原文 | Stephen Toub
翻译 | 郑子铭
堆栈替换 (On-Stack Replacement)
堆栈替换 (OSR) 是 .NET 7 中最酷的 JIT 功能之一。但要真正了解 OSR,我们首先需要了解分层编译 (tiered compilation),所以快速回顾一下……
具有 JIT 编译器的托管环境必须处理的问题之一是启动和吞吐量之间的权衡。从历史上看,优化编译器的工作就是优化,以便在运行时实现应用程序或服务的最佳吞吐量。但是这种优化需要分析,需要时间,并且执行所有这些工作会导致启动时间增加,因为启动路径上的所有代码(例如,在 Web 服务器可以为第一个请求提供服务之前需要运行的所有代码)需要编译。因此 JIT 编译器需要做出权衡:以更长的启动时间为代价获得更好的吞吐量,或者以降低吞吐量为代价获得更好的启动时间。对于某些类型的应用程序和服务,权衡很容易,例如如果您的服务启动一次然后运行数天,那么启动时间多几秒并不重要,或者如果您是一个控制台应用程序,它将进行快速计算并退出,启动时间才是最重要的。但是 JIT 如何知道它处于哪种场景中,我们真的希望每个开发人员都必须了解这些类型的设置和权衡并相应地配置他们的每个应用程序吗?对此的一种解决方案是提前编译,它在 .NET 中采用了多种形式。例如,所有核心库都是“crossgen”的,这意味着它们已经通过生成前面提到的 R2R 格式的工具运行,生成包含汇编代码的二进制文件,只需稍作调整即可实际执行;并非每个方法都可以为其生成代码,但足以显着减少启动时间。当然,这种方法有其自身的缺点,例如JIT 编译器的承诺之一是它可以利用当前机器/进程的知识来进行最佳优化,例如,R2R 图像必须采用特定的基线指令集(例如,哪些向量化指令可用),而JIT 可以看到实际可用的东西并使用最好的。 “分层编译”提供了另一种答案,无论是否使用这些其他提前 (ahead-of-time) (AOT) 编译解决方案,它都可以使用。
分层汇编使JIT能够拥有传说中的蛋糕,也能吃到它。这个想法很简单:允许 JIT 多次编译相同的代码。第一次,JIT 可以使用尽可能少的优化(少数优化实际上可以使 JIT 自身的吞吐量更快,因此应用这些优化仍然有意义),生成相当未优化的汇编代码,但这样做速度非常快。当它这样做时,它可以在程序集中添加一些工具来跟踪调用方法的频率。事实证明,启动路径上使用的许多函数只被调用一次或可能只被调用几次,优化它们比不优化地执行它们需要更多的时间。然后,当方法的检测触发某个阈值时,例如某个方法已执行 30 次,工作项将排队重新编译该方法,但这次 JIT 可以对其进行所有优化。这被亲切地称为“分层”。重新编译完成后,该方法的调用站点将使用新高度优化的汇编代码的地址进行修补,以后的调用将采用快速路径。因此,我们获得了更快的启动速度和更快的持续吞吐量。至少,这是希望。
然而,一个问题是不适合这种模式的方法。虽然许多对性能敏感的方法确实相对较快并且执行了很多很多次,但也有大量对性能敏感的方法只执行了几次,甚至可能只执行了一次,但是需要很长时间才能执行,甚至可能是整个过程的持续时间:带有循环的方法。因此,尽管可以通过将 DOTNET_TC_QuickJitForLoops 环境变量设置为 1 来启用它,但默认情况下分层编译并未应用于循环。我们可以通过使用 .NET 6 尝试这个简单的控制台应用程序来查看其效果。使用默认值设置,运行这个应用程序:
class Program
{
static void Main()
{
var sw = new System.Diagnostics.Stopwatch();
while (true)
{
sw.Restart();
for (int trial = 0; trial < 10_000; trial++)
{
int count = 0;
for (int i = 0; i < char.MaxValue; i++)
if (IsAsciiDigit((char)i))
count++;
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
}
static bool IsAsciiDigit(char c) => (uint)(c - '0') <= 9;
}
}
我打印出如下数字:
00:00:00.5734352
00:00:00.5526667
00:00:00.5675267
00:00:00.5588724
00:00:00.5616028
现在,尝试将 DOTNET_TC_QuickJitForLoops 设置为 1。当我再次运行它时,我得到如下数字:
00:00:01.2841397
00:00:01.2693485
00:00:01.2755646
