这个正则出自这个网站 http://www.regexlab.com/zh/regref.htm 正向预搜索:(?=xxxxx),(?!xxxxx) 格式:(?=xxxxx),在被匹配的字符串中,它对所处的 缝隙 或者 两头 附加的条件是:所在缝隙的右侧,必须能够匹配上 xxxxx 这部分的表达式。因为它只是在此作
|
正向预搜索:"(?=xxxxx)","(?!xxxxx)" 格式:"(?=xxxxx)",在被匹配的字符串中,它对所处的 "缝隙" 或者 "两头" 附加的条件是:所在缝隙的右侧,必须能够匹配上 xxxxx 这部分的表达式。因为它只是在此作为这个缝隙上附加的条件,所以它并不影响后边的表达式去真正匹配这个缝隙之后的字符。这就类似 "\b",本身不匹配任何字符。"\b" 只是将所在缝隙之前、之后的字符取来进行了一下判断,不会影响后边的表达式来真正的匹配。 点击测试 举例1:表达式 "Windows (?=NT|XP)" 在匹配 "Windows 98, Windows NT, Windows 2000" 时,将只匹配 "Windows NT" 中的 "Windows ",其他的 "Windows " 字样则不被匹配。 点击测试 举例2:表达式 "(\w)((?=\1\1\1)(\1))+" 在匹配字符串 "aaa ffffff 999999999" 时,将可以匹配6个"f"的前4个,可以匹配9个"9"的前7个。这个表达式可以读解成:重复4次以上的字母数字,则匹配其剩下最后2位之前的部分。当然,这个表达式可以不这样写,在此的目的是作为演示之用。
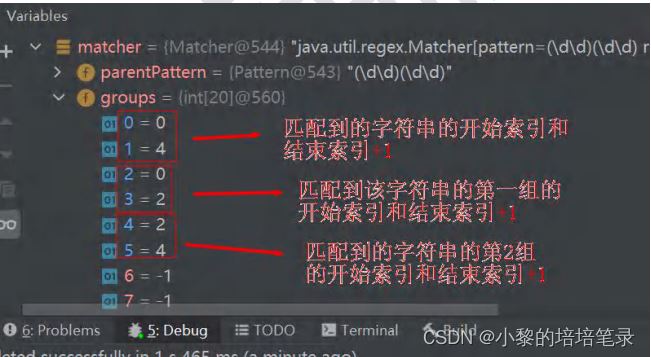
1、(\w)((?=\1\1\1)(\1))+
最后的+号意思是一个或多个 意思就是 666666之匹配前四个6,而999999999只匹配前面7个,后面反正要留两个
(\w)((?=\1\1\1)(\1))+在999999999 中实际上是被匹配了6次。 2、(\w)((\1)(?=\1\1))+
第一次 \w取出第一个9,\1再取1个9就是 99 后面紧跟两个9才符合条件 所有第一次就是99 3、 (?<=<(\w+)>).*(?=<\/\1>)
详细解释下:?<=和?=都表示零宽断言,一个匹配后面一个匹配前面, 总结下:匹配类似<tag>content</tag>格式中的content部分 不过经过测试网页版的js匹配不到,还是中比较好用,推荐大家下载学习
网页版看不到效果 所有大家在使用的时候,要测试你的语言是否支持。 正则表达式看懂的最好方法就是一步步分开解析:
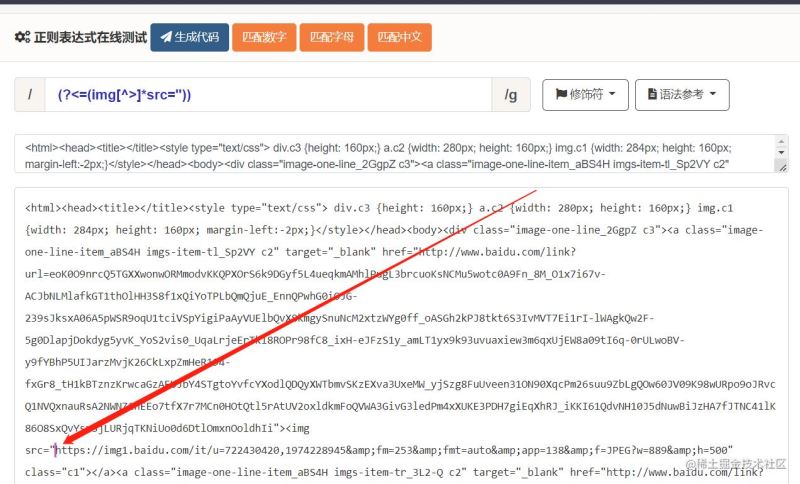
1)以 '.*' 为分界,前面括号中的内容可以划分为 ‘?<=' 和 ‘<(\w+)>',其中‘<(\w+)>'表示匹配尖括号里面是字母、数字或下划线的内容,类似<span>,外面还要加个括号是要实现分组;而‘?<='用到的是零宽断言语法,表示的是断定‘<(\w+)>'后面有或没有内容,而且与内容的间隔宽度为零。
