
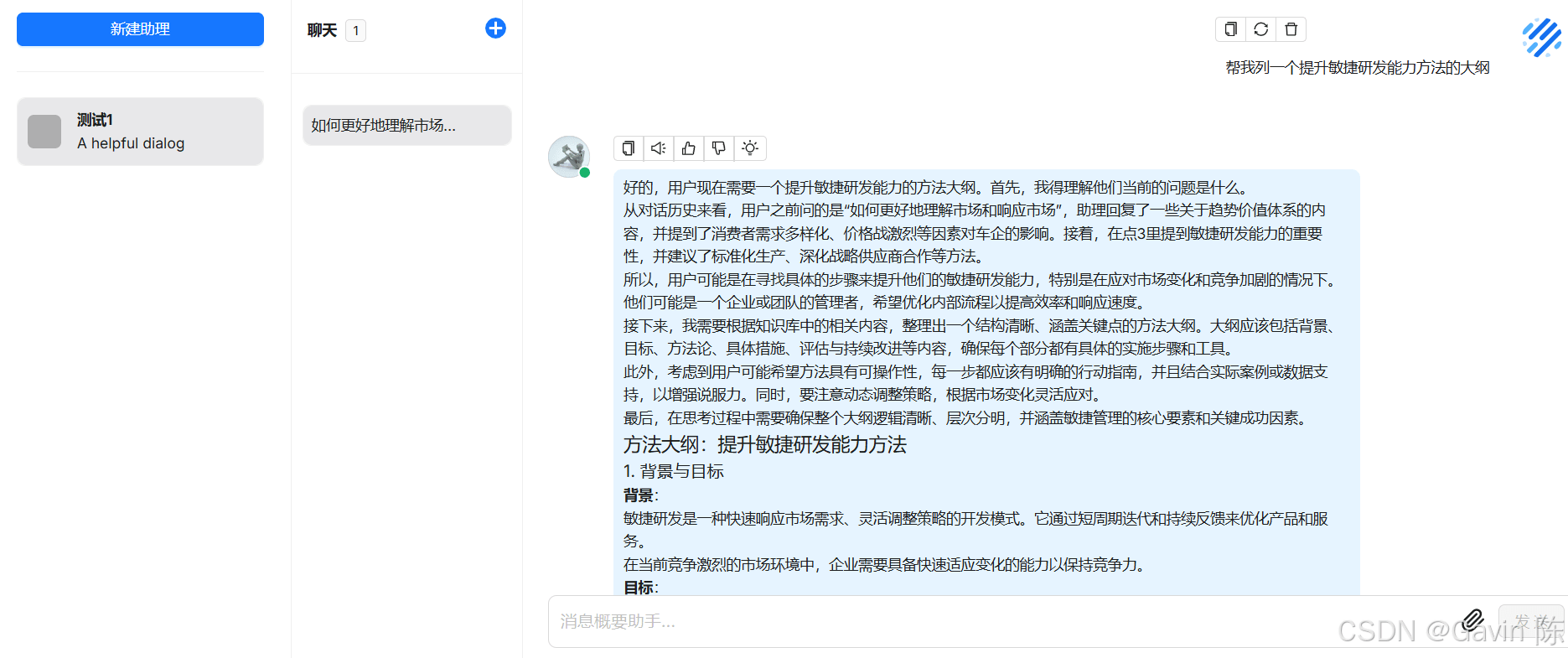
使用DeepSeek搭建个人知识库(在笔记本电脑上)

最近DeepSeek爆火,试用DeepSeek的企业和个人越来越多。最常见的应用场景就是知识库和知识问答。所以本人也试用了一下,在笔记本电脑上部署DeepSeek并使用开源工具搭建一套知识库,实现完全
|
最近DeepSeek爆火,试用DeepSeek的企业和个人越来越多。最常见的应用场景就是知识库和知识问答。所以本人也试用了一下,在笔记本电脑上部署DeepSeek并使用开源工具搭建一套知识库,实现完全在本地环境下使用本地文档搭建个人知识库。操作过程共享出来,供大家参考。 部署环境笔记本电脑,具体配置如下:
软件清单构建本地知识库,除了DeepSeek还需要安装知识库软件。网上推荐比较多的是RagFlow,软件开源,功能也很强大,可以使用本地文档构建外挂知识库。另外,同时也安装了Cherry Studio,可以作为操作DeepSeek的交互工具。
安装DeepSeek从官网下载并安装Ollama,过程略。可参考 https://ollama.com/