00:00:01.2656678
00:00:01.2679925
换句话说,在启用 DOTNET_TC_QuickJitForLoops 的情况下,它花费的时间是不启用时的 2.5 倍(.NET 6 中的默认设置)。那是因为这个 main 函数永远不会对其应用优化。通过将 DOTNET_TC_QuickJitForLoops 设置为 1,我们说“JIT,请将分层也应用于带循环的方法”,但这种带循环的方法只会被调用一次,因此在整个过程中它最终保持在“层” -0”,也就是未优化。现在,让我们在 .NET 7 上尝试同样的事情。无论是否设置了环境变量,我都会再次得到这样的数字:
00:00:00.5528889
00:00:00.5562563
00:00:00.5622086
00:00:00.5668220
00:00:00.5589112
但重要的是,这种方法仍然参与分层。事实上,我们可以通过使用前面提到的 DOTNET_JitDisasmSummary=1 环境变量来确认这一点。当我设置它并再次运行时,我在输出中看到这些行:
4: JIT compiled Program:Main() [Tier0, IL size=83, code size=319]
...
6: JIT compiled Program:Main() [Tier1-OSR @0x27, IL size=83, code size=380]
强调 Main 确实被编译了两次。这怎么可能?堆栈替换。
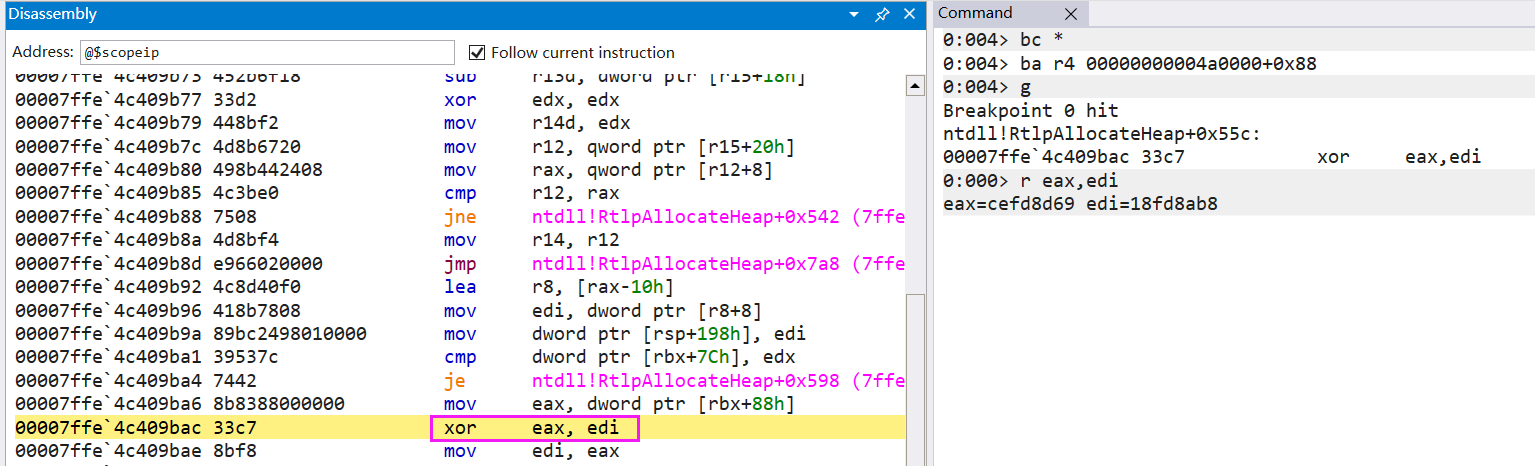
栈上替换背后的想法是一种方法不仅可以在调用之间替换,甚至可以在它执行时替换,当它“在堆栈上”时。除了用于调用计数的第 0 层代码外,循环还用于迭代计数。当迭代次数超过某个限制时,JIT 会编译该方法的一个高度优化的新版本,将所有本地/注册状态从当前调用转移到新调用,然后跳转到新方法中的适当位置。我们可以通过使用前面讨论的 DOTNET_JitDisasm 环境变量来实际看到这一点。将其设置为 Program:* 以查看为 Program 类中的所有方法生成的汇编代码,然后再次运行应用程序。您应该看到如下输出:
; Assembly listing for method Program:Main()
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-0 compilation
; MinOpts code
; rbp based frame
; partially interruptible
G_M000_IG01: ;; offset=0000H
55 push rbp
4881EC80000000 sub rsp, 128
488DAC2480000000 lea rbp, [rsp+80H]
C5D857E4 vxorps xmm4, xmm4
C5F97F65B0 vmovdqa xmmword ptr [rbp-50H], xmm4
33C0 xor eax, eax
488945C0 mov qword ptr [rbp-40H], rax
G_M000_IG02: ;; offset=001FH
48B9002F0B50FC7F0000 mov rcx, 0x7FFC500B2F00
E8721FB25F call CORINFO_HELP_NEWSFAST
488945B0 mov gword ptr [rbp-50H], rax
488B4DB0 mov rcx, gword ptr [rbp-50H]
FF1544C70D00 call [Stopwatch:.ctor():this]
488B4DB0 mov rcx, gword ptr [rbp-50H]
48894DC0 mov gword ptr [rbp-40H], rcx
C745A8E8030000 mov dword ptr [rbp-58H], 0x3E8
G_M000_IG03: ;; offset=004BH
8B4DA8 mov ecx, dword ptr [rbp-58H]
FFC9 dec ecx
894DA8 mov dword ptr [rbp-58H], ecx
837DA800 cmp dword ptr [rbp-58H], 0
7F0E jg SHORT G_M000_IG05
G_M000_IG04: ;; offset=0059H
488D4DA8 lea rcx, [rbp-58H]
BA06000000 mov edx, 6
E8B985AB5F call CORINFO_HELP_PATCHPOINT
G_M000_IG05: ;; offset=0067H
