
ElasticSearch使用Composite Aggregation实现桶的分页查询功能

官方文档 https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-composite-aggregation.html#_pagination 概述 当需要分页查询大量的桶时composite 聚合可以通过分页的方式逐步获取桶结果,
|
官方文档https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-composite-aggregation.html#_pagination
概述当需要分页查询大量的桶时composite 聚合可以通过分页的方式逐步获取桶结果,避免一次性返回大量的桶 。 与传统分页方法不同,composite aggregation 并不基于结果的偏移量(offset),而是基于聚合桶的游标机制来实现分页,从而避免了性能瓶颈。 Composite Aggregation 概述composite aggregation 是 Elasticsearch 中的一种特殊聚合方式,适用于需要分页展示的聚合结果。它与传统的聚合方式不同,采用了基于游标的分页模型。composite aggregation 不依赖 from 和 size 来进行分页,而是通过 after 参数来指定从某个特定桶之后开始返回数据,从而实现分页。 示例:基本分页查询假设我们有一个索引,名称为 your_index_name,其中包含多个文档,每个文档都有一个字段 your_field_name。我们希望根据这个字段进行分页查询,并且每次返回 10 个聚合结果。 以下是一个基础的分页查询示例:
分页:获取下一页结果要实现分页,我们需要使用 after 参数来指示从哪个位置开始返回数据。这个参数的值是上一个查询返回的最后一个桶的 key 值。 下面是如何获取第二页结果的示例:
例如,假设第一次查询的返回结果包含以下聚合信息:
在第二次分页查询时,我们需要使用 after_key 中的 your_field_name: "value2" 作为 after 参数的值,以此来获取下一页的结果。
返回
下次查询
使用场景composite aggregation 非常适用于以下场景:
注意事项
|

您可能感兴趣的文章 :

-

解决 “Error: listen EACCES: permission denied 0.0.0.0:80“
在开发过程中,我们经常会遇到各种各样的错误。其中一个常见的错误是Error: listen EACCES: permission denied 0.0.0.0:80。这个错误通常发生在尝试启 -
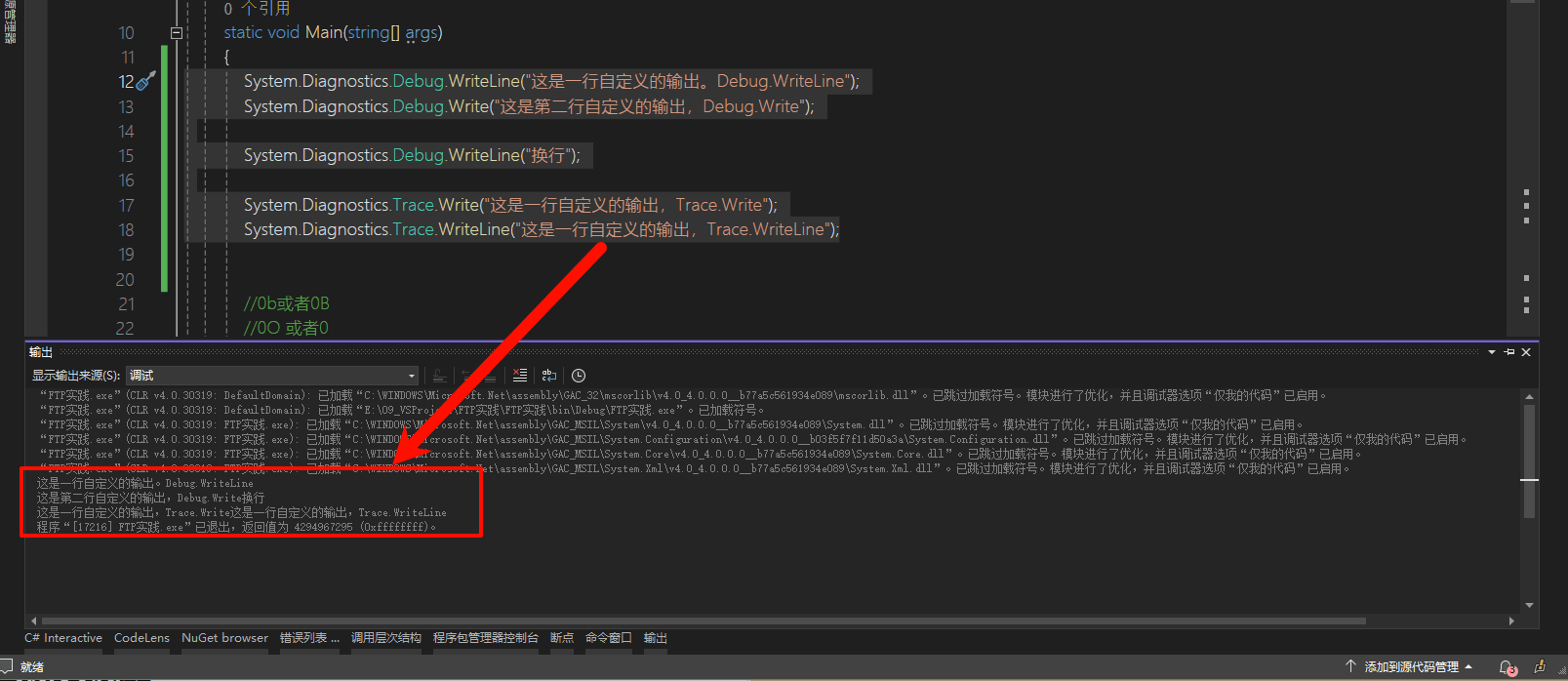
VS2022如何调出输出窗口并在输出窗口打印日志
在输出窗口打印 1 2 3 4 5 6 7 System.Diagnostics.Debug.WriteLine(这是一行自定义的输出。Debug.WriteLine); System.Diagnostics.Debug.Write(这是第二行自定义的输 -

