
完美解决DeepSeek服务器繁忙问题

解决DeepSeek服务器繁忙问题 三:最为推荐 一、用户端即时优化方案 网络加速工具 推荐使用迅游加速器或海豚加速器优化网络路径,缓解因网络拥堵导致的连接问题。以迅游为例: 启动加速器
解决DeepSeek服务器繁忙问题三:最为推荐 一、用户端即时优化方案网络加速工具 启动加速器后搜索"DeepSeek"专项加速输入口令DS111可领取免费加速时长(海豚加速器适用) 清理浏览器缓存与切换设备 在Chrome/Firefox中清理缓存(设置→隐私和安全→删除浏览数据)尝试手机APP访问或使用无痕模式(Chrome按Ctrl+Shift+N) 错峰使用策略 二、高级技术方案本地化部署
API调用与第三方平台
三、替代方案与平替工具(最推荐简单好用)若问题持续存在,可考虑以下替代服务:
四、系统层建议与官方动态服务器负载现状 官方应对措施
建议优先尝试本地部署+加速器组合方案,若需持续稳定使用可考虑订阅企业版($20/月享专属服务器通道)。当前问题预计在2025年3月算力扩容完成后显著缓解。
用加速器本地部署DeepSeek使用加速器本地部署DeepSeek的完整指南一、核心原理与工具选择通过加速器实现本地部署的本质是:利用网络优化工具解决模型下载/API通信问题,配合部署框架实现离线运行。当前主流方案分为两类: 全托管式部署(推荐新手) 使用迅游/海豚等集成工具包,实现"加速+部署"一体化操作
半自动部署(适合开发者)
二、迅游加速器全托管方案步骤说明(Windows/Mac通用): 安装与加速
一键部署操作
部署验证
注意项:
三、海豚加速器+Ollama手动部署高阶操作流程: 网络加速配置
Ollama环境部署 # Windows PowerShell(管理员) winget install ollama ollama --version # 验证安装(需返回v0.5.2+) ?
启动本地服务 ollama serve # 默认端口11434 ?
AMD显卡使用ROCm: sudo fallocate -l 16G /swapfile sudo chmod 600 /swapfile sudo mkswap /swapfile sudo swapon /swapfile ?
|
您可能感兴趣的文章 :

-
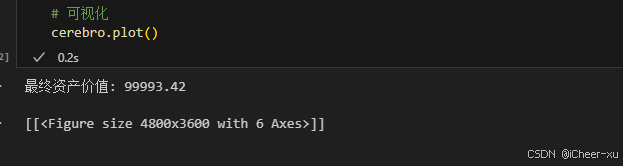
VSCODE内使用Jupyter模式运行backtrader不展示图片、图
一、VSCODE无法展示图片 在Vscode里用jupyter,运行backtrader,使用plot后,图片不展示。 运行代码 # 可视化cerebro.plot() 结果并没有弹出图片,而是 -
完美解决DeepSeek服务器繁忙问题
解决DeepSeek服务器繁忙问题 三:最为推荐 一、用户端即时优化方案 网络加速工具 推荐使用迅游加速器或海豚加速器优化网络路径,缓解因 -
Deepseek R1模型本地化部署+API接口调用详细教程(释
随着最近人工智能 DeepSeek 的爆火,越来越多的技术大佬们开始关注如何在本地部署 DeepSeek,利用其强大的功能,甚至在没有互联网连接的情 -
DeepSeek部署之GPU监控指标接入Prometheus的过程
一、背景 上一篇文章介绍了在GPU主机部署DeepSeek大模型。并且DeepSeek使用到了GPU资源来进行推理和计算的过程,加速我们模型的回答速度。 -
Deepseek使用指南与提问优化策略方式
随着人工智能技术的迅猛发展,语义搜索已成为提升信息检索效率和用户体验的核心工具。DeepSeek 作为一款先进的语义搜索引擎,通过自然 -
DeepSeek Window本地私有化部署教程介绍
最近大火的国产AI大模型Deepseek大家应该都不陌生。除了在手机上安装APP或通过官网在线体验,其实我们完全可以在Windows电脑上进行本地部署 -
DeepSeek本地部署流程介绍
随着人工智能技术的飞速发展,本地部署大模型的需求也日益增加。DeepSeek作为一款开源且性能强大的大语言模型,提供了灵活的本地部署方 -
DeepSeek服务器繁忙问题的原因分析与解决方案(最
随着人工智能技术的飞速发展,DeepSeek 等语言模型在众多领域得到了广泛应用。然而,在春节这段时间的使用过程中,用户常常遭遇服务器 -
DeepSeek本地部署+可视化WebUI的实现(图文教程)
随着deepseek的大火,也萌生了想在本地搞一个AI帮助解决日常遇到的问题! 一.下载并安装Ollama 直接到官网点击下载即可ollam 下载好安装与其 -
DeepSeek本机部署详细步骤(基于Ollama和Docker管理)
在人工智能技术日新月异的时代,大语言模型的应用越来越广泛,DeepSeek 作为其中的佼佼者,备受开发者和技术爱好者的关注。通过在本机



-
解决Git Bash中文乱码的问题
2022-04-23
-
webp格式图片显示异常分析及解决方案
2023-04-23
-
typescript 实现RabbitMQ死信队列和延迟队
2024-04-08
-
git clone如何解决Permission Denied(publick
2024-11-15
-
Win10环境下编译和运行 x264的详细过程
2022-10-16