488B4DC0 mov rcx, gword ptr [rbp-40H]
3909 cmp dword ptr [rcx], ecx
FF1585C70D00 call [Stopwatch:Restart():this]
33C9 xor ecx, ecx
894DBC mov dword ptr [rbp-44H], ecx
33C9 xor ecx, ecx
894DB8 mov dword ptr [rbp-48H], ecx
EB20 jmp SHORT G_M000_IG08
G_M000_IG06: ;; offset=007FH
8B4DB8 mov ecx, dword ptr [rbp-48H]
0FB7C9 movzx rcx, cx
FF152DD40B00 call [Program:
g__IsAsciiDigit|0_0(ushort):bool] 85C0 test eax, eax 7408 je SHORT G_M000_IG07 8B4DBC mov ecx, dword ptr [rbp-44H] FFC1 inc ecx 894DBC mov dword ptr [rbp-44H], ecx G_M000_IG07: ;; offset=0097H 8B4DB8 mov ecx, dword ptr [rbp-48H] FFC1 inc ecx 894DB8 mov dword ptr [rbp-48H], ecx G_M000_IG08: ;; offset=009FH 8B4DA8 mov ecx, dword ptr [rbp-58H] FFC9 dec ecx 894DA8 mov dword ptr [rbp-58H], ecx 837DA800 cmp dword ptr [rbp-58H], 0 7F0E jg SHORT G_M000_IG10 G_M000_IG09: ;; offset=00ADH 488D4DA8 lea rcx, [rbp-58H] BA23000000 mov edx, 35 E86585AB5F call CORINFO_HELP_PATCHPOINT G_M000_IG10: ;; offset=00BBH 817DB800CA9A3B cmp dword ptr [rbp-48H], 0x3B9ACA00 7CBB jl SHORT G_M000_IG06 488B4DC0 mov rcx, gword ptr [rbp-40H] 3909 cmp dword ptr [rcx], ecx FF1570C70D00 call [Stopwatch:get_ElapsedMilliseconds():long:this] 488BC8 mov rcx, rax FF1507D00D00 call [Console:WriteLine(long)] E96DFFFFFF jmp G_M000_IG03 ; Total bytes of code 222 ; Assembly listing for method Program:
g__IsAsciiDigit|0_0(ushort):bool ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-0 compilation ; MinOpts code ; rbp based frame ; partially interruptible G_M000_IG01: ;; offset=0000H 55 push rbp 488BEC mov rbp, rsp 894D10 mov dword ptr [rbp+10H], ecx G_M000_IG02: ;; offset=0007H 8B4510 mov eax, dword ptr [rbp+10H] 0FB7C0 movzx rax, ax 83C0D0 add eax, -48 83F809 cmp eax, 9 0F96C0 setbe al 0FB6C0 movzx rax, al G_M000_IG03: ;; offset=0019H 5D pop rbp C3 ret 这里需要注意一些相关的事情。首先,顶部的注释强调了这段代码是如何编译的:
; Tier-0 compilation
; MinOpts code
因此,我们知道这是使用最小优化(“MinOpts”)编译的方法的初始版本(“Tier-0”)。其次,注意汇编的这一行:
FF152DD40B00 call [Program:
