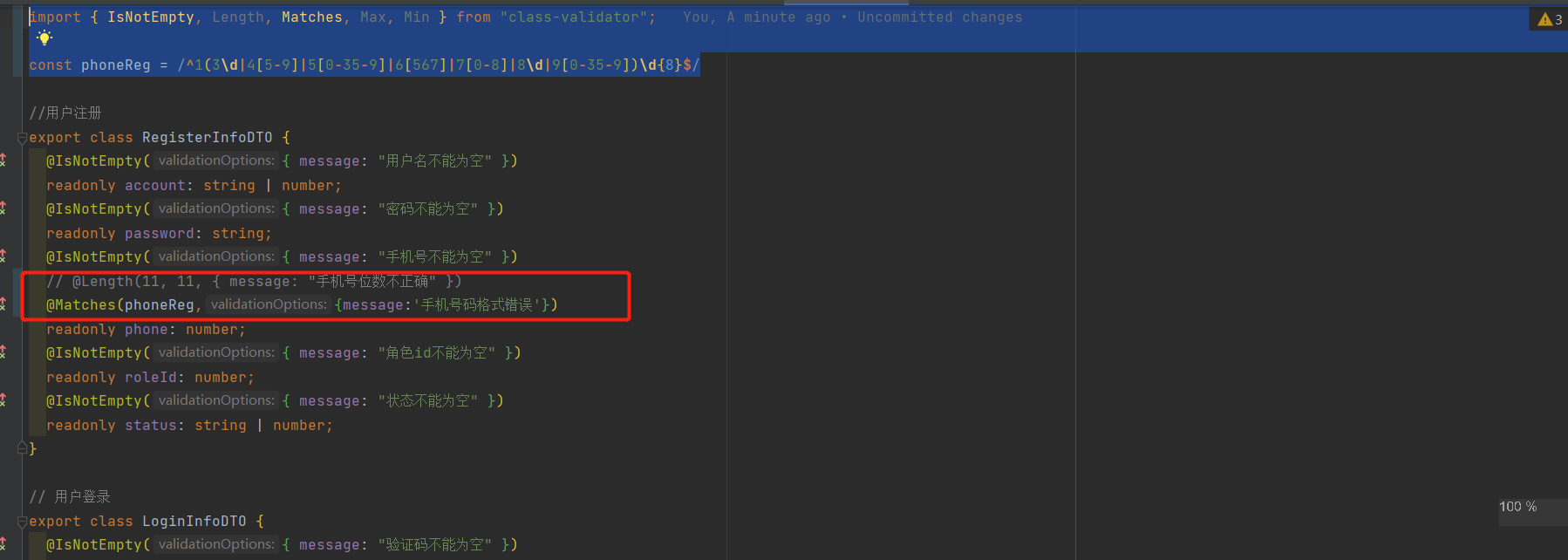
2. 常用的正则表达式
参考文档https://www.jb51.net/article/73342.htm https://zhuanlan.zhihu.com/p/27355118 |




2021-06-04
2019-05-27
2022-10-12
2022-10-12
2019-06-26