一、有多少个匹配
1. 匹配一个或多个字符(+)
要想匹配某个字符(或字符集合)的一次或多次重复,只要简单地在其后面加上一个 + 字符就行了。+ 匹配一个或多个字符(至少一个;不匹配零个字符的情况)。比如,a 匹配 a 本身,a+ 匹配一个或多个连续出现的 a。类似地,[0-9] 匹配任意单个数字,[0-9]+ 匹配一个或多个连续的数字。
在给一个字符集合加上 + 后缀的时候,必须把 + 放在这个字符集合的外面。比如说,[0-9]+ 是正确的,[0-9+]则不正确。[0-9+] 其实也是一个有效的正则表达式,但它匹配的不是一个或多个数字,它定义了一个由数字 0 到 9 和 + 构成的字符集合,因而只能匹配单个的数字字符或加号。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> set @s:='Send personal email to ben@forta.com. For questions
'> about a book use support@forta.com. Feel free to send
'> unsolicited email to spam@forta.com (wouldn\'t it be
'> nice if it were that simple, huh?).';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='\\w+@\\w+\\.\\w+';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_count(@s, @r, '') c, regexp_extract(@s, @r, '') s, regexp_extract_index(@s, @r, 0, '') i;
+------+------------------------------------------------+-----------+
| c | s | i |
+------+------------------------------------------------+-----------+
| 3 | ben@forta.com,support@forta.com,spam@forta.com | 24,70,128 |
+------+------------------------------------------------+-----------+
1 row in set (0.01 sec)
|
该模式正确地匹配到了所有的 3 个电子邮件地址。这个正则表达式先用第一个 \w+ 匹配一个或多个字母数字字符,再用第二个 \w+ 匹配 @ 后面的一个或多个字符,然后匹配一个 . 字符(使用转义序列 \.),最后用第三个 \w+ 匹配电子邮件地址的剩余部分。
+ 是一个元字符。如果需要匹配 + 本身,就必须使用转义序列 \+。+ 还可以用来匹配一个或多个字符集合。为了演示这种用法,在下面这个例子里使用了和刚才一样的正则表达式,但文本内容和上一个例子中稍有不同。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> set @s:='Send personal email to ben@forta.com or
'> ben.forta@forta.com. For questions about a
'> book use support@forta.com. If your message
'> is urgent try ben@urgent.forta.com. Feel
'> free to send unsolicited email to
'> spam@forta.com (wouldn\'t it be nice if
'> it were that simple, huh?).';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_count(@s, @r, '') c, regexp_extract(@s, @r, '') s, regexp_extract_index(@s, @r, 0, '') i;
+------+---------------------------------------------------------------------------------+------------------+
| c | s | i |
+------+---------------------------------------------------------------------------------+------------------+
| 5 | ben@forta.com,forta@forta.com,support@forta.com,ben@urgent.forta,spam@forta.com | 24,45,93,142,203 |
+------+---------------------------------------------------------------------------------+------------------+
1 row in set (0.01 sec)
|
这个正则表达式匹配到了 5 个电子邮件地址,但其中有 2 个不够完整。为什么会这样?因为 \w+@\w+\.\w+ 并没有考虑到 @ 之前的 . 字符,它只允许 @ 之后的两个字符串之间出现单个 . 字符。尽管 ben.forta@forta.com 是一个完全有效的电子邮件地址,但该正则表达式只能匹配 forta(而不是 ben.forta),因为 \w 只能匹配字母数字字符,无法匹配出现在字符串中间的 . 字符。在这里,需要匹配 \w 或 .。用正则表达式语言来说,就是匹配字符集合 [\w.]。下面是改进版本。