g__IsAsciiDigit|0_0(ushort):bool] 我们的 IsAsciiDigit 辅助方法很容易内联,但它没有被内联;相反,程序集调用了它,实际上我们可以在下面看到为 IsAsciiDigit 生成的代码(也称为“MinOpts”)。为什么?因为内联是一种优化(一个非常重要的优化),它作为第 0 层的一部分被禁用(因为做好内联的分析也非常昂贵)。第三,我们可以看到 JIT 输出的代码来检测这个方法。这有点复杂,但我会指出相关部分。首先,我们看到:
C745A8E8030000 mov dword ptr [rbp-58H], 0x3E8
0x3E8 是十进制 1,000 的十六进制值,这是在 JIT 生成方法的优化版本之前循环需要迭代的默认迭代次数(这可以通过 DOTNET_TC_OnStackReplacement_InitialCounter 环境变量进行配置)。所以我们看到 1,000 被存储到这个堆栈位置。然后稍后在方法中我们看到这个:
G_M000_IG03: ;; offset=004BH
8B4DA8 mov ecx, dword ptr [rbp-58H]
FFC9 dec ecx
894DA8 mov dword ptr [rbp-58H], ecx
837DA800 cmp dword ptr [rbp-58H], 0
7F0E jg SHORT G_M000_IG05
G_M000_IG04: ;; offset=0059H
488D4DA8 lea rcx, [rbp-58H]
BA06000000 mov edx, 6
E8B985AB5F call CORINFO_HELP_PATCHPOINT
G_M000_IG05: ;; offset=0067H
生成的代码将该计数器加载到 ecx 寄存器中,递减它,将其存储回去,然后查看计数器是否降为 0。如果没有,代码跳到 G_M000_IG05,这是实际代码的标签循环的其余部分。但是,如果计数器确实降为 0,JIT 会继续将相关状态存储到 rcx 和 edx 寄存器中,然后调用 CORINFO_HELP_PATCHPOINT 辅助方法。该助手负责触发优化方法的创建(如果尚不存在)、修复所有适当的跟踪状态并跳转到新方法。事实上,如果您再次查看运行该程序的控制台输出,您会看到 Main 方法的另一个输出:
; Assembly listing for method Program:Main()
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-1 compilation
; OSR variant for entry point 0x23
; optimized code
; rsp based frame
; fully interruptible
; No PGO data
; 1 inlinees with PGO data; 8 single block inlinees; 0 inlinees without PGO data
G_M000_IG01: ;; offset=0000H
4883EC58 sub rsp, 88
4889BC24D8000000 mov qword ptr [rsp+D8H], rdi
4889B424D0000000 mov qword ptr [rsp+D0H], rsi
48899C24C8000000 mov qword ptr [rsp+C8H], rbx
C5F877 vzeroupper
33C0 xor eax, eax
4889442428 mov qword ptr [rsp+28H], rax
4889442420 mov qword ptr [rsp+20H], rax
488B9C24A0000000 mov rbx, gword ptr [rsp+A0H]
8BBC249C000000 mov edi, dword ptr [rsp+9CH]
8BB42498000000 mov esi, dword ptr [rsp+98H]
G_M000_IG02: ;; offset=0041H
EB45 jmp SHORT G_M000_IG05
align [0 bytes for IG06]
G_M000_IG03: ;; offset=0043H
33C9 xor ecx, ecx
488B9C24A0000000 mov rbx, gword ptr [rsp+A0H]
48894B08 mov qword ptr [rbx+08H], rcx
488D4C2428 lea rcx, [rsp+28H]
48B87066E68AFD7F0000 mov rax, 0x7FFD8AE66670
G_M000_IG04: ;; offset=0060H
FFD0 call rax ; Kernel32:QueryPerformanceCounter(long):int