ElasticSearch使用Composite Aggregation实现桶的分页查询
官方文档 https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-composite-aggregation.html#_pagination 概述 当需要分页查询大量的桶 -
Solidity变量介绍之类型、作用域与最佳实践记录
Solidity变量详解:类型、作用域与最佳实践 引言 在Solidity智能合约开发中,变量是最基础也是最重要的概念之一。本文将深入探讨Solidity中的 -
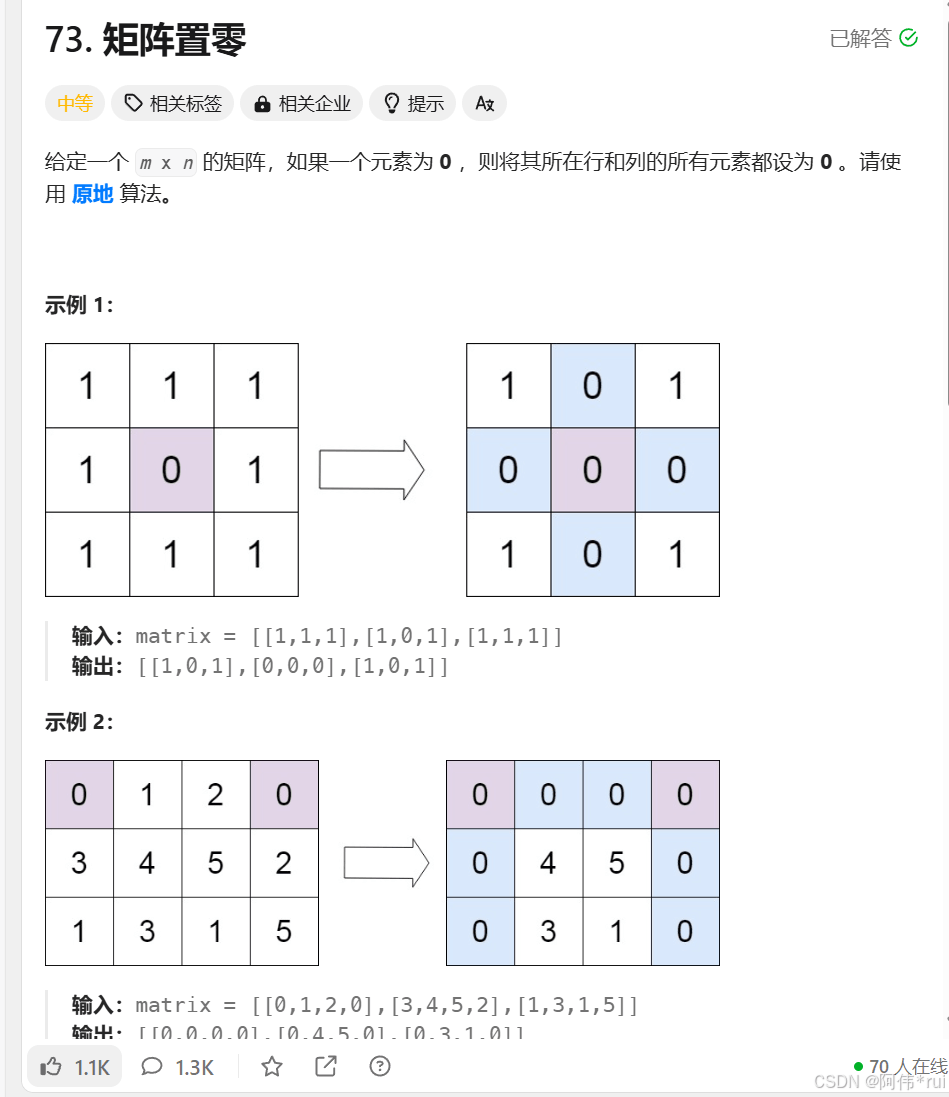
(最新推荐)leetcode刷题记录
day4 73:矩阵置0 题目: 我的答案: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ArrayListInteger x = new ArrayList(); ArrayListInteger y = new ArrayList(); for (int i = 0; -
在Git中撤消更改的六种方法总结
当使用 Git 进行项目代码管理时,难免会出现一些错误操作或需求变更,需要对代码进行撤销或修改。Git 提供了多种方式来撤消已有的更改 -
