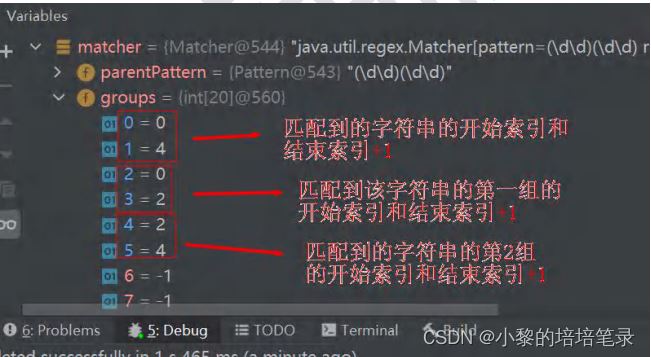
捕获组(capturing group)是正则表达式里比较常用,也是比较重要的概念,我个人觉得掌握这部分的知识是非常重要的。 这篇文章内容不会很深入,但是尽量做到简单易懂又全面。接下来的内容主要是围绕以下7个点: 1: () 捕获组 2: (?:) non capturing group 3:
|
捕获组(capturing group)是正则表达式里比较常用,也是比较重要的概念,我个人觉得掌握这部分的知识是非常重要的。
在上面的例子里面(go)就形成了一个捕获组(capturing group)。接下来看一个使用捕获组的例子来加深对它的理解:
在上面这个例子里,我们有三组括号,形成了三个捕获组,正则表达式(在javaScript里就是我们的RegExp)会缓存捕获组所匹配的串,以$n表示,n就代表这第几个捕获组。 假如现在我们有一个需求:把显示格式为 10.25.2017 的时间改为 2017-10-25 格式。 我们知道String的replace()方法经常和正则表达式一起使用。在replace()方法里,我们可以直接使用捕获组的结果:
2: (?:) non capturing group 非捕获型分组 有的时候我们可能只想匹配分组,但是并不想缓存(不想捕获)匹配到的结果,就可以在我们的分组模式前面加上?:。例如上面的时间的例子,我们不想捕获第一个分组的结果,就可以这么做:
从上面的例子可以看出,我们的正则表达式依然是匹配的(test()的结果依然为true),但是RegExp.$1不是数字10,而是25,因为我们在第一个括号里加了?:,10就不会被捕获。match()的执行结果也会受?:的影响:match()的结果里不再有‘10'。 3: (?=) positive lookahead 正向前瞻型捕获 有一个句子:1 apple costs 10€. 我们想要匹配€前面的价格(这里是一个数字),但是注意不能匹配到句子开头的数字1。这种情况,就可以用到正向前瞻型捕获:
上面的例子里面reg1就只需要匹配数字,对于数字后面跟什么并没有要求,所以它能匹配到1,10。但是reg使用了前瞻型匹配,就只能匹配到10。 或许你已经能从上面的对比里了解到什么是正向前瞻型捕获了,意思是: /x(?=y)/ 匹配x, 但是必须在x的【后面】【是】y的情况下 4: (?!) negative lookahead 负向前瞻型捕获 上面我们了解了什么是正向前瞻型匹配,从字面意思也能猜出来负向前瞻型捕获就是: /x(?!y)/ 匹配x, 但是必须在x的【后面】【不是】y的情况下 例如下面的例子,我们要匹配数字1,而不要€前面的2,就可以用到?!:
5: (?<=) positive lookbehind 正向后顾型捕获 后顾型和前瞻型正好相反,意思就是: /(?<=y)x/ 匹配x, 但是只在【前面】【有】y的情况下 来看一个例子:
这里的要求是前面有$的数字,所以这里匹配到了数字2,而没有1. 6: (?<!) negative lookbehind 负向后顾型捕获 负向就是与正向相反,那么负向后顾型捕获就是: /(?<=y)x/ 匹配x, 但是只在【前面】【没有】y的情况下 来看一个例子:
7: (?=), (?!), (?<=), (?<!)的捕获 默认情况下上面的前瞻后顾4种都是默认不匹配捕获组里面的内容的,也就是不匹配括号里的条件的。例如我们的正向前瞻/d+(?=€)/g,只会匹配到数字,并不会匹配到€。如果我们想要也匹配到€怎么办呢?答案就是给€也包上一个括号:
这样就匹配到了数字2和它后面的€。 下面再来看看后顾型:
需要特别注意到的一点是,对于后顾型,虽然条件在匹配项的前面,但是匹配出来的结果顺序依然是条件在匹配项的后面。所以这里match()出来的结果是2在$的前面。 |




2021-06-04
2019-05-27
2022-10-12
2022-10-12
2019-06-26