488B442428 mov rax, qword ptr [rsp+28H]
488B9C24A0000000 mov rbx, gword ptr [rsp+A0H]
48894310 mov qword ptr [rbx+10H], rax
C6431801 mov byte ptr [rbx+18H], 1
33FF xor edi, edi
33F6 xor esi, esi
833D92A1E55F00 cmp dword ptr [(reloc 0x7ffcafe1ae34)], 0
0F85CA000000 jne G_M000_IG13
G_M000_IG05: ;; offset=0088H
81FE00CA9A3B cmp esi, 0x3B9ACA00
7D17 jge SHORT G_M000_IG09
G_M000_IG06: ;; offset=0090H
0FB7CE movzx rcx, si
83C1D0 add ecx, -48
83F909 cmp ecx, 9
7702 ja SHORT G_M000_IG08
G_M000_IG07: ;; offset=009BH
FFC7 inc edi
G_M000_IG08: ;; offset=009DH
FFC6 inc esi
81FE00CA9A3B cmp esi, 0x3B9ACA00
7CE9 jl SHORT G_M000_IG06
G_M000_IG09: ;; offset=00A7H
488B6B08 mov rbp, qword ptr [rbx+08H]
48899C24A0000000 mov gword ptr [rsp+A0H], rbx
807B1800 cmp byte ptr [rbx+18H], 0
7436 je SHORT G_M000_IG12
G_M000_IG10: ;; offset=00B9H
488D4C2420 lea rcx, [rsp+20H]
48B87066E68AFD7F0000 mov rax, 0x7FFD8AE66670
G_M000_IG11: ;; offset=00C8H
FFD0 call rax ; Kernel32:QueryPerformanceCounter(long):int
488B4C2420 mov rcx, qword ptr [rsp+20H]
488B9C24A0000000 mov rbx, gword ptr [rsp+A0H]
482B4B10 sub rcx, qword ptr [rbx+10H]
4803E9 add rbp, rcx
833D2FA1E55F00 cmp dword ptr [(reloc 0x7ffcafe1ae34)], 0
48899C24A0000000 mov gword ptr [rsp+A0H], rbx
756D jne SHORT G_M000_IG14
G_M000_IG12: ;; offset=00EFH
C5F857C0 vxorps xmm0, xmm0
C4E1FB2AC5 vcvtsi2sd xmm0, rbp
C5FB11442430 vmovsd qword ptr [rsp+30H], xmm0
48B9F04BF24FFC7F0000 mov rcx, 0x7FFC4FF24BF0
BAE7070000 mov edx, 0x7E7
E82E1FB25F call CORINFO_HELP_GETSHARED_NONGCSTATIC_BASE
C5FB10442430 vmovsd xmm0, qword ptr [rsp+30H]
C5FB5905E049F6FF vmulsd xmm0, xmm0, qword ptr [(reloc 0x7ffc4ff25720)]
C4E1FB2CD0 vcvttsd2si rdx, xmm0
48B94B598638D6C56D34 mov rcx, 0x346DC5D63886594B
488BC1 mov rax, rcx
48F7EA imul rdx:rax, rdx
488BCA mov rcx, rdx
48C1E93F shr rcx, 63
48C1FA0B sar rdx, 11
4803CA add rcx, rdx
FF1567CE0D00 call [Console:WriteLine(long)]
E9F5FEFFFF jmp G_M000_IG03
G_M000_IG13: ;; offset=014EH
E8DDCBAC5F call CORINFO_HELP_POLL_GC
E930FFFFFF jmp G_M000_IG05
G_M000_IG14: ;; offset=0158H