下面是脚本之家小编写的打算将不带style的span替换为空的正则。
不可能用的,要不所有的内容都乱了。 文中相关测试工具 下面接这个为大家分享这几个高级规则
预搜索,不匹配;反向预搜索,不匹配 正向预搜索:"(?=xxxxx)","(?!xxxxx)" 格式:"(?=xxxxx)",在被匹配的字符串中,它对所处的 "缝隙" 或者 "两头" 附加的条件是:所在缝隙的右侧,必须能够匹配上 xxxxx 这部分的表达式。因为它只是在此作为这个缝隙上附加的条件,所以它并不影响后边的表达式去真正匹配这个缝隙之后的字符。这就类似 "\b",本身不匹配任何字符。"\b" 只是将所在缝隙之前、之后的字符取来进行了一下判断,不会影响后边的表达式来真正的匹配。 点击测试 举例1:表达式 "Windows (?=NT|XP)" 在匹配 "Windows 98, Windows NT, Windows 2000" 时,将只匹配 "Windows NT" 中的 "Windows ",其他的 "Windows " 字样则不被匹配。 点击测试 举例2:表达式 "(\w)((?=\1\1\1)(\1))+" 在匹配字符串 "aaa ffffff 999999999" 时,将可以匹配6个"f"的前4个,可以匹配9个"9"的前7个。这个表达式可以读解成:重复4次以上的字母数字,则匹配其剩下最后2位之前的部分。当然,这个表达式可以不这样写,在此的目的是作为演示之用。
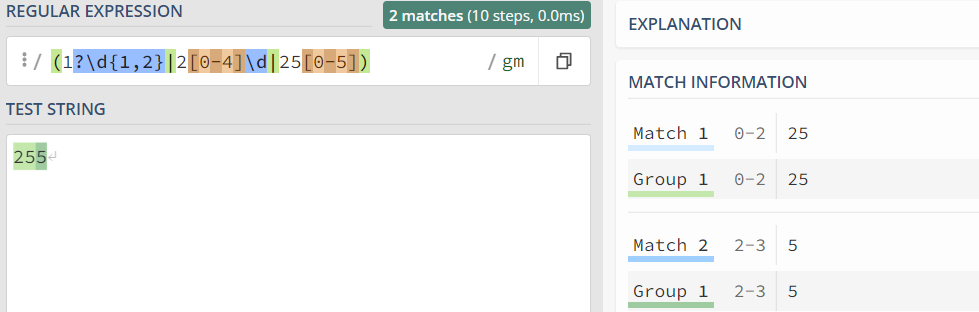
点击测试 举例3:表达式 "((?!\bstop\b).)+" 在匹配 "fdjka ljfdl stop fjdsla fdj" 时,将从头一直匹配到 "stop" 之前的位置,如果字符串中没有 "stop",则匹配整个字符串。 点击测试 举例4:表达式 "do(?!\w)" 在匹配字符串 "done, do, dog" 时,只能匹配 "do"。在本条举例中,"do" 后边使用 "(?!\w)" 和使用 "\b" 效果是一样的。 反向预搜索:"(?<=xxxxx)","(?<!xxxxx)" 这两种格式的概念和正向预搜索是类似的,反向预搜索要求的条件是:所在缝隙的 "左侧",两种格式分别要求必须能够匹配和必须不能够匹配指定表达式,而不是去判断右侧。与 "正向预搜索" 一样的是:它们都是对所在缝隙的一种附加条件,本身都不匹配任何字符。 举例5:表达式 "(?<=\d{4})\d+(?=\d{4})" 在匹配 "1234567890123456" 时,将匹配除了前4个数字和后4个数字之外的中间8个数字。由于 JScript.RegExp 不支持反向预搜索,因此,本条举例不能够进行演示。很多其他的引擎可以支持反向预搜索,比如:Java 1.4 以上的 java.util.regex 包,.NET 中System.Text.RegularExpressions 命名空间,以及本站推荐的最简单易用的 DEELX 正则引擎。 |




2021-06-04
2019-05-27
2022-10-12
2022-10-12
2019-06-26