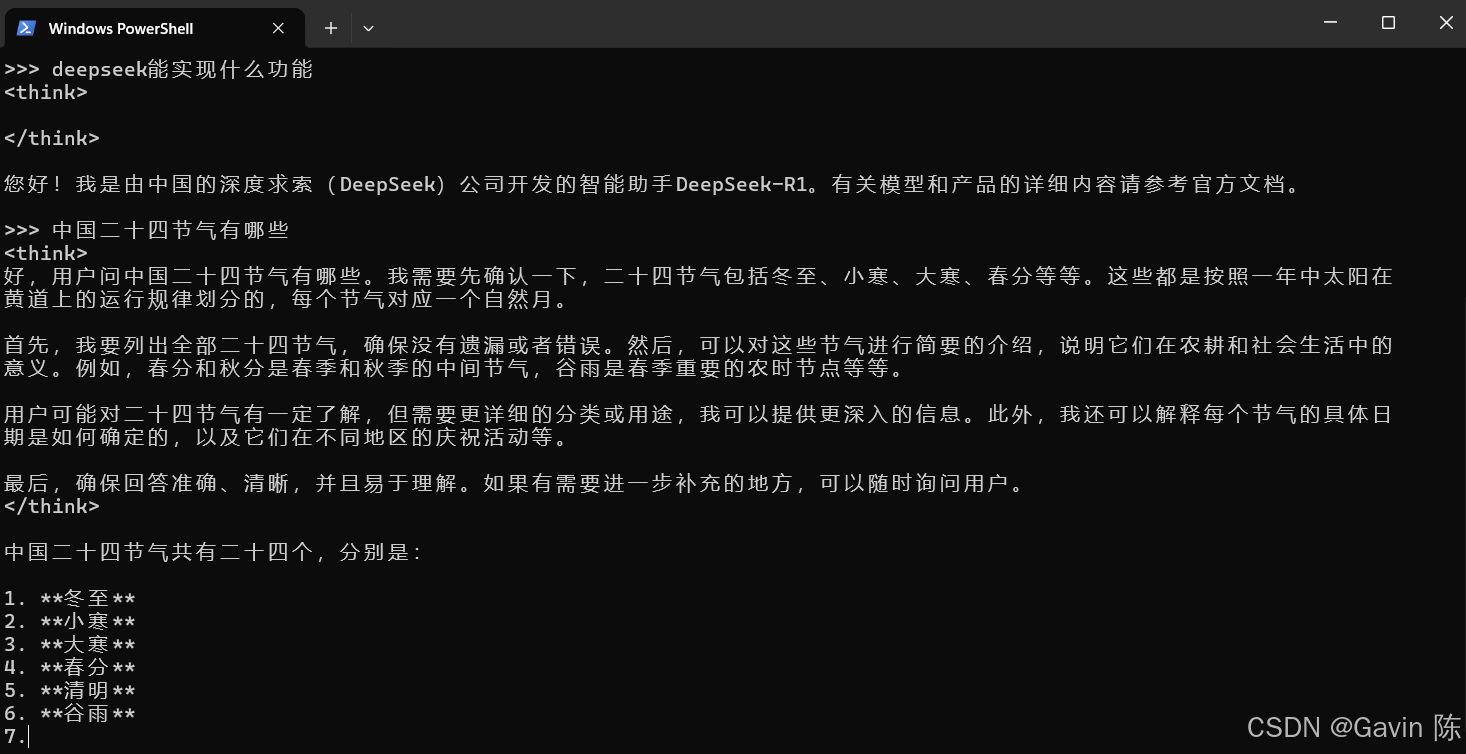
安装完毕后,执行命令:
安装成功后,就可以在命令行里操作deepseek了。
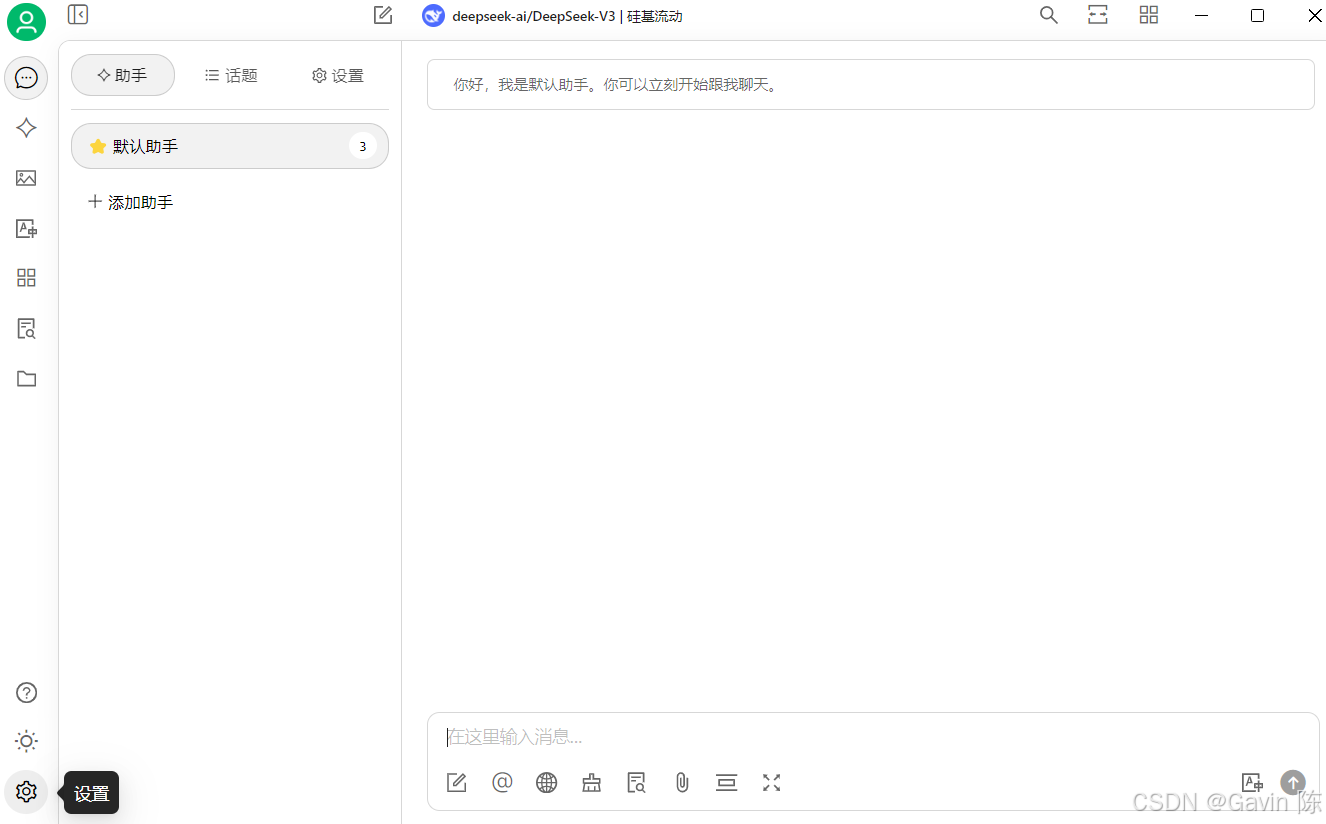
操作很简单。至此,deepseek就安装完毕。 安装Cherry Studio如果不习惯使用命令行,希望使用客户端与本地安装的deepseek交互,可以安装一个对话界面软件,我试用了Chatbox和Cherry Studio都不错,可以更直观地调整模型的参数和提示词,同时也支持将对话内容完全存档在本地,本文以Cherry Studio为例。 前往https://cherry-ai.com/,根据你的操作系统(支持 Windows、Mac 和 Linux)下载对应的安装包。默认下一步安装完毕就好。 启动Cherry Studio,添加嵌入模型。
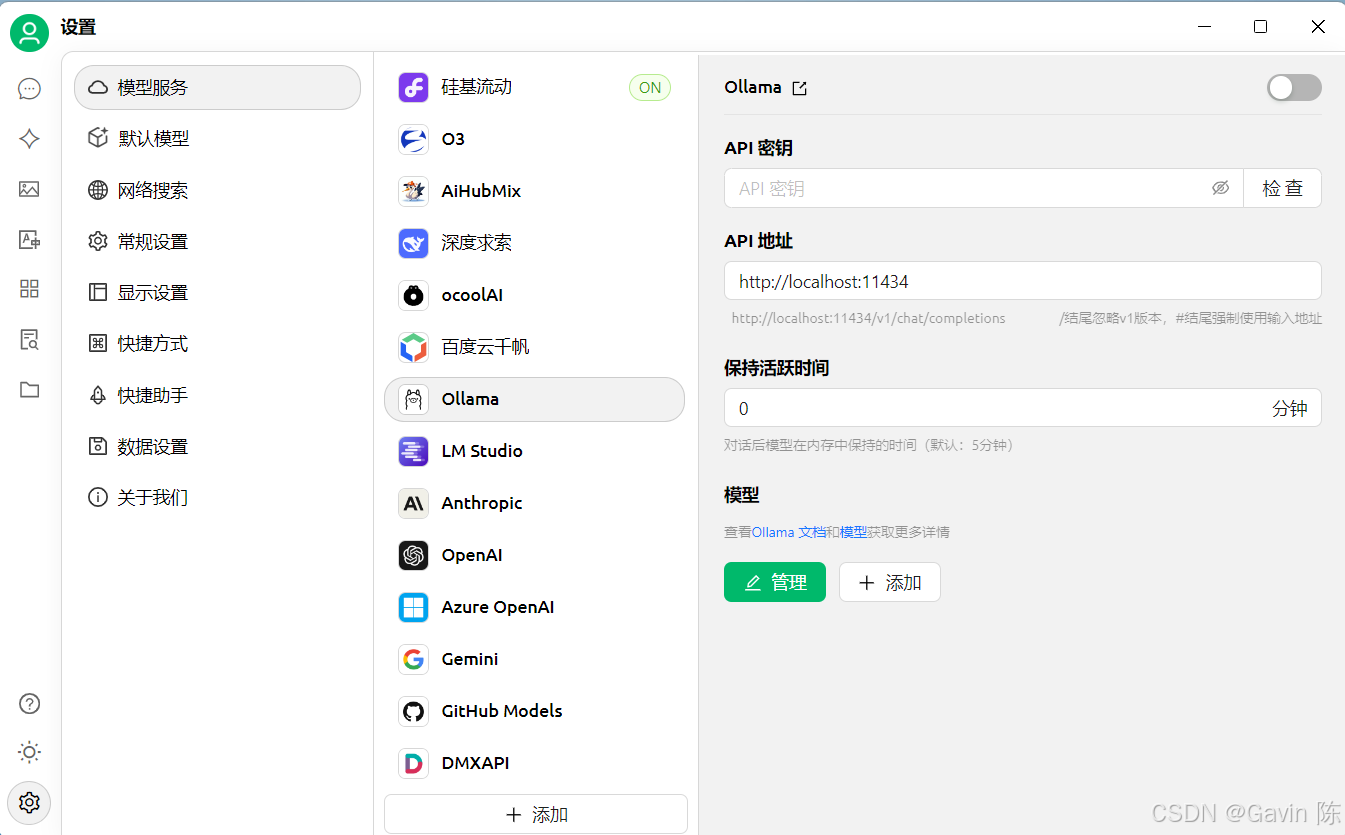
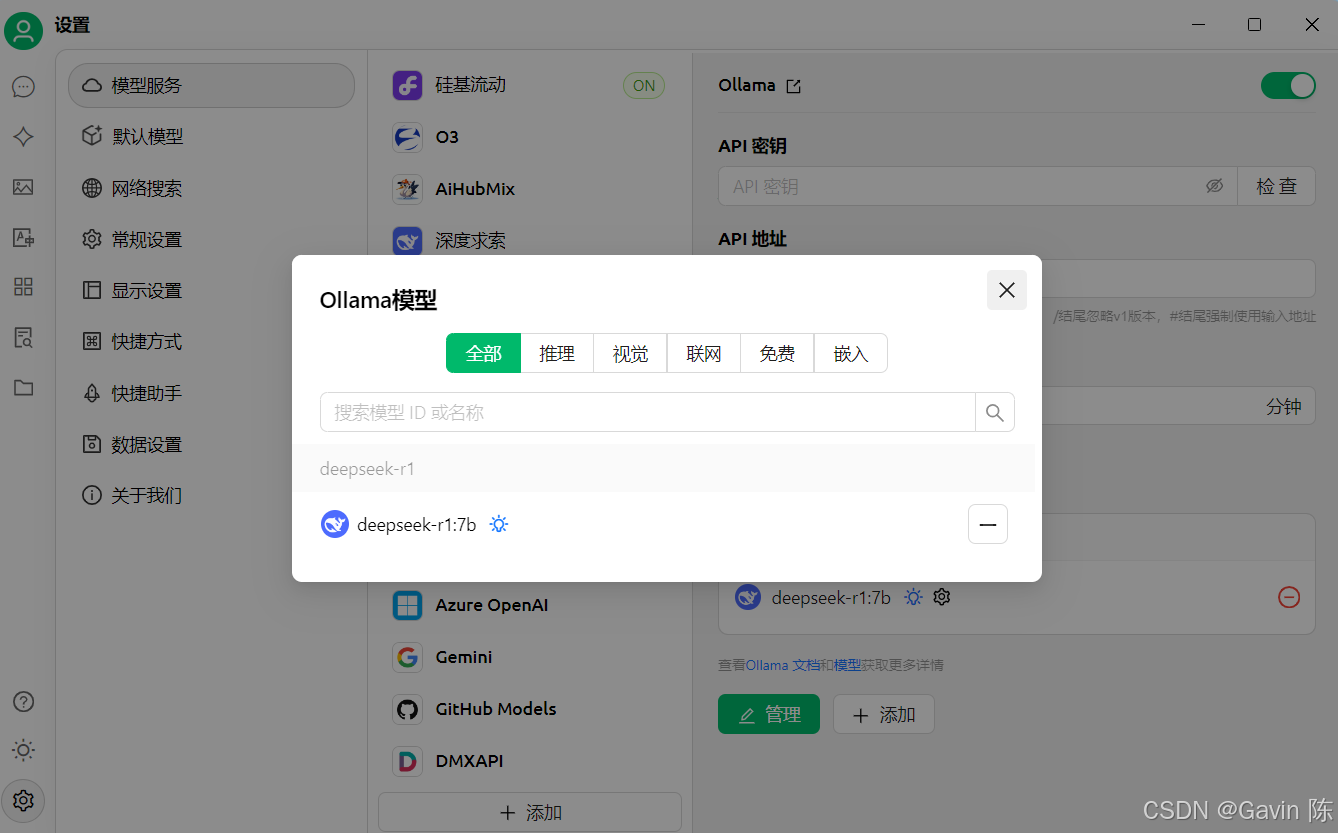
在模型服务中选择Ollama
