
Win10环境借助DockerDesktop部署大数据时序数据库Apache Druid的操作方法

Win10环境借助DockerDesktop部署最新版大数据时序数据库Apache Druid32.0.0 前言 大数据分析中,有一种常见的场景,那就是时序数据,简言之,数据一旦产生绝对不会修改,随着时间流逝,每个时间点
Win10环境借助DockerDesktop部署最新版大数据时序数据库Apache Druid32.0.0前言大数据分析中,有一种常见的场景,那就是时序数据,简言之,数据一旦产生绝对不会修改,随着时间流逝,每个时间点都会有个新的状态值。这种时序数据的量级往往异常夸张,例如传感器的原始监控数据: https://lizhiyong.blog.csdn.net/article/details/114898620 一个简单的加速度传感器一年的数据量就是31e!!!制造业传感器数据如果不经底层PLC等下位机预处理,直接打到边缘计算网关,即使mqtt也会有巨大的负载!!! 类似的,还有服务器的原始监控数据,例如常见的Prometheus和Zabbix,当集群很多时,监控项同样很多,再算上虚拟化后的容器和虚拟机内都可能部署了监控,此时的数据量级就灰常可观!!!一小时几百亿条数据都是常见的事情!!! 但是很多原始的监控数据如果全部存下来,存储成本高的可怕,同时信息密度极低,更多时候我们可能只关注近期的全部热数据来做在线的模型训练,人工查看每秒钟几千条数据也是不切合实际的,事实上,做一个简单的秒级/分钟级统计就能满足大多数的分析场景,超过1天的冷数据其实已经没什么时效性。 对于此类场景,可以高吞吐、预聚合的数据库,在压测后,从Apache Druid、Clickhouse、Kylin中,选择了前者。。。专业的事情要交给专业的组件去做!!! 对于非内核和二开的业务开发人员,更多场景应该关注的是API、特性及用法,不应该在部署这种事情上花费太多精力!!!笔者之前已部署了Docker Desktop: https://lizhiyong.blog.csdn.net/article/details/145580868 今天在Win10环境再搭建个Apache Druid最新版玩玩。 版本选择官网: https://druid.apache.org/ 注意不是阿里数据库连接池的那个Druid!!!