|
1
2
3
4
5
6
7
8
9
10
|
mysql> set @r:='[\\w.]+@[\\w.]+\\.\\w+';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_count(@s, @r, '') c, regexp_extract(@s, @r, '') s, regexp_extract_index(@s, @r, 0, '') i;
+------+-----------------------------------------------------------------------------------------+------------------+
| c | s | i |
+------+-----------------------------------------------------------------------------------------+------------------+
| 5 | ben@forta.com,ben.forta@forta.com,support@forta.com,ben@urgent.forta.com,spam@forta.com | 24,41,93,142,203 |
+------+-----------------------------------------------------------------------------------------+------------------+
1 row in set (0.01 sec)
|
新的正则表达式看起来用了些技巧。[\w.]+ 匹配字母数字字符、下划线和 . 的一次或多次重复出现,而 ben.forta 完全符合这一条件。@ 字符之后也用到了 [\w.]+,这样就可以匹配到层级更深的域(或主机)名。注意 这个正则表达式的最后一部分是 \w+ 而不是 [\w.]+。如果把 [\w.] 用作这个模式的最后一部分,在第二、第三和第四个匹配上就会出问题。
这里没有对字符集合 [\w.] 里的 . 字符进行转义,但依然能够匹配 . 字符。一般来说,当在字符集合里使用的时候,像 . 和 + 这样的元字符将被解释为普通字符,不需要转义,但转义了也没有坏处。[\w.] 的使用效果与 [\w\.] 是一样的。
2. 匹配零个或多个字符(*)
+ 匹配一个或多个字符,但不匹配零个字符,+ 最少也要匹配一个字符。如果想匹配一个可有可无的字符,也就是该字符可以出现零次或多次的情况,需要用 * 元字符来完成。* 的用法与 + 完全一样,只要把它放在某个字符(或字符集合)的后面,就可以匹配该字符(或字符集合)出现零次或多次的情况。比如说,模式 B.* Forta 将匹配 B Forta、B. Forta、Ben Forta 以及其他组合。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
mysql> set @s:='Hello .ben@forta.com is my email address.';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='[\\w.]+@[\\w.]+\\.\\w+';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_count(@s, @r, '') c, regexp_extract(@s, @r, '') s, regexp_extract_index(@s, @r, 0, '') i;
+------+----------------+------+
| c | s | i |
+------+----------------+------+
| 1 | .ben@forta.com | 7 |
+------+----------------+------+
1 row in set (0.01 sec)
|
[\w.]+ 匹配字母数字字符、下划线和 . 的一次或多次重复出现,而 .ben 完全符合这一条件。文本里多了一个 .,把它用作电子邮件地址的第一个字符就无效了。换句话说,需要匹配的其实是带有可选的额外字符的字母数字文本,就像下面这样。
|
1
2
3
4
5
6
7
8
9
10
|
mysql> set @r:='\\w+[\\w.]*@[\\w.]+\\.\\w+';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_count(@s, @r, '') c, regexp_extract(@s, @r, '') s, regexp_extract_index(@s, @r, 0, '') i;
+------+----------------+------+
| c | s | i |
+------+----------------+------+
| 1 | ben@forta.com | 8 |
+------+----------------+------+
1 row in set (0.01 sec)
|
\w+ 匹配任意单个字母数字字符,但不包括 .,这些是可以作为电子邮件地址起始的有效字符。经过开头部分若干个有效字符之后,也许会出现一个 . 和其他额外的字符,不过也可能没有。[\w.]* 匹配 . 或字母数字字符的零次或多次重复出现。可以把 * 理解为一种“使其可选”(make it optional)的元字符。+ 需要最少匹配一次,而 * 可以匹配多次,也可以一次都不匹配。* 是一个元字符。如果需要匹配 * 本身,就必须使用转义序列 \*。
3. 匹配零个或一个字符(?)
