
GBK与UTF-8互转乱码问题介绍

GBK与UTF-8互转乱码问题 我们知道在计算机内存中,存储的是二进制数据,在网络传输中,也是二进制数据,但最终呈现给用户的是字符串,二进制与字符串的转化就需要编码、解码的参与,如
GBK与UTF-8互转乱码问题我们知道在计算机内存中,存储的是二进制数据,在网络传输中,也是二进制数据,但最终呈现给用户的是字符串,二进制与字符串的转化就需要编码、解码的参与,如果世界上只有一种字符编码方式,就不会有乱码这一说了,但事实是,编码的方式太多了,utf-8、utf-32、utf-16、gbk、gb2312、iso-8859-1、big5、unicode等等。由于每个编码的规则不一样,一般都不能用一种进行编码,用另一种进行解码。 如utf-8中,一个字母用一个字节表示,一个汉字用三个字节表示,特殊的汉字用四个字节表示,而gbk中,一个字母用一个字节表示,一个汉字用两个字节表示。 有一个说法,内存中存储的二进制是unicode码,如果内存中的数据需要存储或传输时,才会进行一次转化,将unicode码转化成其它的编码二进制(有待考证)。个人觉得这种方式很合理,毕竟unicode码中每个字符都有独一无二的二进制与之对应。 排查乱码问题,难度在于是在哪个环节出了问题,但乱码的本质都是一样的,读取二进制的编码和最初将字符串转化成二进制的编码方式不一致。 此处说明一个概念,编码指将字符串转化成二进制,解码指将二进制转化成字符串。 UTF-8编码,GBK解码在这我们讨论一下,gbk和utf-8互转的乱码问题,直接上代码:
以上代码运行打印出以下内容:
可以看出,utf-8存储一个汉字,需要3个字节,gbk存储一个汉字,需要2个字节。 现用单个字符测试。
运行上面代码,得出的结果:
用两个字符测试,将上述代码String str = “你”改成String str = “你好”。运行代码,得出的结果:
上述实验中,utf-8转化成gbk出现乱码,这个很好理解,但是再还原回去,gbk转化成utf-8,单个中文字符依然是乱码,两个字符却能正常显示,这个到底是怎么回事呢? 经过一番研究,想把这个事说明白,还需要从它们的编码规则着手。 ISO-8859-1 单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。 GBK 采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。双字节其编码范围从8140至FEFE(剔除xx7F)。
单字节、双字节的区分通过高字节高位区分,单字节高位为0,双字节的高字节高位为1。 UTF-8 可变长字符编码,是unicode码的具体实现,UTF-8用1到6个字节编码Unicode字符。 UTF-8编码规则:如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。
明白上述GBK和UTF-8的编码规则,我们再分析一下,单个中文字符是乱码,两个字符却能正常显示的问题。 “你” UTF-8编码对应的二进制:11100100 10111101 10100000 将上述二进制通过GBK进行解码,根据GBK规则,第一个字节高位为1,使用双字节编码, “11100100 10111101”解码成“浣”,“10100000”对于GBK来说是非法的,就解码成了一种特殊字符“?”。 看看能不能将“浣?”还原回“你”呢? GBK编码对应的二进制:11100100 10111101 00111111 看到上述的二进制,根本不符合UTF-8编码规则,故用UTF-8进行解码,是解码成了一些特殊字符“??”。 对于上述情况可以看出,一个二进制,如果不符合当前的编码规则,会被解码成特殊字符,但此特殊字符再进行编码,是回不到最初的二进制的。 用同样的方式,分析“你好”为什么最终可以正常显示。 UTF-8编码对应的二进制:11100100 10111101 10100000 11100101 10100101 10111101 将上述二进制通过GBK进行编码,根据GBK规则,使用双字节编码,“1100100 10111101”解码成“浣”,“10100000 11100101”解码成“犲”,“10100101 10111101”解码成“ソ”。 看看能不能将“浣犲ソ”还原成“你好”呢? GBK 编码对应的二进制:11100100 10111101 10100000 11100101 10100101 10111101 可以看出二进制是可以被还原的,将此二进制通过UTF-8解码,肯定能变成“你好”。 一个字符串,通过UTF-8进行编码,再通过GBK进行解码,再将得到的字符串进行GBK编码,最后将得到的二进制通过UTF-8解码,能否还原到最初的字符串,在于UTF-8编码后得到的二进制,是否符合GBK的编码规则,如果符合,最终就可以还原,如果不符合,就不可还原。 GBK编码,UTF-8解码
运行上述代码,结果为:
上述结果应该都在意料之中,我们通过上述的方法分析一下。 “你好”GBK编码的二进制:11000100 11100011 10111010 11000011 GBK编码的二进制数据,完全匹配不了UTF-8的编码规则,最终UTF-8只能按如下方式匹配,查看第一个字节,开头“110”,理论上匹配两个字节,但看下一个字节,开头却不是“10”,最终“11000100”解码成“?”,看第二个字节开头是“1110”,理论匹配三个字节,看下个字节符合,以“10”开头,但下下个字节开头是“110”,不符合匹配,最终“11100011 10111010”解码成“?”,同理“11000011”也解码成“?”,这个符号都是为找不到对应规则随意匹配的一个特殊字符。 “???”UTF-8编码的二进制为:11101111 10111111 10111101 11101111 10111111 10111101 11101111 10111111 10111101 这个二进制和原先的二进制不相同,根本转化不到最初的字符串,按照GBK的编码规则,“11101111 10111111”编码成“锟”,“10111101 11101111” 编码成“斤”,“10111111 10111101”编码成“拷”,“11101111 10111111”编码成“锟”,“10111101”不符合GBK规则,编码成特殊字符“?”。 理论上说,用GBK编码,UTF-8解码的字符串是不能还原到最初的字符串的,因UTF-8编码规则的特殊性,GBK编出的二进制,是很难匹配上的。 总结理论上说,系统出现乱码,将乱码还原到最初的样子,上述UTF-8编码,GBK解码,这个有时是可以还原的,有时是还原不了的,要看UTF-8编码的二进制是否都能符合GBK的编码规则,但GBK编码,UTF-8解码,这个基本是条不归路。 但实际中,有一种情况,是100%可以将乱码还原成最初的字符串。就是任意编码格式编码,ISO-8859-1解码,这个主要因为ISO-8859-1是单字节编码,而且匹配所有单字节情况,乱码字符串总是可以还原到最初的二进制。 拓展一个小知识点: 关于进制的表示有两种方式,一种是前缀表示法,一种是后缀表示法。 前缀表示法
后缀表示法
对于十进制数通常不加后缀,也即十进制数后的字母 D 可省略。 |
您可能感兴趣的文章 :

