
DeepSeek部署之GPU监控指标接入Prometheus的过程

一、背景 上一篇文章介绍了在GPU主机部署DeepSeek大模型。并且DeepSeek使用到了GPU资源来进行推理和计算的过程,加速我们模型的回答速度。 由此,我们必须要关注主机GPU的监控指标情况,例如
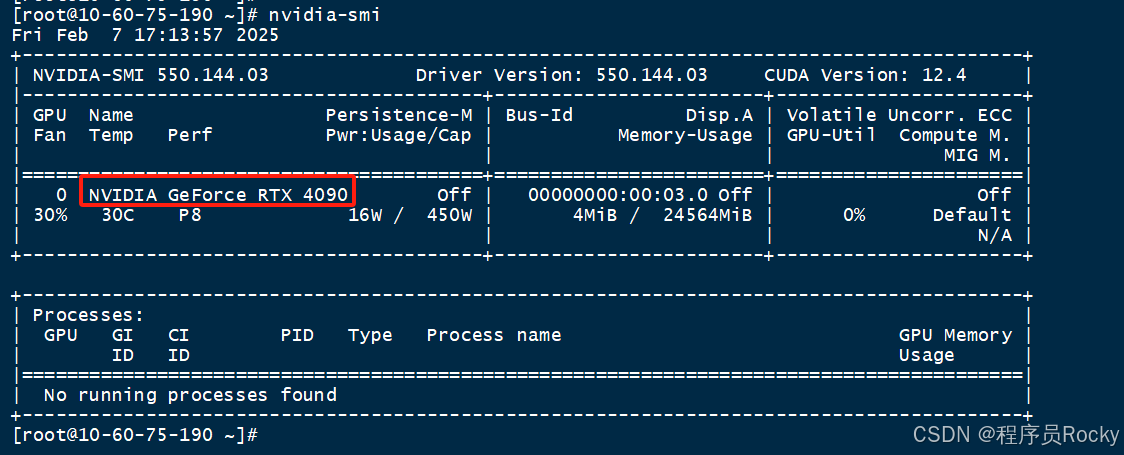
一、背景上一篇文章介绍了在GPU主机部署DeepSeek大模型。并且DeepSeek使用到了GPU资源来进行推理和计算的过程,加速我们模型的回答速度。 由此,我们必须要关注主机GPU的监控指标情况,例如总的显卡显存大小、占用的显存大小、显卡的版本信息、驱动信息等等,才能对CPU运行情况、利用率等做到心中有数,便于后期的运维、高可用性等。 二、部署nvidia_gpu_exporter1、nvidia_gpu_exporter介绍地址: GitHub - utkuozdemir/nvidia_gpu_exporter: Nvidia GPU exporter for prometheus using nvidia-smi binary 我们可以使用nvidia_gpu_exporter本质原理是用过nvidia-smi指令采集GPU的信息,然后转换为prometheus metric。 所以部署nvidia_gpu_exporter之前,需要正常安装号nvidia-smi,并且安装好了nvidia驱动、CUDA驱动等。 正常执行nvidia-smi如下: ?
2、docker部署,测试/metrics是否正常执行docker命令: ?
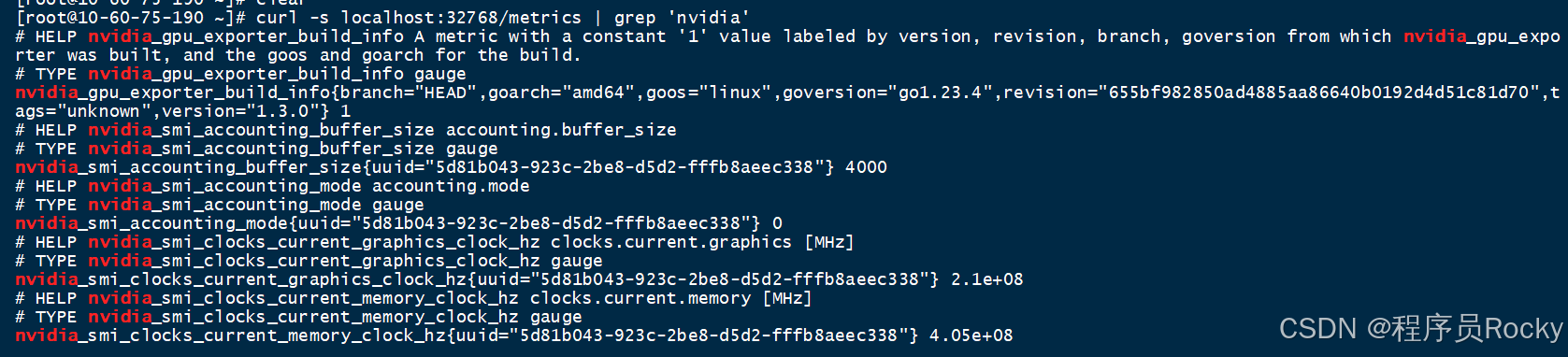
通过curl访问主机的32768(端口可以自己做映射), 访问/metrics接口看是否可以正常拿到指标数据: ?