另一个非常有用的元字符是 ?。和 + 一样,? 能够匹配可选文本(所以就算文本没有出现,也可以匹配)。但与 + 不同,? 只能匹配某个字符(或字符集合)的零次或一次出现,最多不超过一次。? 非常适合匹配一段文本中某个特定的可选字符。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
mysql> set @s:='The URL is http://www.forta.com/, to connect
'> securely use https://www.forta.com/ instead.';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='http://[\\w./]+';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_count(@s, @r, '') c, regexp_extract(@s, @r, '') s, regexp_extract_index(@s, @r, 0, '') i;
+------+-----------------------+------+
| c | s | i |
+------+-----------------------+------+
| 1 | http://www.forta.com/ | 12 |
+------+-----------------------+------+
1 row in set (0.01 sec)
|
该模式用来匹配 URL 地址:http:// 加上 [\w./]+(匹配字母数字字符、.和/的一次或多次重复出现)。这个模式只能匹配第一个 URL 地址。简单地在 http 的后面加上一个 s*(s的零次或多次重复)并不能真正解决这个问题,因为这样也能匹配 httpsssss://,显然是无效的URL。可以在 http 的后面加上一个 s?。
|
1
2
3
4
5
6
7
8
9
10
|
mysql> set @r:='https?://[\\w./]+';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_count(@s, @r, '') c, regexp_extract(@s, @r, '') s, regexp_extract_index(@s, @r, 0, '') i;
+------+----------------------------------------------+-------+
| c | s | i |
+------+----------------------------------------------+-------+
| 2 | http://www.forta.com/,https://www.forta.com/ | 12,59 |
+------+----------------------------------------------+-------+
1 row in set (0.01 sec)
|
该模式的开头部分是 https?://。? 在这里的含义是:前面的字符 s 要么不出现,要么最多出现一次。换句话说,https?:// 既可以匹配 http://,也可以匹配 https://。? 还可以解决不同平台匹配不同换行符的问题。例如 Windows 使用 \r\n,Unix或Linux系统上使用 \n,理想的解决方案是匹配一个可选的 \r 和一个 \n。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> set @s:='"101","Ben","Forta"
'> "102","Jim","James"
'>
'> "103","Roberta","Robertson"
'> "104","Bob","Bobson"';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='[\\r]?\\n[\\r]?\\n';
Query OK, 0 rows affected (0.00 sec)
mysql> select @r r , regexp_replace(@s,@r,'\n') s;
+----------------+------------------------------------------------------------------------------------------+
| r | s |