点击“管理”进行模型选择,从模型列表中选择与你本地部署的 DeepSeek-R1 模型版本对应的选项,如果没有直接匹配项,选择支持自定义模型配置的入口。 在“API地址”中,将 API 地址设置为http://localhost:11434 ,这是 Ollama 服务的默认接口地址,确保 Cherry Studio 能连接到本地运行的 DeepSeek-R1 模型。
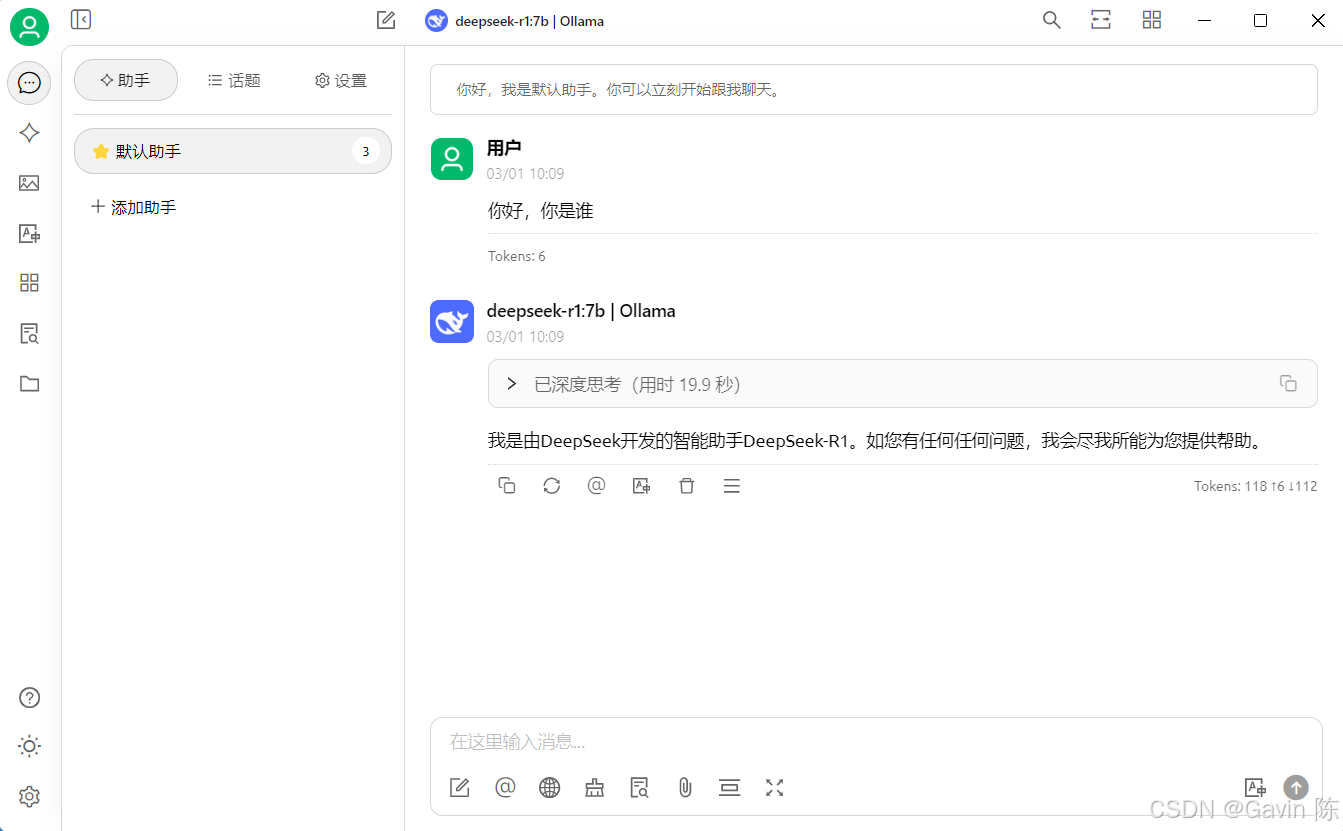
保存后,就可以创建助手与本地deepseek进行对话了。
安装RAGFlowRAGFlow使用Docker部署运行,因此需要先在电脑上部署Docker环境。同时本文采用从GitHub仓库直接拉取镜像部署的方式,因此也需要提前安装Git。
如果电脑没装Docker,可以参考Windows | Docker Docs 自行安装,本文使用WSL。
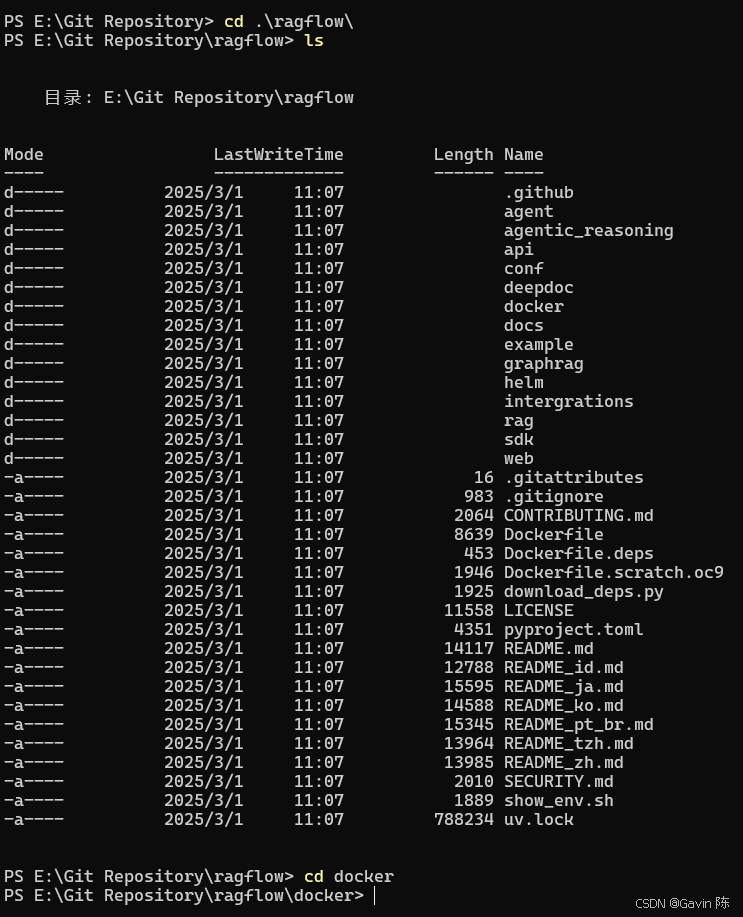
如果电脑没装Git,可以从Git - Downloading Package下载安装文件进行安装。 安装完毕后,进入命令行,将RAGFlow工程Clone到本地文件夹下。
进入 docker 文件夹