三、配置prometheus+Grafana1、配置prometheus进行采集配置promethues.yml文件:
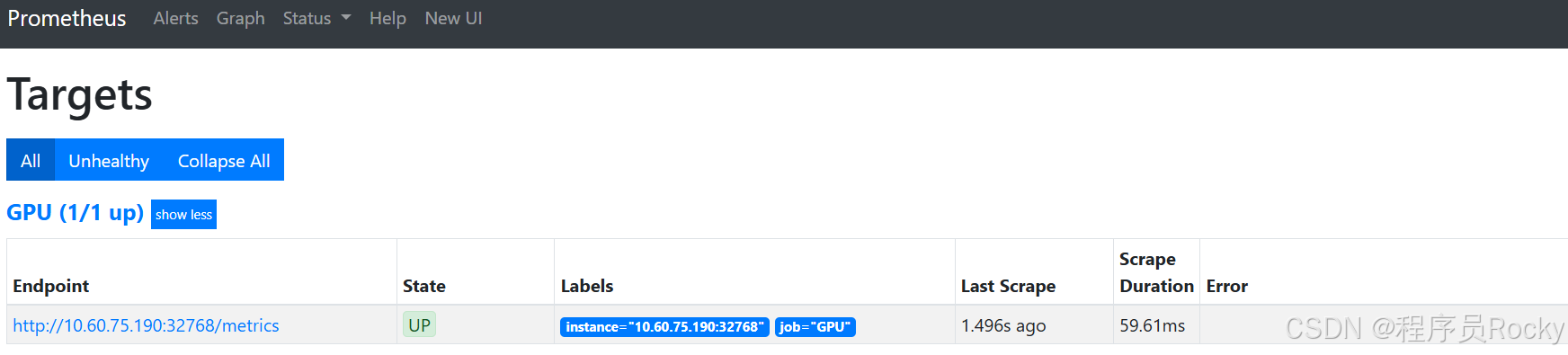
查看promethues的target是否正常能采集到数据:
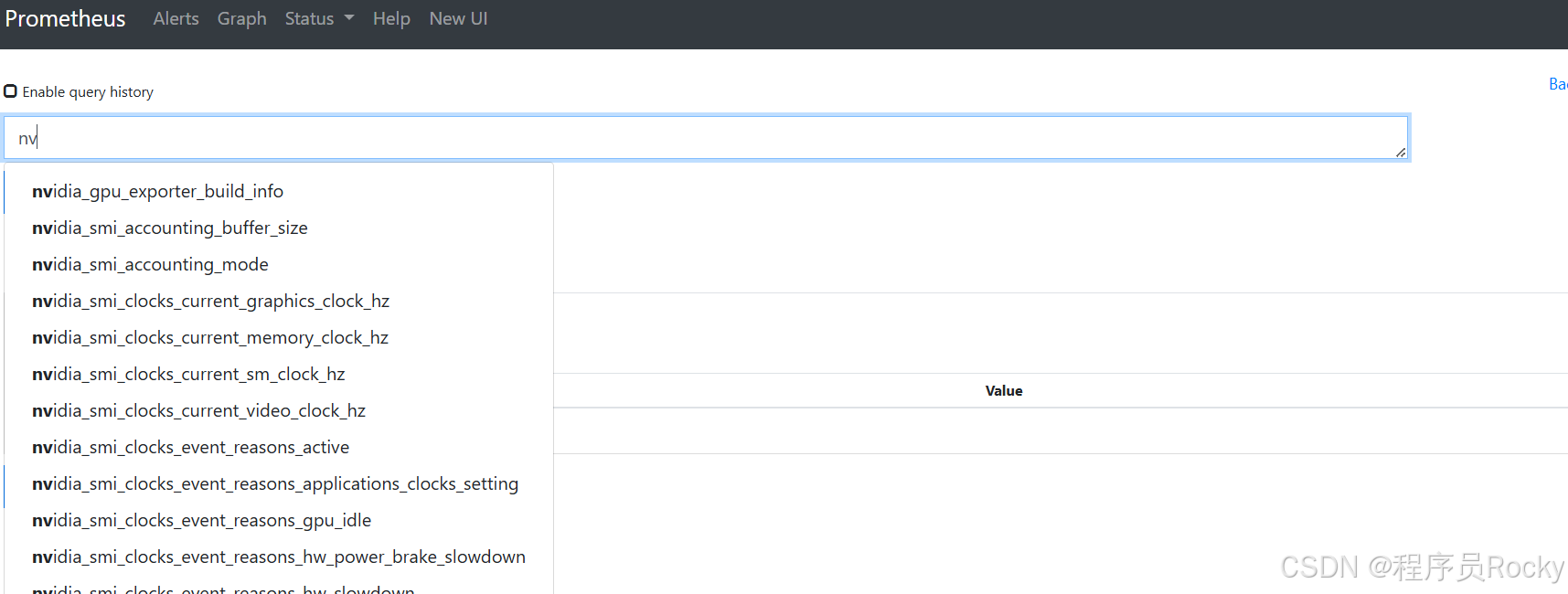
搜索指标是否已经入库:
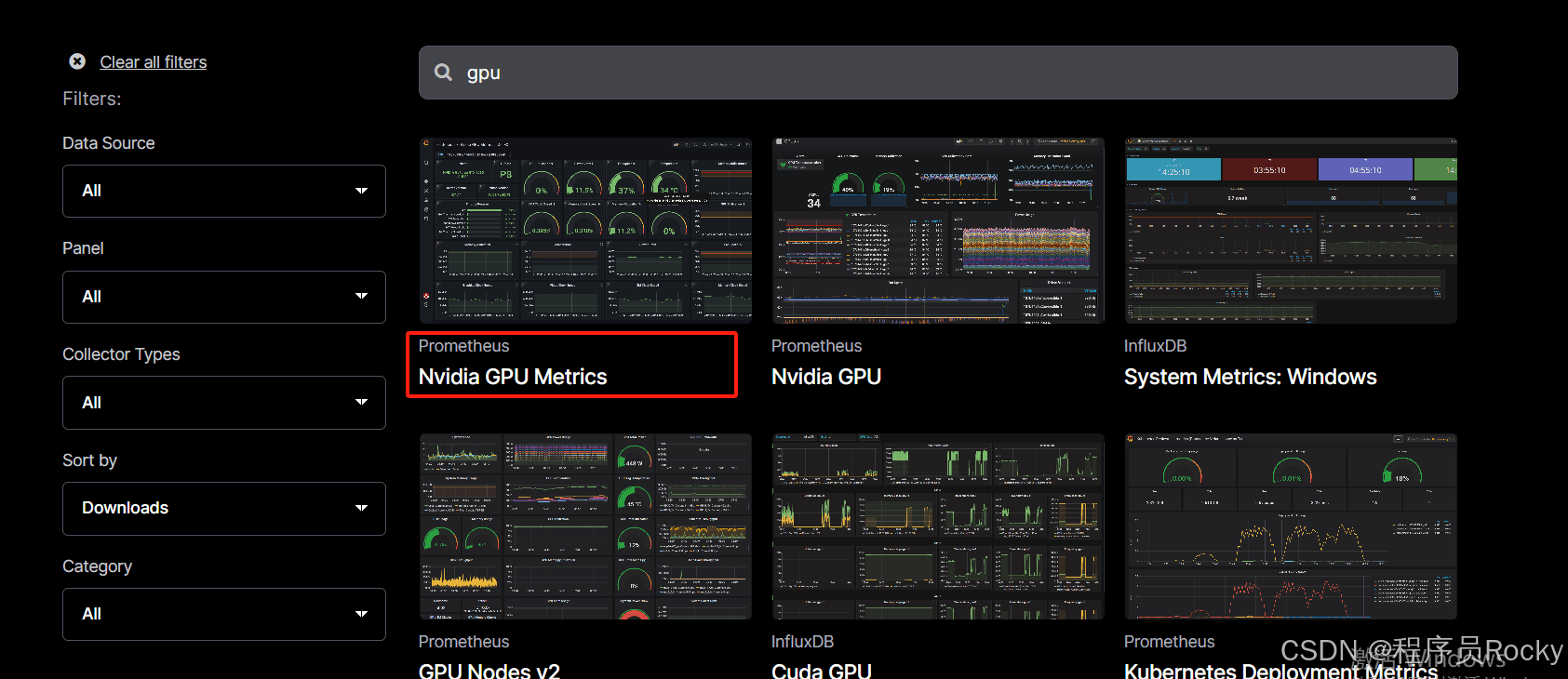
2、Grafana面板搜索并且导入面板搜索gpu关键词,查询到面板ID:
3、导入Grafana面板ID,查看效果面板可以看到GPU的型号是RTX 4090、显存的使用情况等指标, 此时我正在服务器运行deepseek-r1:1.5b的模型,所以看到GPU的相关使用。如果将模型停止运行,则GPU基本上无占用
四、总结AI人工智能、大模型等理论知识我们都能多少了解点,但是今天看了一些大佬的教程,稍微深入了一下使用PyTorch进行了一些基础、简单模型的训练以及部署运行, 发现从零开始去尝试做机器学习的相关开发工作简直是天方夜谈,涉及到的就是各种概率学、统计学、线性代数、算法等等,门槛是相当高。 既然无法做开发,那么从运维工程师的角度出发,了解PyTorch、tensorflow等深度学习框架的部署、模型的运行等等,继续在运维路上前进,扬长避短,才能发挥自我优势! |



您可能感兴趣的文章 :