鸿蒙开发Hvigor插件动态生成代码的操作方法
Hvigor允许开发者实现自己的插件,开发者可以定义自己的构建逻辑,并与他人共享。Hvigor主要提供了两种方式来实现插件:基于hvigorfile脚本 -
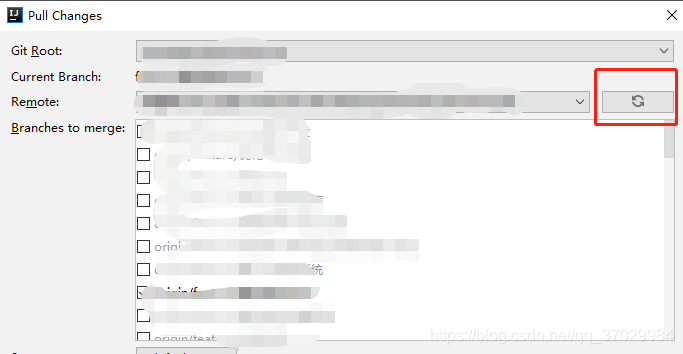
Git上新建的分支IDEA找不到问题及解决方法
一、vcs-git-pull 点击刷新按钮,然后再查看即可。 二、如果还没有 切换到idea自带的cmd面板,执行git pull 然后file --Close Project 关闭项目,然后 -
鸿蒙Navigation拦截器实现页面跳转登录鉴权方案详
我们在进行页面跳转时,很多情况下都得考虑登录状态问题,比如进入个人信息页面,下单交易页面等等。在这些场景下,通常在页面跳转




-
解决Git Bash中文乱码的问题
2022-04-23
-
webp格式图片显示异常分析及解决方案
2023-04-23
-
typescript 实现RabbitMQ死信队列和延迟队
2024-04-08
-
git clone如何解决Permission Denied(publick
2024-11-15
-
Win10环境下编译和运行 x264的详细过程
2022-10-16