利用提前编译好的 Docker 镜像启动服务器: 运行以下命令会自动下载 RAGFlow slim Docker 镜像 v0.16.0-slim。
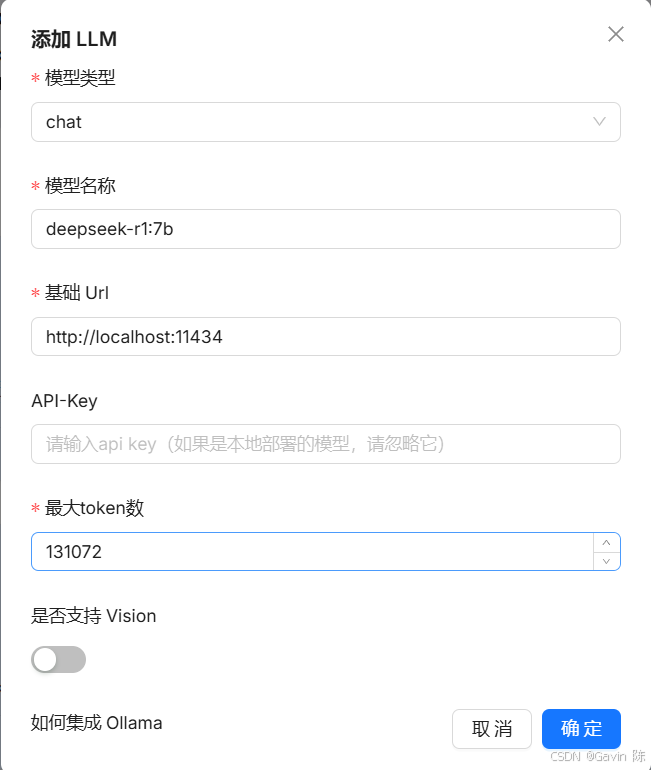
运行成功后,打开浏览器,登录localhost进入RAGFlow页面。注册账号后,就可以登录使用了。 设置知识库使用RAGFlow设置知识库,首先要在“模型提供商”中添加模型。必须要添加的有两个模型,一个是LLM模型,使用DeepSeek;另一个是嵌入模型,使用bge-m3。 在“待添加的模型”列表中选择“Ollama”,添加LLM.
“最大token数”可以通过如下命令获取后填入。
“基础Url”需要注意如果填写“http://localhost:11434”,会遇到“[Errno 111] Connection refused”的异常。原因是Docker中的程序访问不到本机的11434端口,可以参考 [Question]: Fail to access model(deepseek-r1:8b).**ERROR**: [Errno 111] Connection refused因此,此处要注意“基础Url”处填写:
