
利用正则表达式从字符串中提取浮点数

在 Python 中,使用正则表达式可以非常方便地从字符串中提取浮点数。Python 的re模块提供了正则表达式支持。下面是如何使用正则表达式提取浮点数的示例。 1、问题背景 在开发过程中,有时候
|
在 Python 中,使用正则表达式可以非常方便地从字符串中提取浮点数。Python 的 re 模块提供了正则表达式支持。下面是如何使用正则表达式提取浮点数的示例。
1、问题背景在开发过程中,有时候我们需要从字符串中提取浮点数,例如从 HTML 代码中提取价格信息。但是,浮点数的格式可能多种多样,例如带有逗号分隔符的数字或带有美元符号前缀的数字。因此,我们需要一种方法来处理各种格式的浮点数。 2、解决方案我们可以使用正则表达式来提取浮点数。正则表达式是一种强大的文本处理工具,可以用于查找、替换和提取字符串中的信息。 以下是如何使用正则表达式从字符串中提取浮点数的示例:
输出: 12.99 在上面的示例中,正则表达式模式 r"[-+]?\d+(?:\.\d*)?" 匹配任何带有可选的正负号、整数部分和小数部分的数字。 re.search() 函数用于在字符串中搜索匹配正则表达式模式的子字符串。如果找到匹配项,则返回一个 Match 对象,否则返回 None。 Match 对象的 group() 方法用于获取匹配项的值。 上面的示例只演示了如何从字符串中提取一个浮点数。如果字符串中有多个浮点数,则可以使用正则表达式 findall() 函数来提取所有匹配项。 以下是如何使用正则表达式 findall() 函数从字符串中提取所有浮点数的示例:
输出:
在上面的示例中,正则表达式 findall() 函数返回一个包含所有匹配项值的列表。 我们还可以使用正则表达式来提取带有逗号分隔符的浮点数。以下是如何使用正则表达式从字符串中提取带有逗号分隔符的浮点数的示例:
输出:
在上面的示例中,正则表达式模式 r"[-+]?(?:\d+(?:\.\d*)?|\.\d+),(?:\d+(?:\.\d*)?|\.\d+)" 匹配任何带有可选的正负号、整数部分和小数部分的数字,并允许逗号分隔符。 我们还可以使用正则表达式来提取带有美元符号前缀的浮点数。以下是如何使用正则表达式从字符串中提取带有美元符号前缀的浮点数的示例:
输出:
在上面的示例中,正则表达式模式 r"\$[+-]?(?:\d+(?:\.\d*)?|\.\d+)" 匹配任何带有美元符号前缀的数字,并允许可选的正负号、整数部分和小数部分。 这个正则表达式可以识别包括正数、负数和小数的浮点数。我们可以根据需要调整正则表达式,以适应更多的浮点数格式,例如科学计数法或无小数点的整数等。 |

您可能感兴趣的文章 :

-
正则表达式匹配URL的方法
正则表达式匹配 URL 教程 1. 引言 正则表达式(Regex)是一种用于文本匹配和处理的强大工具。在实际开发中,我们经常需要用正则表达式来 -

正则表达式常见密码验证方式总结大全
一、基础正则表达式 1.1 至少1个大写字母 (?=.*?[A-Z]) 1.2 至少1个小写英文字母 (?=.*?[a-z]) 1.2 至少1位数字 (?=.*?[0-9]) 1.2 至少有1个特殊字符 (?= -
正则表达式必知必会之重复匹配详细介绍
一、有多少个匹配 1. 匹配一个或多个字符(+) 要想匹配某个字符(或字符集合)的一次或多次重复,只要简单地在其后面加上一个 + 字符 -
正则表达式中的$分组使用示例介绍
正则表达式中的$符号通常用于表示字符串的结束位置,但当你在替换操作或者某些特殊上下文中提到$后跟数字(如$1,$2, etc.),这并不表示 -