E8D3CBAC5F call CORINFO_HELP_POLL_GC
EB90 jmp SHORT G_M000_IG12
; Total bytes of code 351
在这里,我们再次注意到一些有趣的事情。首先,在标题中我们看到了这个:
; Tier-1 compilation
; OSR variant for entry point 0x23
; optimized code
所以我们知道这既是优化的“一级”代码,也是该方法的“OSR 变体”。其次,请注意不再调用 IsAsciiDigit 帮助程序。相反,在该调用的位置,我们看到了这一点:
G_M000_IG06: ;; offset=0090H
0FB7CE movzx rcx, si
83C1D0 add ecx, -48
83F909 cmp ecx, 9
7702 ja SHORT G_M000_IG08
这是将一个值加载到 rcx 中,从中减去 48(48 是“0”字符的十进制 ASCII 值)并将结果值与 9 进行比较。听起来很像我们的 IsAsciiDigit 实现 ((uint)(c - ' 0') <= 9),不是吗?那是因为它是。帮助程序已成功内联到这个现在优化的代码中。
太好了,现在在 .NET 7 中,我们可以在很大程度上避免启动和吞吐量之间的权衡,因为 OSR 支持分层编译以应用于所有方法,即使是那些长时间运行的方法。许多 PR 都致力于实现这一点,包括过去几年的许多 PR,但所有功能在发布时都被禁用了。感谢 dotnet/runtime#62831 等改进,它在 Arm64 上实现了对 OSR 的支持(以前只实现了 x64 支持),以及 dotnet/runtime#63406 和 dotnet/runtime#65609 修改了 OSR 导入和 epilogs 的处理方式,dotnet/runtime #65675 默认启用 OSR(并因此启用 DOTNET_TC_QuickJitForLoops)。
但是,分层编译和 OSR 不仅仅与启动有关(尽管它们在那里当然非常有价值)。它们还涉及进一步提高吞吐量。尽管分层编译最初被设想为一种在不损害吞吐量的情况下优化启动的方法,但它已经变得远不止于此。 JIT 可以在第 0 层期间了解有关方法的各种信息,然后将其用于第 1 层。例如,执行第 0 层代码这一事实意味着该方法访问的任何静态都将被初始化,这意味着任何只读静态不仅会在第 1 层代码执行时被初始化,而且它们的价值观永远不会改变。这反过来意味着原始类型(例如 bool、int 等)的任何只读静态都可以像常量一样对待,而不是静态只读字段,并且在第 1 层编译期间,JIT 可以优化它们,就像它优化一个常量。例如,在将 DOTNET_JitDisasm 设置为 Program:Test 后尝试运行这个简单的程序:
using System.Runtime.CompilerServices;
class Program
{
static readonly bool Is64Bit = Environment.Is64BitProcess;
static int Main()
{
int count = 0;
for (int i = 0; i < 1_000_000_000; i++)
if (Test())
count++;
return count;
}
[MethodImpl(MethodImplOptions.NoInlining)]
static bool Test() => Is64Bit;
}
当我这样做时,我得到以下输出:
; Assembly listing for method Program:Test():bool
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-0 compilation
; MinOpts code
; rbp based frame
; partially interruptible
G_M000_IG01: ;; offset=0000H
55 push rbp
4883EC20 sub rsp, 32
488D6C2420 lea rbp, [rsp+20H]
G_M000_IG02: ;; offset=000AH
48B9B8639A3FFC7F0000 mov rcx, 0x7FFC3F9A63B8
BA01000000 mov edx, 1
E8C220B25F call CORINFO_HELP_GETSHARED_NONGCSTATIC_BASE
0FB60545580C00 movzx rax, byte ptr [(reloc 0x7ffc3f9a63ea)]