+----------------+------------------------------------------------------------------------------------------+
| [\r]?\n[\r]?\n | "101","Ben","Forta"
"102","Jim","James"
"103","Roberta","Robertson"
"104","Bob","Bobson" |
+----------------+------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
|
[\r]?\n 匹配一个可选的 \r 和一个必不可少的 \n。上面这个例子里的正则表达式使用的是 [\r]? 而不是 \r?。[\r] 定义了一个字符集合,该集合只有元字符 \r 这一个成员,因而 [\r]? 在功能上与 \r? 完全等价。[ ] 的常规用法是把多个字符定义为一个集合,但有不少程序员喜欢把一个字符也定义为一个集合。这么做的好处是可以增加可读性和避免产生误解,让人们一眼就可以看出随后的元字符应用于谁。如果打算同时使用 [ ] 和 ?,记得把 ? 放在字符集合的外面。因此,http[s]?:// 是正确的,若是写成 http[s?]://可就不对了。? 是一个元字符。如果需要匹配 ? 本身,就必须使用转义序列 \?。
二、匹配的重复次数
正则表达式里的 +、* 和 ? 解决了许多问题,但有时候光靠它们还不够。+ 和 * 匹配的字符个数没有上限,无法为其匹配的字符个数设定一个最大值。+、* 和 ? 匹配的字符最小数量是零个或一个,无法明确地为其匹配的字符个数另行设定一个最小值。无法指定具体的匹配次数。
为了解决这些问题并对重复性匹配有更多的控制权,正则表达式允许使用重复范围(interval)。重复范围在 { 和 } 之间指定。{ 和 } 是元字符,如果需要匹配自身,就应该用 \ 对其进行转义。
1. 具体的重复匹配
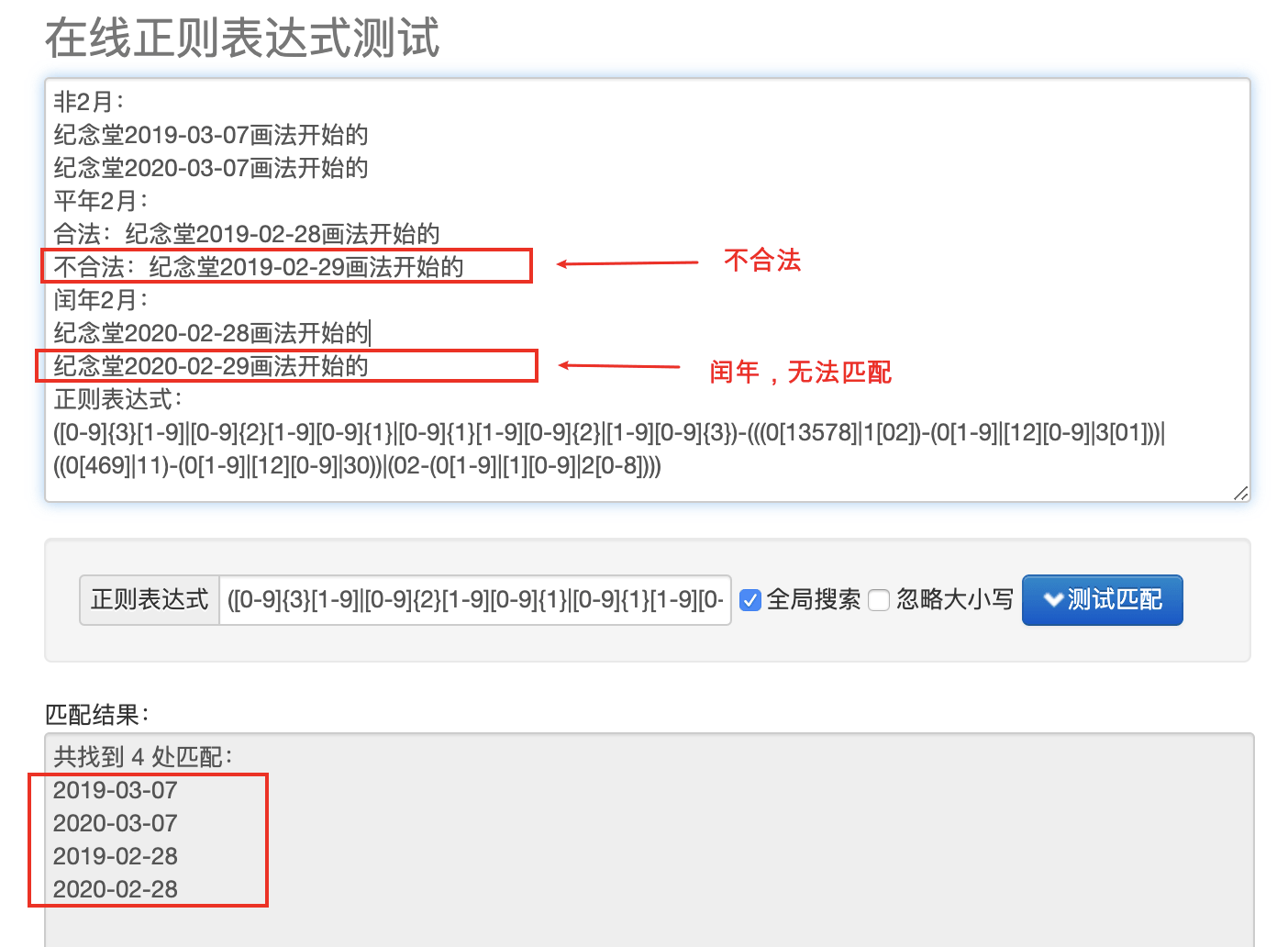
要想设置具体的匹配次数,把数字写在 { 和 } 之间即可。比如说,{3} 意味着匹配前一个字符(或字符集合)3 次。如果只能匹配 2 次,则不算是匹配成功。为了演示这种用法,再来看一下匹配 RGB 值的例子。RGB 值是一个十六进制数值,这个值分成 3 个部分,每个部分包括两位十六进制数字。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
mysql> set @s:='body {
r, 0, '');
'> background-color: #fefbd8;
'> }
'> h1 {
'> background-color: #0000ff;
'> }
'> div {
'> background-color: #d0f4e6;
'> }
'> span {
'> background-color: #f08970;
'> }';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='#[A-Fa-f0-9]{6}';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_extract(@s, @r, ''), regexp_extract_index(@s, @r, 0, '');
+---------------------------------+-------------------------------------+
| regexp_extract(@s, @r, '') | regexp_extract_index(@s, @r, 0, '') |
+---------------------------------+-------------------------------------+
| #fefbd8,#0000ff,#d0f4e6,#f08970 | 30,68,107,147 |
+---------------------------------+-------------------------------------+
1 row in set (0.00 sec)
|
[A-Fa-f0-9] 匹配单个十六进制字符,{6} 要求重复匹配该字符 6 次。区间匹配的用法也适用于 POSIX 字符类。
2. 区间范围
{} 语法还可以用来为重复匹配次数设定一个区间范围,也就是匹配的最小次数和最大次数。区间必须以{2,4}(最少重复2次,最多重复4次)这样的形式给出。下面的例子使用一个这样的正则表达式来检查日期的格式。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> set @s:='4/8/17