截至2025-02-13,Apache Druid最新版本是32.0.0。 资源准备参考官网: https://druid.apache.org/docs/latest/tutorials/docker 官方给出了使用docker-compose.yml编排容器的教程,作为一个实时组件,大内存是必须的!!!但是启动8个容器【Zookeeper+PostgreSQL+6个Druid】每个最多7GB内存也不是什么大事!!! https://raw.githubusercontent.com/apache/druid/32.0.0/distribution/docker/docker-compose.yml 获取到这个资源文件:
参照官网另一篇: https://druid.apache.org/docs/latest/configuration/ 自己玩玩可以先不改这些运行时配置,容器启动的,后续要重新部署也非常容易!!! 还需要: https://raw.githubusercontent.com/apache/druid/32.0.0/distribution/docker/environment 做另一个配置文件:
部署文件看起来麻雀虽小五脏俱全!!! 部署
拉取镜像成功后很快就能拉起容器:
好家伙。。。还顺便把其它组件的端口也给暴露出来了。。。
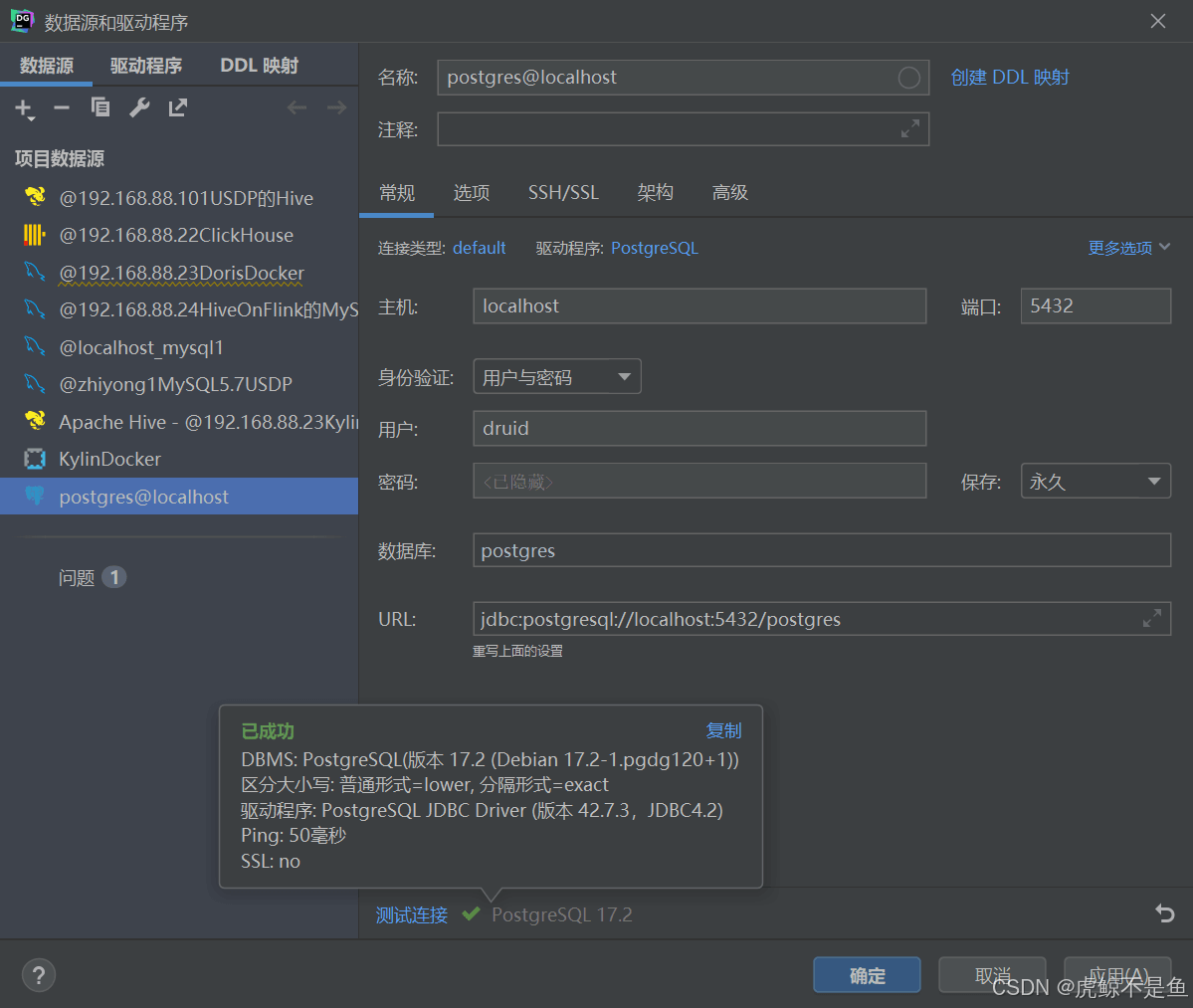
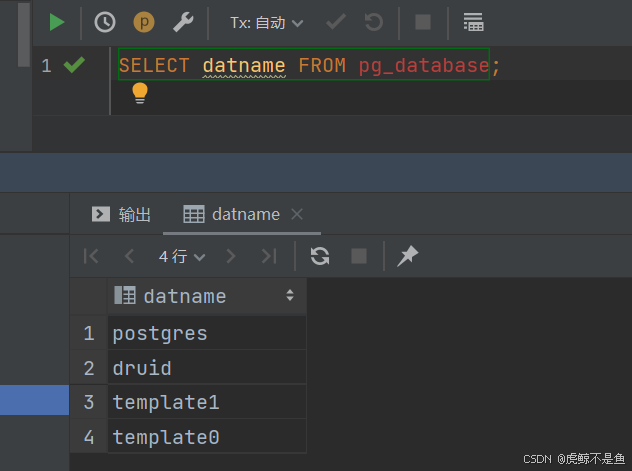
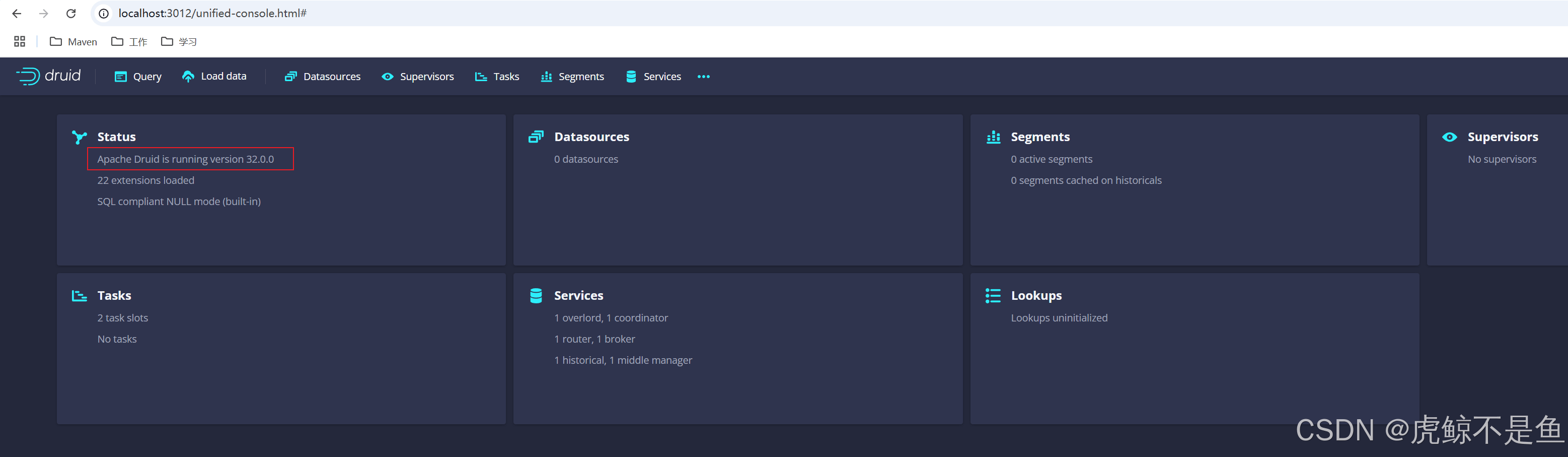
于是还**白piao**到一个PG和Zookeeper!!! 验证 http://localhost:3012/unified-console.html#
灰常好,现在已经拥有了一个最新Apache Druid32.0.0!!! 转载请注明出处:https://lizhiyong.blog.csdn.net/article/details/145622903 |

您可能感兴趣的文章 :

-
Win10环境借助DockerDesktop部署大数据时序数据库A
Win10环境借助DockerDesktop部署最新版大数据时序数据库Apache Druid32.0.0 前言 大数据分析中,有一种常见的场景,那就是时序数据,简言之,数据 -
VScode内接入deepseek包过程记录
VScode内接入deepseek包过程 在 VSCode 中集成本地部署的 DeepSeek-R1 模型可以显著提升开发效率,尤其是在需要实时访问 AI 模型进行推理任务时 -