G_M000_IG03: ;; offset=0025H
4883C420 add rsp, 32
5D pop rbp
C3 ret
; Total bytes of code 43
; Assembly listing for method Program:Test():bool
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-1 compilation
; optimized code
; rsp based frame
; partially interruptible
; No PGO data
G_M000_IG01: ;; offset=0000H
G_M000_IG02: ;; offset=0000H
B801000000 mov eax, 1
G_M000_IG03: ;; offset=0005H
C3 ret
; Total bytes of code 6
请注意,我们再次看到 Program:Test 的两个输出。首先,我们看到“第 0 层”代码,它正在访问静态(注意调用 CORINFO_HELP_GETSHARED_NONGCSTATIC_BASE 指令)。但随后我们看到“Tier-1”代码,其中所有开销都消失了,取而代之的是 mov eax, 1。由于必须执行“Tier-0”代码才能使其分层, “Tier-1”代码是在知道 static readonly bool Is64Bit 字段的值为 true (1) 的情况下生成的,因此该方法的全部内容是将值 1 存储到用于返回值的 eax 寄存器中。
这非常有用,以至于现在在编写组件时都考虑到了分层。考虑一下新的 Regex 源代码生成器,这将在本文后面讨论(Roslyn 源代码生成器是几年前推出的;就像 Roslyn 分析器如何能够插入编译器并根据编译器的所有数据进行额外的诊断一样从源代码中学习,Roslyn 源代码生成器能够分析相同的数据,然后使用额外的源进一步扩充编译单元)。正则表达式源生成器在 dotnet/runtime#67775 中应用了基于此的技术。 Regex 支持设置一个进程范围的超时,该超时应用于未明确设置超时的 Regex 实例。这意味着,即使设置这种进程范围的超时非常罕见,Regex 源代码生成器仍然需要输出与超时相关的代码,以备不时之需。它通过输出一些像这样的助手来做到这一点:
static class Utilities
{
internal static readonly TimeSpan s_defaultTimeout = AppContext.GetData("REGEX_DEFAULT_MATCH_TIMEOUT") is TimeSpan timeout ? timeout : Timeout.InfiniteTimeSpan;
internal static readonly bool s_hasTimeout = s_defaultTimeout != Timeout.InfiniteTimeSpan;
}
然后它在这样的呼叫站点使用它:
if (Utilities.s_hasTimeout)
{
base.CheckTimeout();
}
在第 0 层中,这些检查仍将在汇编代码中发出,但在吞吐量很重要的第 1 层中,如果尚未设置相关的 AppContext 开关,则 s_defaultTimeout 将为 Timeout.InfiniteTimeSpan,此时 s_hasTimeout 将为错误的。并且由于 s_hasTimeout 是一个静态只读布尔值,JIT 将能够将其视为一个常量,并且所有条件如 if (Utilities.s_hasTimeout) 将被视为等于 if (false) 并从汇编代码中完全消除为死代码。
但是,这有点旧闻了。自从 .NET Core 3.0 中引入分层编译以来,JIT 已经能够进行这样的优化。不过,现在在 .NET 7 中,有了 OSR,它也可以默认为带循环的方法这样做(从而启用像正则表达式这样的情况)。然而,OSR 的真正魔力在与另一个令人兴奋的功能结合使用时才会发挥作用:动态 PGO。
原文链接
Performance Improvements in .NET 7
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
欢迎转载、使用、重新发布,但务必保留文章署名 郑子铭 (包含链接: http://www.cnblogs.com/MingsonZheng/ ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。
如有任何疑问,请与我联系 (MingsonZheng@outlook.com)