'> 10-6-2018
'> 2/2/2
'> 01-01-01';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='\\d{1,2}[-/]\\d{1,2}[-/]\\d{2,4}';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_extract(@s, @r, ''), regexp_extract_index(@s, @r, 0, '');
+----------------------------+-------------------------------------+
| regexp_extract(@s, @r, '') | regexp_extract_index(@s, @r, 0, '') |
+----------------------------+-------------------------------------+
| 4/8/17,10-6-2018,01-01-01 | 1,8,24 |
+----------------------------+-------------------------------------+
1 row in set (0.00 sec)
|
这里列出的日期是一些由用户可能通过表单字段输入的值,这些值必须先进行验证,确保格式正确。\d{1,2} 匹配一个或两个数字字符(匹配天数和月份);\d{2,4} 匹配年份;[-/] 匹配日期分隔符 - 或 /。总共匹配到了 3 个日期值,2/2/2 不在此列,因为它的年份太短了。
上面这个例子里的模式并不能验证日期的有效性,诸如 54/67/9999 之类的无效日期也能通过这一测试。它只能用来检查日期值的格式是否正确,这一环节通常安排在日期有效性验证之前。
重复范围也可以从 0 开始。比如,{0,3} 表示重复次数可以是 0、1、2 或 3。我们曾经讲过,? 匹配它之前某个字符(或字符集合)的零次或一次出现。因此从效果上看,其等价于{0,1}。
3. 匹配“至少重复多少次”
重复范围的最后一种用法是指定至少要匹配多少次(不指定最大匹配次数)。这种用法的语法类似于区间范围语法,只是省略了最大值部分而已。比如说,{3,}表示至少重复3次,换句话说,就是“重复3次或更多次”。来看一个例子,使用一个正则表达式把所有金额大于或等于100美元的订单找出来。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
mysql> set @s:='1001: $496.80
'> 1002: $1290.69
'> 1003: $26.43
'> 1004: $613.42
'> 1005: $7.61
'> 1006: $414.90
'> 1007: $25.00';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='\\d+: \\$\\d{3,}\\.\\d{2}';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_extract(@s, @r, ''), regexp_extract_index(@s, @r, 0, '');
+----------------------------------------------------------+-------------------------------------+
| regexp_extract(@s, @r, '') | regexp_extract_index(@s, @r, 0, '') |
+----------------------------------------------------------+-------------------------------------+
| 1001: $496.80,1002: $1290.69,1004: $613.42,1006: $414.90 | 1,15,43,69 |
+----------------------------------------------------------+-------------------------------------+
1 row in set (0.00 sec)
|