-

高阶DeepSeek从入门到精通教程手册
第?章:准备篇(三分钟上手) 1.1 三分钟创建你的 AI 伙伴 1、访问官网:浏览器输?www.deepseek.com; 2、注册账号:点击开始对话,进入新用户 -
后端编程语言多方面对比:JAVA、C、C++、GO、PYT
软件开发领域,语言本身在各自领域都有适用场景,有许多流行的编程语言可供选择,每种语言都有其独特的特点和适用场景。 Java、C、C -
MAC快速本地部署Deepseek的实现介绍
下载安装ollama 地址:https://ollama.com/Ollama 是一个开源的大型语言模型(LLM)本地运行框架,旨在简化大模型的部署和管理流程,使开发者、研 -
GBK与UTF-8互转乱码问题介绍
GBK与UTF-8互转乱码问题 我们知道在计算机内存中,存储的是二进制数据,在网络传输中,也是二进制数据,但最终呈现给用户的是字符串, -
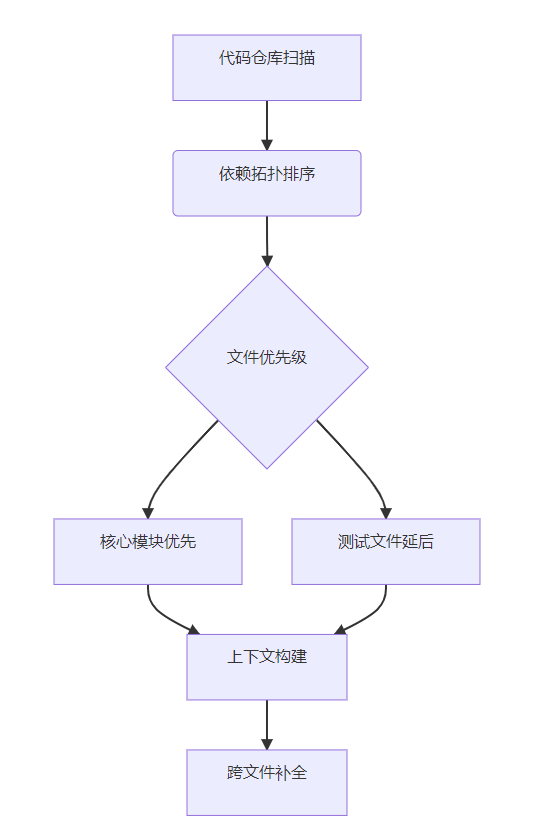
基于DeepSeek-Coder的跨文件的代码
一、环境准备与基础配置 1.1 安装DeepSeek-Coder SDK 1 2 3 4 5 安装最新版SDK(需Python 3.10+) pip install deepseek-coder --upgrade 环境验证(获取API密钥后 -

0基础租个硬件玩deepseek,蓝耘元生代智算云|本地部
0基础租个硬件玩deepseek,蓝耘元生代智算云|本地部署DeepSeek R1模型,3步搞定一个应用 最近DeepSeek-R1 系列推理能力比肩 OpenAI o1;想弄个玩玩。 -
使用Ollama服务监听0.0.0.0地址
一、为什么需要监听0.0.0.0地址? 在计算机网络中,0.0.0.0是一个特殊的IP地址,它表示本机上的所有IPv4地址。 当我们将一个服务配置为监听 -
在linux服务器本地部署Deepseek及在mac远程web-ui访问
1. 在Linux服务器上部署DeepSeek模型 要在 Linux 上通过 Ollama 安装和使用模型,您可以按照以下步骤进行操作: 步骤 1:安装 Ollama 安装 Ollama: -
本地化部署DeepSeek 全攻略(linux、windows、mac系统部
一、Linux 系统部署 准备工作 硬件要求:服务器需具备充足计算资源。推荐使用 NVIDIA GPU,如 A100、V100 等,能加快模型推理速度。内存至少 -
Win10环境借助DockerDesktop部署大数据时序数据库A
Win10环境借助DockerDesktop部署最新版大数据时序数据库Apache Druid32.0.0 前言 大数据分析中,有一种常见的场景,那就是时序数据,简言之,数据



-
解决Git Bash中文乱码的问题
2022-04-23
-
webp格式图片显示异常分析及解决方案
2023-04-23
-
typescript 实现RabbitMQ死信队列和延迟队
2024-04-08
-
git clone如何解决Permission Denied(publick
2024-11-15
-
Win10环境下编译和运行 x264的详细过程
2022-10-16