deepseek本地部署流程(解决服务器繁忙以及隐私等
由于官网deepseek老是出问题 所以我决定本地部署deepseek 很简单,不需要有什么特殊技能 正文开始 Ollama 首先到这个ollama的官网 goto-Ollama 然后 -
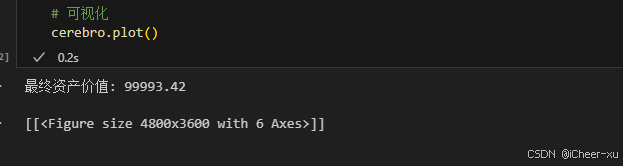
VSCODE内使用Jupyter模式运行backtrader不展示图片、图
一、VSCODE无法展示图片 在Vscode里用jupyter,运行backtrader,使用plot后,图片不展示。 运行代码 # 可视化cerebro.plot() 结果并没有弹出图片,而是 -
完美解决DeepSeek服务器繁忙问题
解决DeepSeek服务器繁忙问题 三:最为推荐 一、用户端即时优化方案 网络加速工具 推荐使用迅游加速器或海豚加速器优化网络路径,缓解因 -
Deepseek R1模型本地化部署+API接口调用详细教程(释
随着最近人工智能 DeepSeek 的爆火,越来越多的技术大佬们开始关注如何在本地部署 DeepSeek,利用其强大的功能,甚至在没有互联网连接的情 -
DeepSeek部署之GPU监控指标接入Prometheus的过程
一、背景 上一篇文章介绍了在GPU主机部署DeepSeek大模型。并且DeepSeek使用到了GPU资源来进行推理和计算的过程,加速我们模型的回答速度。 -
Deepseek使用指南与提问优化策略方式
随着人工智能技术的迅猛发展,语义搜索已成为提升信息检索效率和用户体验的核心工具。DeepSeek 作为一款先进的语义搜索引擎,通过自然 -
DeepSeek Window本地私有化部署教程介绍
最近大火的国产AI大模型Deepseek大家应该都不陌生。除了在手机上安装APP或通过官网在线体验,其实我们完全可以在Windows电脑上进行本地部署



-
解决Git Bash中文乱码的问题
2022-04-23
-
webp格式图片显示异常分析及解决方案
2023-04-23
-
typescript 实现RabbitMQ死信队列和延迟队
2024-04-08
-
git clone如何解决Permission Denied(publick
2024-11-15
-
Win10环境下编译和运行 x264的详细过程
2022-10-16