-
VSCODE内使用Jupyter模式运行backtrader不展示图片、图
一、VSCODE无法展示图片 在Vscode里用jupyter,运行backtrader,使用plot后,图片不展示。 运行代码 # 可视化cerebro.plot() 结果并没有弹出图片,而是 -
完美解决DeepSeek服务器繁忙问题
解决DeepSeek服务器繁忙问题 三:最为推荐 一、用户端即时优化方案 网络加速工具 推荐使用迅游加速器或海豚加速器优化网络路径,缓解因 -
Deepseek R1模型本地化部署+API接口调用详细教程(释
随着最近人工智能 DeepSeek 的爆火,越来越多的技术大佬们开始关注如何在本地部署 DeepSeek,利用其强大的功能,甚至在没有互联网连接的情 -
DeepSeek部署之GPU监控指标接入Prometheus的过程
一、背景 上一篇文章介绍了在GPU主机部署DeepSeek大模型。并且DeepSeek使用到了GPU资源来进行推理和计算的过程,加速我们模型的回答速度。 -
Deepseek使用指南与提问优化策略方式
随着人工智能技术的迅猛发展,语义搜索已成为提升信息检索效率和用户体验的核心工具。DeepSeek 作为一款先进的语义搜索引擎,通过自然 -
DeepSeek Window本地私有化部署教程介绍
最近大火的国产AI大模型Deepseek大家应该都不陌生。除了在手机上安装APP或通过官网在线体验,其实我们完全可以在Windows电脑上进行本地部署 -