这个例子里的文本取自一份报表,其中第一列是订单号,第二列是订单金额。正则表达式首先使用 \d+: 来匹配订单号(这部分其实可以省略——可以只匹配金额部分而不是包括订单号在内的一整行)。模式 \$\d{3,}\.\d{2} 用来匹配金额部分,其中 \$ 匹配 $,\d{3,} 匹配至少 3 位数字(因此,最少也得是100美元),\. 匹配 .,\d{2} 匹配小数点后面的 2 位数字。该模式从所有订单中正确地匹配到了 4 个符合要求的订单。
在使用重复范围的时候一定要小心。如果遗漏了花括号里的逗号,那么模式的含义将从至少匹配 n 次变成只匹配 n 次。+ 在功能上等价于{1,}。
三、防止过度匹配
? 的匹配范围有限(仅限零次或一次匹配),当使用精确数量或区间时,重复范围匹配也是如此。但本篇介绍的其他重复匹配形式在重复次数方面都没有上限值,而这样做有时会导致过度匹配的现象。考虑下面这个例子,例子中的文本取自某个 Web 页面,里面包含两个 HTML 的 <b> 标签。任务是用正则表达式匹配 <b> 标签中的文本。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
mysql> set @s:='This offer is not available to customers
'> living in <b>AK</b> and <b>HI</b>.';
Query OK, 0 rows affected (0.00 sec)
mysql> set @r:='<[Bb]>.*</[Bb]>';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_extract(@s, @r, ''), regexp_extract_index(@s, @r, 0, '');
+----------------------------+-------------------------------------+
| regexp_extract(@s, @r, '') | regexp_extract_index(@s, @r, 0, '') |
+----------------------------+-------------------------------------+
| <b>AK</b> and <b>HI</b> | 52 |
+----------------------------+-------------------------------------+
1 row in set (0.01 sec)
|
<[Bb]> 匹配起始 <b> 标签,</[Bb]> 匹配闭合 </b> 标签。但这个模式只找到了一个匹配,而不是预期的两个。第一个 <b> 标签和最后一个 </b> 标签之间的所有内容被 .* 一网打尽。这的确包含了想要匹配的文本,但其中也夹杂了其他标签。
为什么会这样?因为 * 和 + 都是所谓的“贪婪型”(greedy)元字符,其匹配行为是多多益善而不是适可而止。它们会尽可能地从一段文本的开头一直匹配到末尾,而不是碰到第一个匹配时就停止。这是有意设计的,量词就是贪婪的(+、* 和 ? 也叫作“量词”)。
在不需要这种“贪婪行为”的时候,该使用这些量词的“懒惰型”(lazy)版本。之所以称之为“懒惰型”是因为其匹配尽可能少的字符,而非尽可能多地去匹配。懒惰型量词的写法是在贪婪型量词后面加上一个 ?。下表列出了贪婪型量词及其对应的懒惰型版本。
|
贪婪型量词
|
懒惰型量词
|
|
*
|
*?
|
|
+
|
+?
|
|
{n,}
|
{n,}?
|
下面是使用 *? 来解决之前那个例子的做法。
|
1
2
3
4
5
6
7
8
9
10
|
mysql> set @r:='<[Bb]>.*?</[Bb]>';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_extract(@s, @r, ''), regexp_extract_index(@s, @r, 0, '');
+----------------------------+-------------------------------------+
| regexp_extract(@s, @r, '') | regexp_extract_index(@s, @r, 0, '') |
+----------------------------+-------------------------------------+
| <b>AK</b>,<b>HI</b> | 52,66 |
+----------------------------+-------------------------------------+
1 row in set (0.00 sec)
|
因为使用了懒惰型的 *?,第一个匹配将仅限于<b>AK</b>,<b>HI</b>则成为了第二个匹配。
|