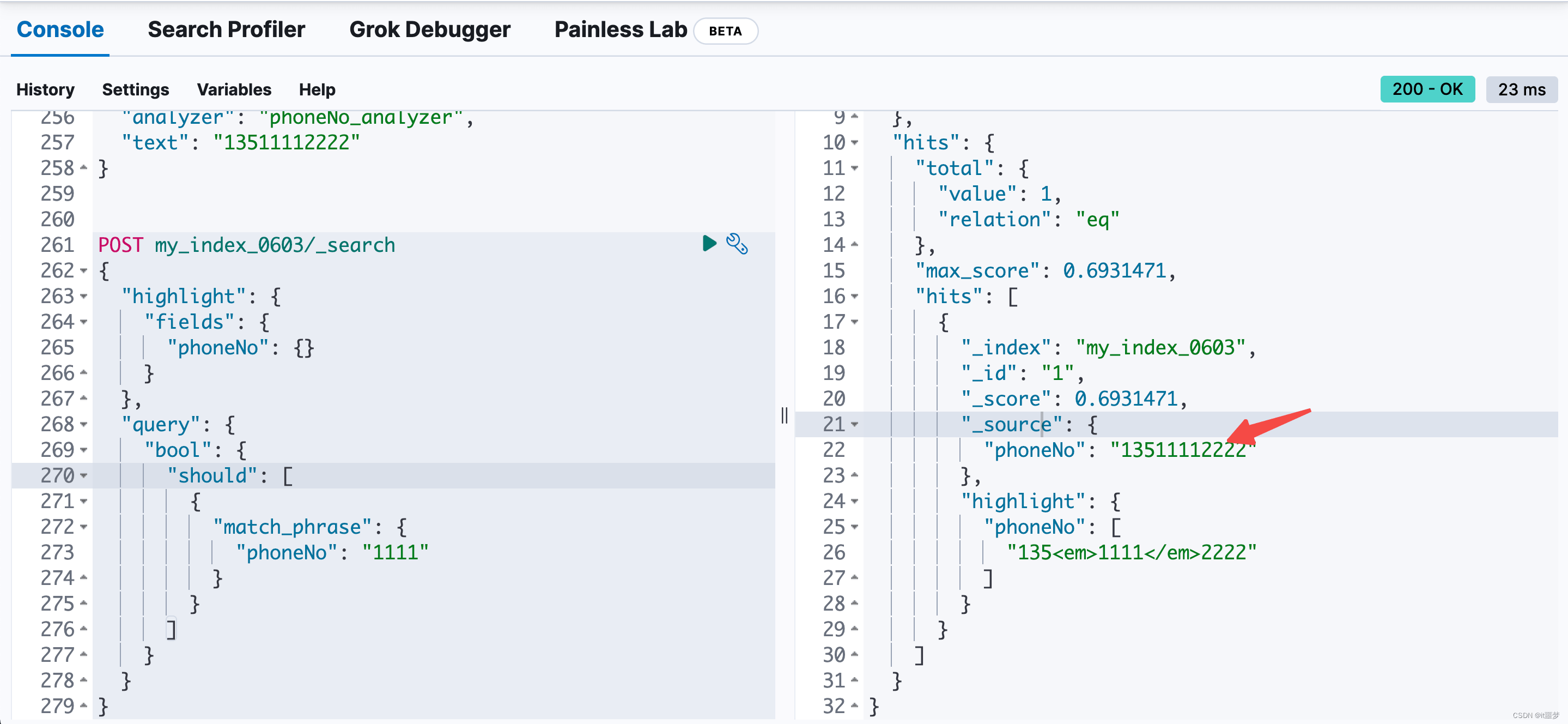
Ngram自定义分词案例 当对keyword类型的字段进行高亮查询时,若值为123asd456,查询sd4,则高亮结果是<em>123asd456<em>。那么,有没有办法只对sd4高亮呢?用一句话来概括问题:明明只想查询
Ngram自定义分词案例当对keyword类型的字段进行高亮查询时,若值为123asd456,查询sd4,则高亮结果是<em>123asd456<em>。那么,有没有办法只对sd4高亮呢?用一句话来概括问题:明明只想查询ID的一部分,但高亮结果是整个ID串,此时应该怎么办? 实战问题拆解
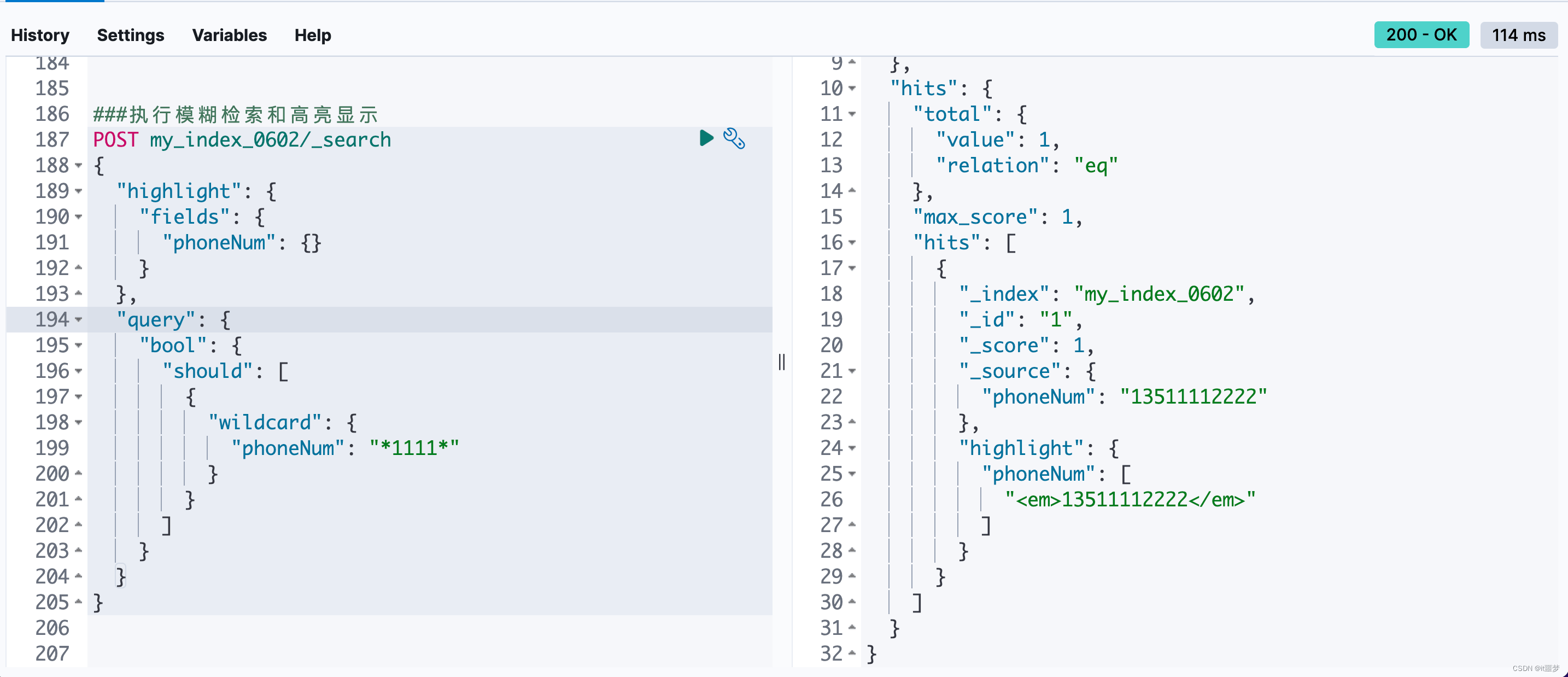
高亮检索结果如下。
也就是说,整个字符串都呈现为高亮状态了,没有达到预期。 检索过程中选择使用wildcard是为了解决子串匹配的问题,wildcard的实现逻辑类似于MySQL的like模糊匹配。传统的text标准分词器,包括中文分词器ik、英文分词器english、standard等都不能解决上述子串匹配问题。 而实际业务需求是这样的:一方面要求输入子串能召回全串;另一方面要求检索的子串实现高亮。对此,只能更换一种分词来实现,即Ngram。 Ngram分词器定义Ngram分词定义Ngram是一种基于统计语言模型的算法。Ngram基本思想是将文本里面的内容按照字节大小进行滑动窗口操作,形成长度是N的字节片段序列。此时每一个字节片段称为gram。对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间。列表中的每一种gram就是一个特征向量维度。 该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其他任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram(二元语法)和三元的Tri-Gram(三元语法)。 Ngram分词示例以“你今天吃饭了吗“这一中文句子为例,它的Bi-Gram分词结果如下。
Ngram分词应用场景场景1:文本压缩、检查拼写错误、加速字符串查找、文献语种识别。 场景2:自然语言处理自动化领域得到新的应用。如自动分类、自动索引、超链的自动生成、文献检索、无分隔符语言文本的切分等。 场景3:自然语言的自动分类功能。针对Elasticsearch检索,Ngram针对无分隔符语言文本的分词(比如手机号检索),可提高检索效率(相较于wildcard检索和正则匹配检索来说) Ngram分词实战
|






2022-04-23
2023-04-23
2024-04-08
2022-10-16
2024-03-08