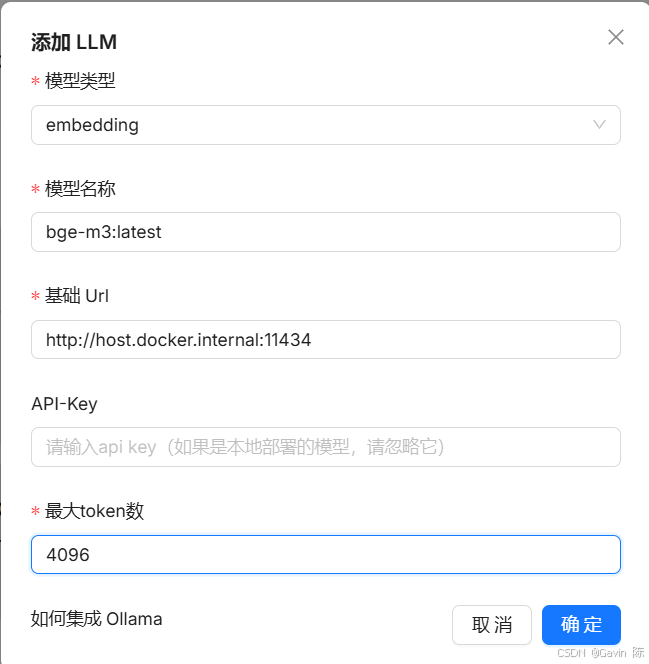
添加嵌入模型前,首先使用Ollama 安装bge-m3
然后配置嵌入模型。
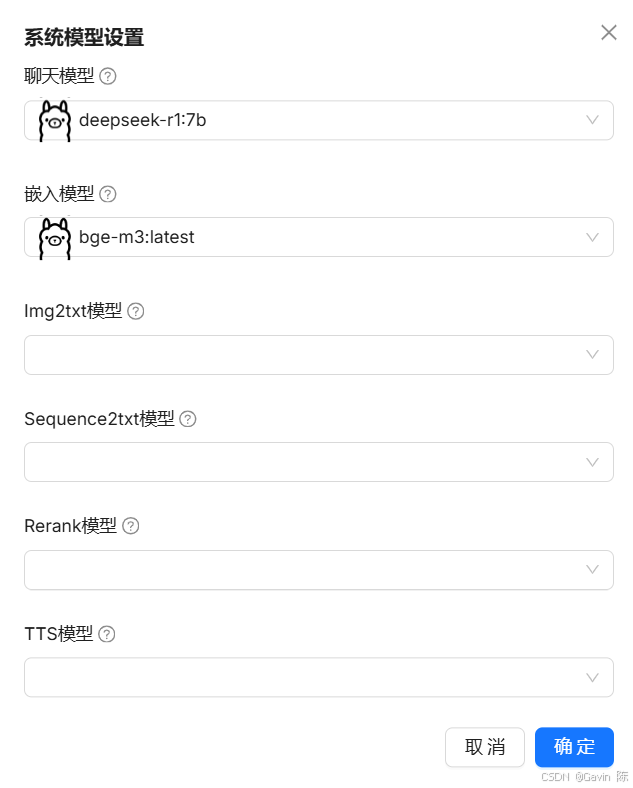
模型添加成功后,进入“系统模型设置”,选择添加的模型。
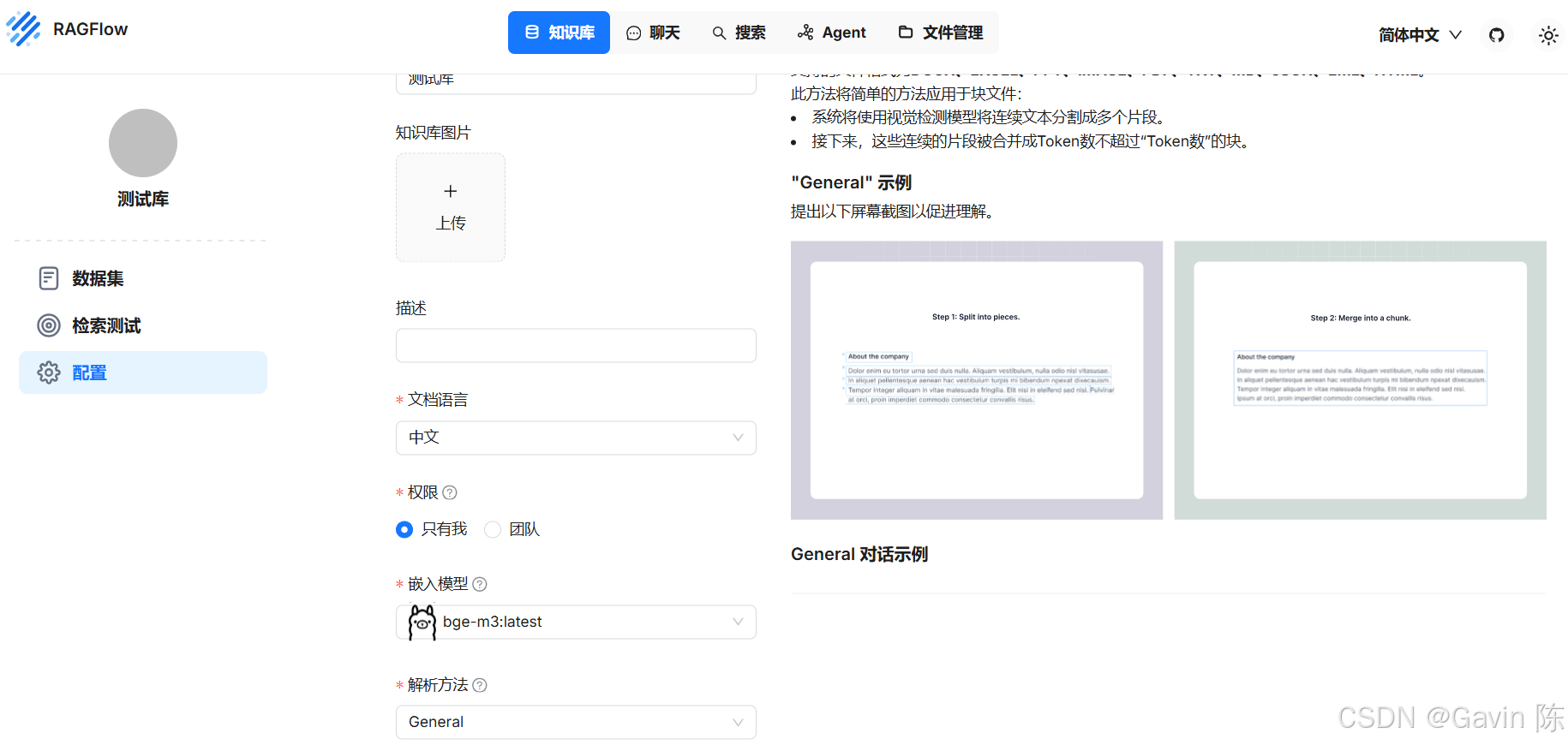
然后就可以创建知识库了。 在知识库设置中修改语言、权限、嵌入模型。
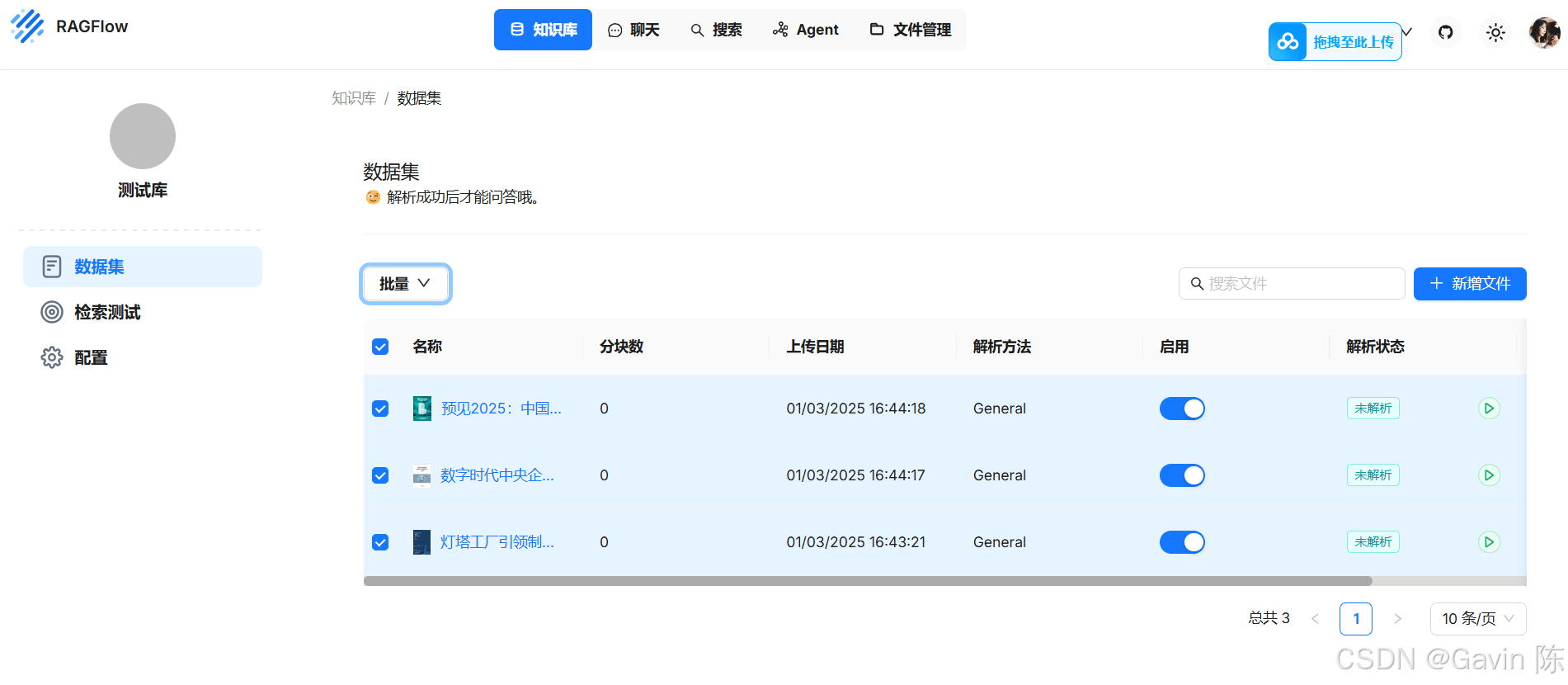
在“数据集”中上传所需的文档。
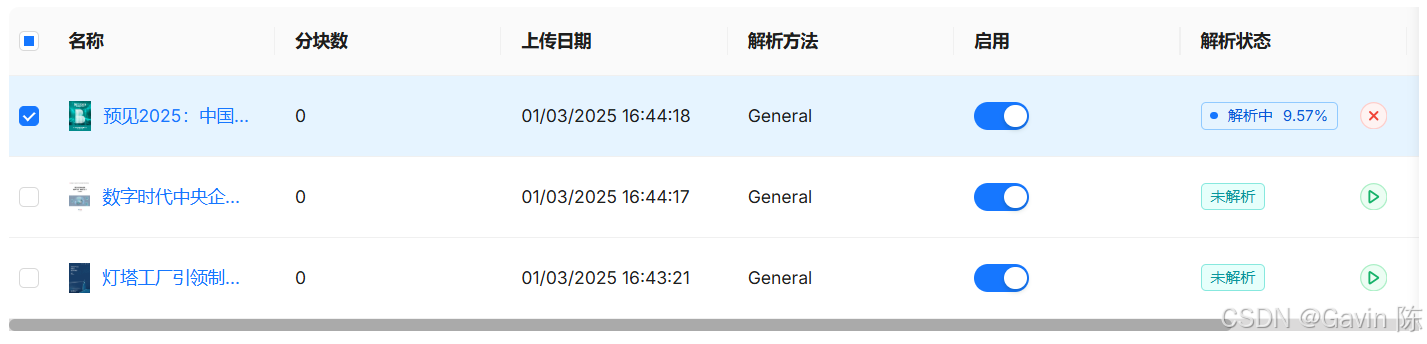
上传成功后,选择文档进行“解析”。
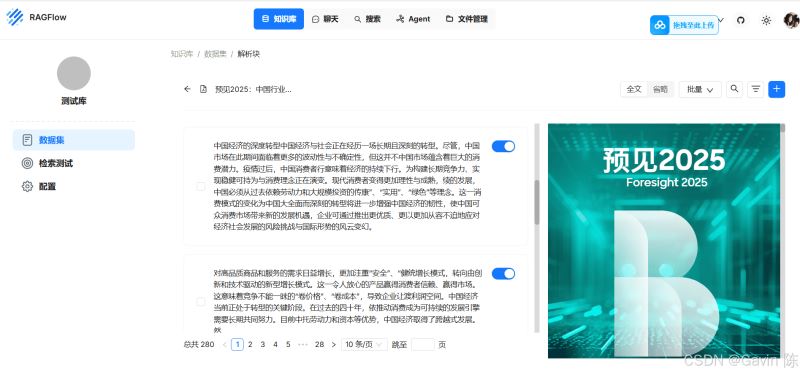
上传了几个PDF文档,解析的效果还不错。解析分段如果有不准确的地方,可以人工修正。
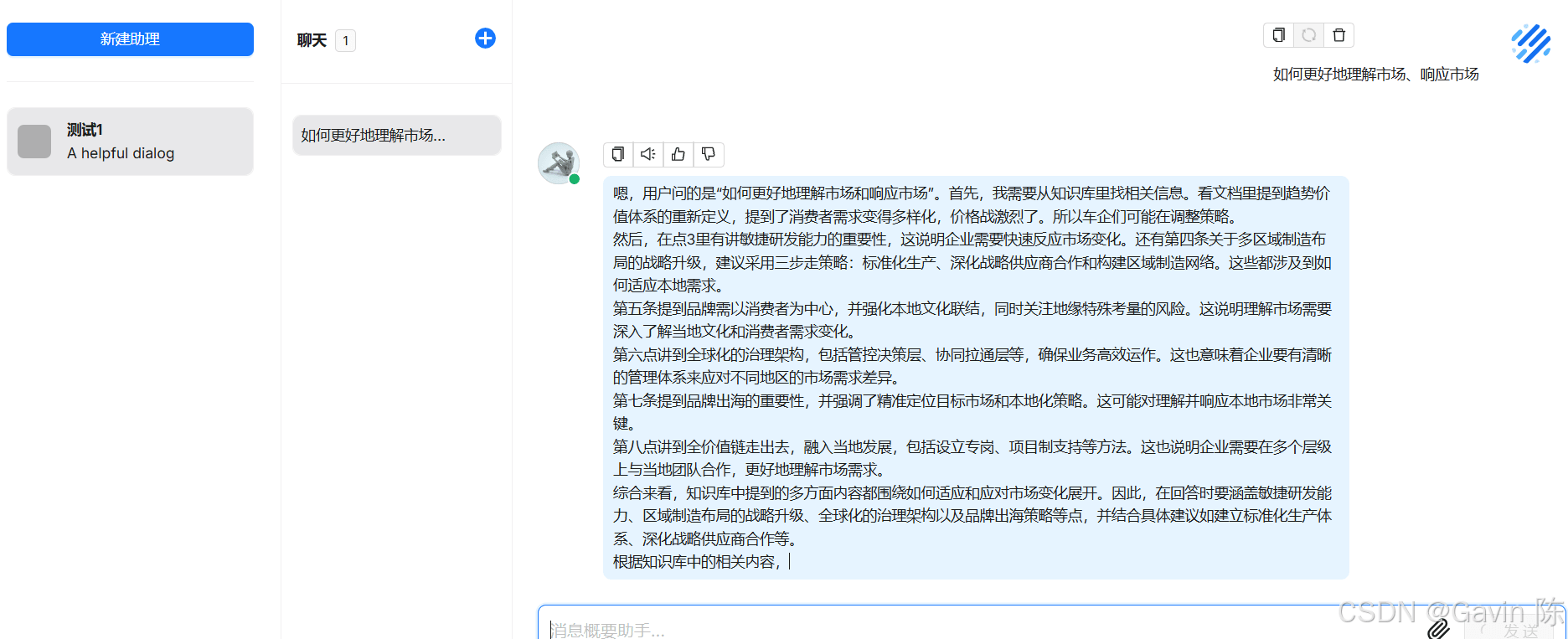
数据集准备就绪后,就可以“新建助理”,然后问问题了。