日期校验/时间校验正则表达式深入解析(超实用
以下为常用的日期格式校验表达式 0.1 日期格式校验 以下日期校验可满足四年一闰,百年不闰,四百年再闰 yyyyMMdd 1 ^(?:(?!0000)[0-9]{4}(?:(?:0[ -
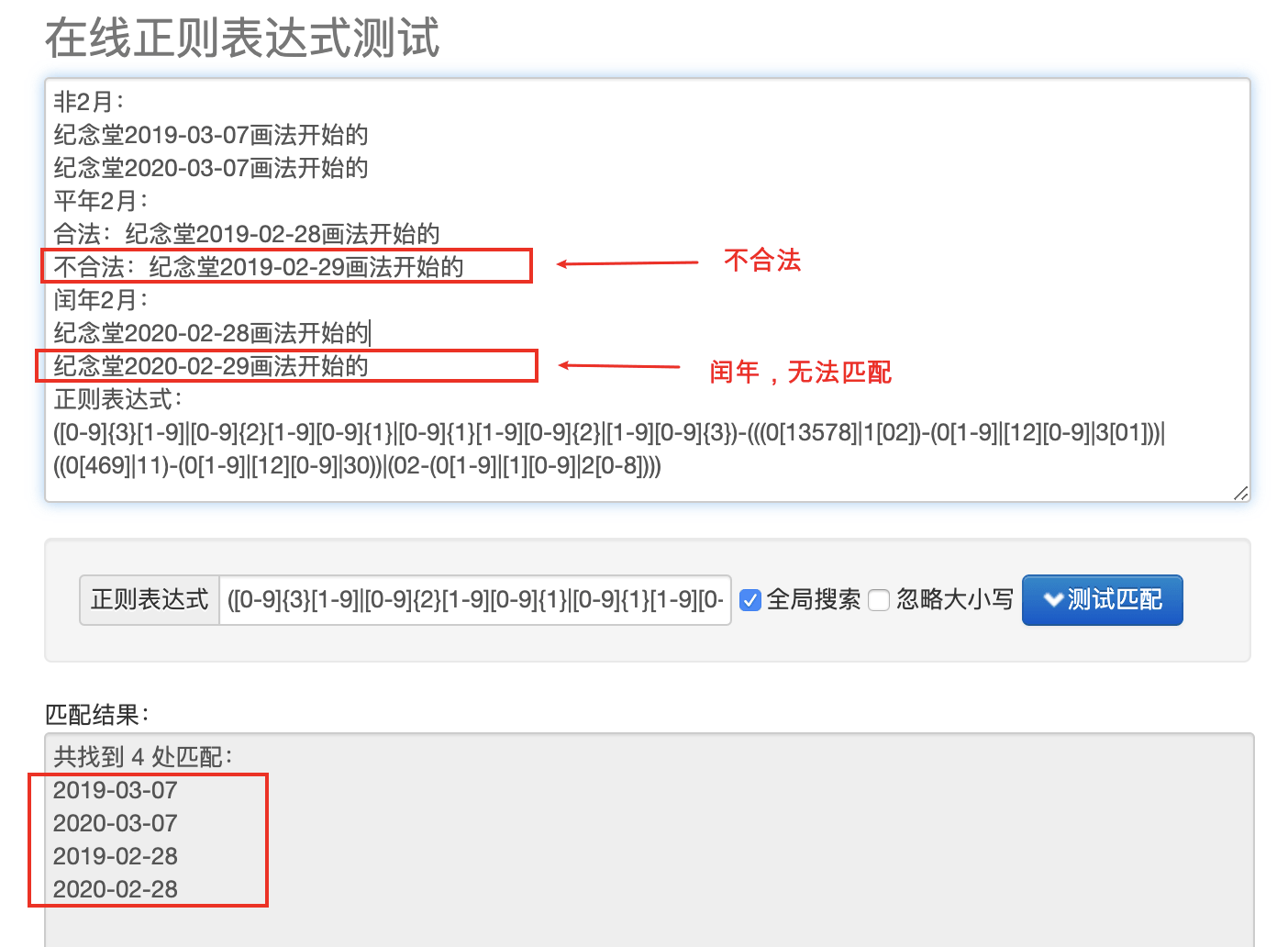
常用日期格式正则表达式详解(完善版)
第一步,验证年份 年份范围为 0001 - 9999,匹配YYYY的正则表达式为: 1 [0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3} 第二步,验证月 -
正则表达式校验日期时间格式的方法
日期部分校验 概念 首先,我们先了解2个概念: 1、合法的日期范围: DateTime值类型表示值范围在公元(基督纪元)0001 年 1 月 1 日午夜 12





-
Java正则表达式里隐藏的陷阱
2021-06-04
-
Python中正则表达式的巧妙使用一文包
2019-05-27
-
如何使用正则表达式对输入数字进行
2022-10-12
-
最实用的正则表达式的整理
2022-10-12
-
正则表达式去除中括号(符号)及里
2019-06-26

