本篇文章介绍正则表达式后面不要包含指定的字符串内容。 以前只会/abc(?!def).+/.exec(abcdef\nabczzz),匹配到abczzz,这种简单的固定写法,但实际使用次数几乎趋近于0。 很多场景不能写死abc,顺理成章的就写成了/.+(?!def).+/.exec(abcdef\nabczzz),咦?
|
本篇文章介绍正则表达式后面不要包含指定的字符串内容。 以前只会/<abc(?!def).+>/.exec("<abcdef>\n<abczzz>"),匹配到<abczzz>,这种简单的固定写法,但实际使用次数几乎趋近于0。 很多场景不能写死abc,顺理成章的就写成了/<.+(?!def).+>/.exec("<abcdef>\n<abczzz>"),咦?咋把前面的匹配到了!从入门到放弃。 昨天(2019-04-07)随手写了一下/<(?:.(?!def))+>/.exec("<abcdef>\n<abczzz>"),原来是对.+(?!排除的字符串)这个结构能起到的作用理解错了,怪不得达不到预期,(.(?!排除的字符串))+才是正解。 留下一个未解的问题,每个字符后面排除一下的能良好工作,一堆未定长度字符后排除一下怎么就不能工作,前瞻不会和前面的+、*、{}起作用吗?解释看结尾。 附:/<(?!.+def).+>/.exec("<abcdefzzz>\n<abczzz>")写法也可以。可能是结尾的.+导致的不能匹配,但这样写还是不行:/<.+(?!def)zzz>/.exec("<abcdefzzz>\n<abczzz>")。 正则表达式匹配指定内容后面要或不要包含指定的字符串内容:
•要:比较简单,写上这个要的即可
1.表达式内固定内容的字符串能不写尽量不写,能简写的尽量简化来写(如前面写的abc部分不能写死)
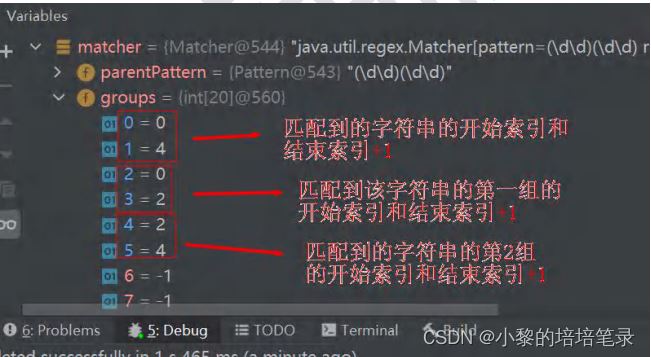
不要单个字符的匹配 匹配出div.matchX标签:<div ***="*** ***" class="*** matchX ***" ***="***"> 可以直接使用 [^>]把matchX限定在<> HTML标记内,意思就是<>中的文本不要出现结尾的>字符。 单个字符还算简单:
如果不限定在<>标记内,可能会匹配出界;并且这种不限定,迟早会出乱子:
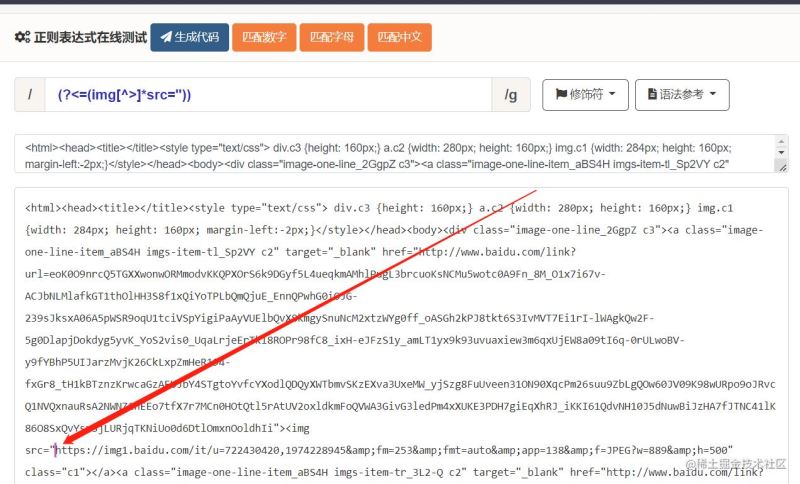
其他单个字符场景另行灵活运用。 不要一个字符串的匹配 匹配出第一层不带excludeX文本内容的第一块div,就是返回包含matchX 4的那块div [^]语法只能排除掉单个字符,不要一个字符串咋办?硬是要写成[^abc],会把a、b、c字符全部排除掉;除了使用前瞻,好像还没有别的简单办法。 使用本文开头的(.(?!排除的字符串))+结构就能达到目的,核心就在(?:[^>](?!excludeX))*:
要包含一个字符串的匹配,直接写需要的字符串即可,相对简单太多,就不写这种例子了。 未研究(.(?!排除的字符串))+结构的性能。 对于.+(?!排除)不能工作的释疑 由于(?!排除)并不会作用于贪婪匹配到的每一个字符串,只会作用于.+贪婪匹配到的最后一个字符;意思就是前瞻不能阻止+对最后一个字符之前的所有字符进行贪婪匹配。
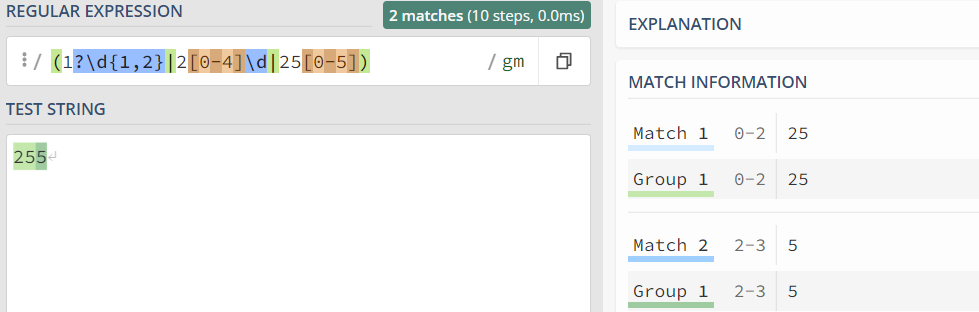
第一个 .+ 匹配到了 abcde,之后是 f,不是 def,第二个 .+ 匹配 f,符合正则 额外记录
如果要对每个字符进行前瞻检查,唯有最后一种写法比较好理解。 |




2021-06-04
2019-05-27
2022-10-12
2022-10-12
2019-06-26