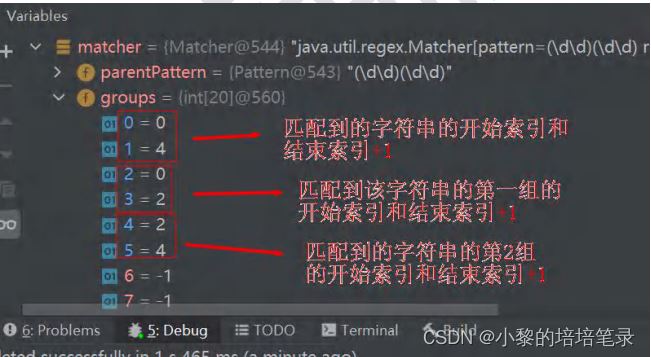
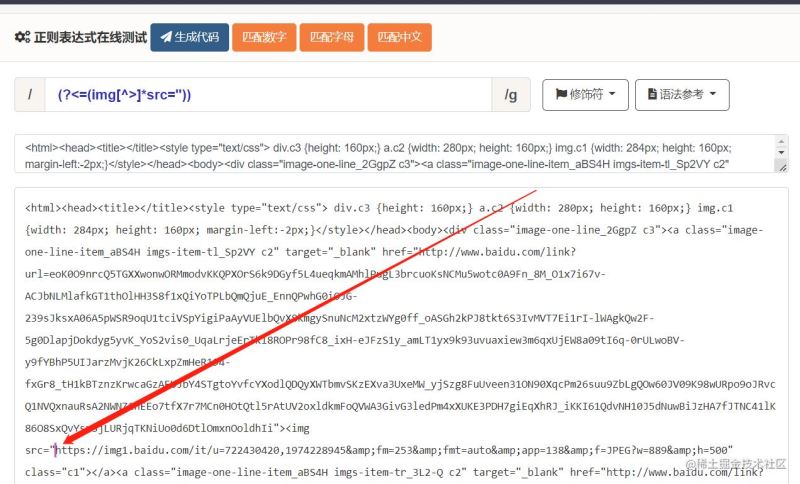
任何复杂的正则表达式都是由简单的子表达式组成的,要想写出复杂的正则来,一方面需要有化繁为简的功底,另外一方面,我们需要从正则引擎的角度去思考问题。关于正则引擎的原理,推荐《Mastering Regular Expression》中文名叫《精通正则表达式》。挺不错的
|
任何复杂的正则表达式都是由简单的子表达式组成的,要想写出复杂的正则来,一方面需要有化繁为简的功底,另外一方面,我们需要从正则引擎的角度去思考问题。关于正则引擎的原理,推荐《Mastering Regular Expression》中文名叫《精通正则表达式》。挺不错的一本书。 OK,先确定我们要解决的问题——从一段Html文本中找出特定id的标签的innerHTML。 这里面最大的难点就是,Html标签是支持嵌套的,怎么能够找到指定标签相对应的闭合标签呢? 我们可以这样想,先匹配最前面的起始标签,假设是div吧(<div),接着一旦遇到嵌套div,就“压入堆栈”,后面如果遇到div闭合标签了,就“弹出堆栈”。如果遇到闭合标签的时候,堆栈里面已经没有东西了,那么匹配结束,此结束标签为正确的闭合标签。 我之所以能够这样去思考,是因为我了解过正则的特性,我知道正则中的平衡组能够实现我刚才说的“堆栈”操作。所以,如果我们要编写复杂正则表达式,需要对正则的一些高级特性至少有所了解,这样我们思考问题才有个方向。 匹配任意闭合HTML标签的正则表达式:
如果只想匹配div标签,可以使用下面的正则表达式:
是的,你可以把div修改成任意你想要匹配的HTML标签 如果想同时匹配多个HTML标签,可以使用下面的正则表达式:
你还可以继续添加更多要匹配的标签 如果想匹配包含ID的标签,可以使用下面的正则表达式:
这个正则匹配任意id为footer的HTML标签 脚本之家小编补充: 正则 \k 你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+)(或者把尖括号换成'也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b。
有,但是是跟<>配合用的,详见下面: |

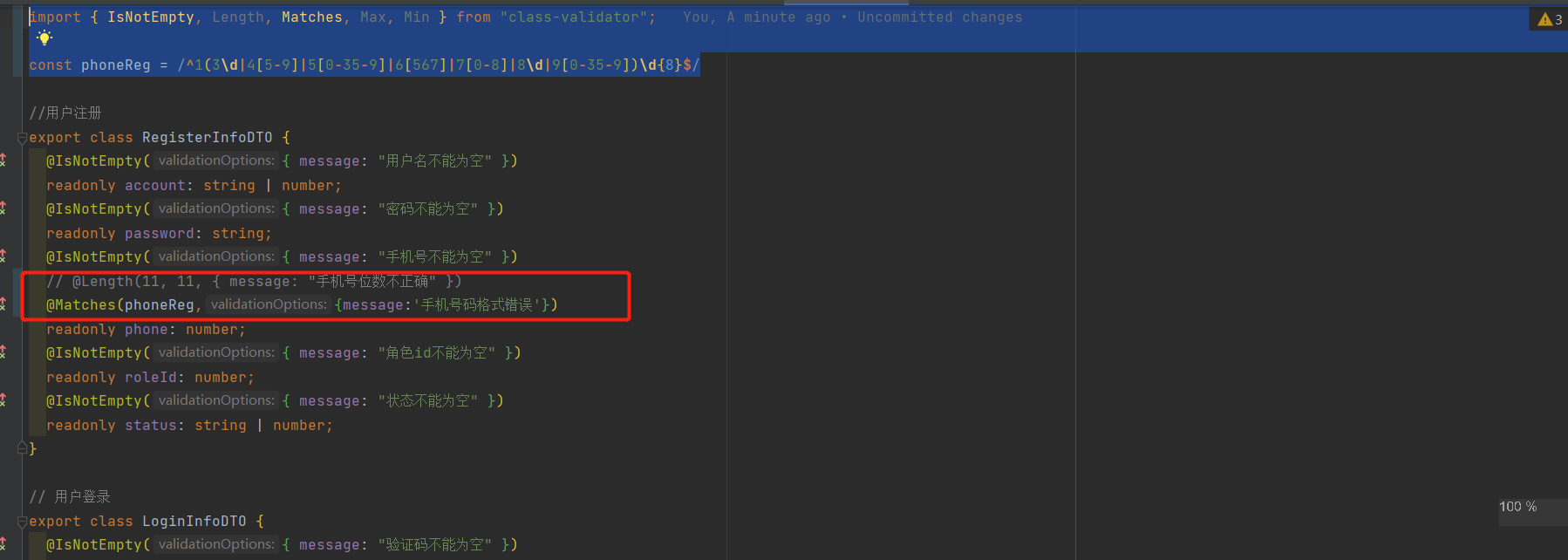



2021-06-04
2019-05-27
2022-10-12
2022-10-12
2019-06-26