DeepSeek本地部署流程介绍
随着人工智能技术的飞速发展,本地部署大模型的需求也日益增加。DeepSeek作为一款开源且性能强大的大语言模型,提供了灵活的本地部署方 -
DeepSeek服务器繁忙问题的原因分析与解决方案(最
随着人工智能技术的飞速发展,DeepSeek 等语言模型在众多领域得到了广泛应用。然而,在春节这段时间的使用过程中,用户常常遭遇服务器 -
DeepSeek本地部署+可视化WebUI的实现(图文教程)
随着deepseek的大火,也萌生了想在本地搞一个AI帮助解决日常遇到的问题! 一.下载并安装Ollama 直接到官网点击下载即可ollam 下载好安装与其 -
DeepSeek本机部署详细步骤(基于Ollama和Docker管理)
在人工智能技术日新月异的时代,大语言模型的应用越来越广泛,DeepSeek 作为其中的佼佼者,备受开发者和技术爱好者的关注。通过在本机



-
解决Git Bash中文乱码的问题
2022-04-23
-
webp格式图片显示异常分析及解决方案
2023-04-23
-
typescript 实现RabbitMQ死信队列和延迟队
2024-04-08
-
git clone如何解决Permission Denied(publick
2024-11-15
-
Win10环境下编译和运行 x264的详细过程
2022-10-16