相比于互联网模型,个人知识库会从结合本地文档训练的数据集进行分析,更加符合个人专业诉求。 总结DeepSeek确实很香,搭配开源工具不花一分钱就搭建了一个定制化的知识库。从回答的逻辑和文档解析的效果看,都很不错。当然,本案例个人尝鲜可以,作企业商用还不行,抛开企业定制化和运维需求之外,主要问题有两个: 1. 个人笔记本的配置部署7b小模型已经是极限了,使用Cherry Studio做问答速度还可以。但使用RAGFlow做的个人知识库做问答,确实慢的要死。正式使用或企业商用,还是需要试用商用推荐配置。 2. 数据集质量极大影响知识库问答效果,因此高价值的原始数据以及对原始数据的解析整理十分重要。现在工具能力相当不错了,但数据工程将是企业数据库构建的主要挑战。 |
您可能感兴趣的文章 :
- 国内环境搭建私有知识问答库踩坑记录(ollama+deepseek+ragflow)
- 在VSCode中本地运行DeepSeek的流程
- 本地部署DeepSeek-R大模型的教程
- 高阶DeepSeek从入门到精通教程手册
- MAC快速本地部署Deepseek的实现介绍
- 基于DeepSeek-Coder的跨文件的代码
- 0基础租个硬件玩deepseek,蓝耘元生代智算云|本地部署DeepSeek R1模型的操作流程
- 在linux服务器本地部署Deepseek及在mac远程web-ui访问的操作
- 本地化部署DeepSeek 全攻略(linux、windows、mac系统部署)
- VScode内接入deepseek包过程记录

-
Windows安装与配置Ollama的图文教程
Windows安装与配置Ollama 简介 本节学习如何在 Windows 系统中完成 Ollama 的安装与配置,主要分为以下几个部分: 访问官网直接完成下载 环境变量 -
在VSCode中本地运行DeepSeek的流程
本文将分步向您展示如何在本地安装和运行 DeepSeek、使用 CodeGPT 对其进行配置以及开始利用 AI 来增强您的软件开发工作流程,所有这些都无 -
kafka开启kerberos认证的完整步骤
一、kerberos安装部署 kerberos的基本原理不做过多介绍了,可自行查阅;本文主要介绍kerberos的安装及使用;使用到的软件版本:系统:Red Hat -

高阶DeepSeek从入门到精通教程手册
第?章:准备篇(三分钟上手) 1.1 三分钟创建你的 AI 伙伴 1、访问官网:浏览器输?www.deepseek.com; 2、注册账号:点击开始对话,进入新用户 -
后端编程语言多方面对比:JAVA、C、C++、GO、PYT
软件开发领域,语言本身在各自领域都有适用场景,有许多流行的编程语言可供选择,每种语言都有其独特的特点和适用场景。 Java、C、C -
MAC快速本地部署Deepseek的实现介绍
下载安装ollama 地址:https://ollama.com/Ollama 是一个开源的大型语言模型(LLM)本地运行框架,旨在简化大模型的部署和管理流程,使开发者、研





-
解决Git Bash中文乱码的问题
2022-04-23
-
webp格式图片显示异常分析及解决方案
2023-04-23
-
typescript 实现RabbitMQ死信队列和延迟队
2024-04-08
-
git clone如何解决Permission Denied(publick
2024-11-15
-
Win10环境下编译和运行 x264的详细过程
2022-10-16

