前言 日常业务开发中离不开字符串的拼接操作,不同语言的字符串实现方式都不同,在Go语言中就提供了6种方式进行字符串拼接,那这几种拼接方式该如何选择呢?使用那个更高效呢?
前言
string类型我们首先来了解一下Go语言中string类型的结构定义,先来看一下官方定义:
string是一个8位字节的集合,通常但不一定代表UTF-8编码的文本。string可以为空,但是不能为nil。string的值是不能改变的。 string类型本质也是一个结构体,定义如下:
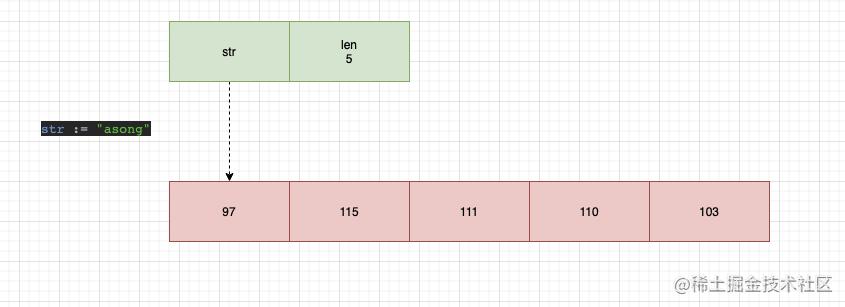
stringStruct和slice还是很相似的,str指针指向的是某个数组的首地址,len代表的就是数组长度。怎么和slice这么相似,底层指向的也是数组,是什么数组呢?我们看看他在实例化时调用的方法:
入参是一个byte类型的指针,从这我们可以看出string类型底层是一个byte类型的数组,所以我们可以画出这样一个图片:
string类型本质上就是一个byte类型的数组,在Go语言中string类型被设计为不可变的,不仅是在Go语言,其他语言中string类型也是被设计为不可变的,这样的好处就是:在并发场景下,我们可以在不加锁的控制下,多次使用同一字符串,在保证高效共享的情况下而不用担心安全问题。 string类型虽然是不能更改的,但是可以被替换,因为stringStruct中的str指针是可以改变的,只是指针指向的内容是不可以改变的,也就说每一个更改字符串,就需要重新分配一次内存,之前分配的空间会被gc回收。 关于string类型的知识点就描述这么多,方便我们后面分析字符串拼接。 字符串拼接的6种方式及原理原生拼接方式"+"Go语言原生支持使用+操作符直接对两个字符串进行拼接,使用例子如下:
这种方式使用起来最简单,基本所有语言都有提供这种方式,使用+操作符进行拼接时,会对字符串进行遍历,计算并开辟一个新的空间来存储原来的两个字符串。 字符串格式化函数fmt.SprintfGo语言中默认使用函数fmt.Sprintf进行字符串格式化,所以也可使用这种方式进行字符串拼接:
fmt.Sprintf实现原理主要是使用到了反射,具体源码分析因为篇幅的原因就不在这里详细分析了,看到反射,就会产生性能的损耗,你们懂得!!! Strings.builderGo语言提供了一个专门操作字符串的库strings,使用strings.Builder可以进行字符串拼接,提供了writeString方法拼接字符串,使用方式如下:
strings.builder的实现原理很简单,结构如下:
addr字段主要是做copycheck,buf字段是一个byte类型的切片,这个就是用来存放字符串内容的,提供的writeString()方法就是像切片buf中追加数据:
提供的String方法就是将[]]byte转换为string类型,这里为了避免内存拷贝的问题,使用了强制转换来避免内存拷贝:
bytes.Buffer因为string类型底层就是一个byte数组,所以我们就可以Go语言的bytes.Buffer进行字符串拼接。bytes.Buffer是一个一个缓冲byte类型的缓冲器,这个缓冲器里存放着都是byte。使用方式如下:
bytes.buffer底层也是一个[]byte切片,结构体如下:
因为bytes.Buffer可以持续向Buffer尾部写入数据,从Buffer头部读取数据,所以off字段用来记录读取位置,再利用切片的cap特性来知道写入位置,这个不是本次的重点,重点看一下WriteString方法是如何拼接字符串的:
切片在创建时并不会申请内存块,只有在往里写数据时才会申请,首次申请的大小即为写入数据的大小。如果写入的数据小于64字节,则按64字节申请。采用动态扩展slice的机制,字符串追加采用copy的方式将追加的部分拷贝到尾部,copy是内置的拷贝函数,可以减少内存分配。 但是在将[]byte转换为string类型依旧使用了标准类型,所以会发生内存分配:
strings.joinStrings.join方法可以将一个string类型的切片拼接成一个字符串,可以定义连接操作符,使用如下:
strings.join也是基于strings.builder来实现的,代码如下:
唯一不同在于在join方法内调用了b.Grow(n)方法,这个是进行初步的容量分配,而前面计算的n的长度就是我们要拼接的slice的长度,因为我们传入切片长度固定,所以提前进行容量分配可以减少内存分配,很高效。 切片append因为string类型底层也是byte类型数组,所以我们可以重新声明一个切片,使用append进行字符串拼接,使用方式如下:
如果想减少内存分配,在将[]byte转换为string类型时可以考虑使用强制转换。 Benchmark对比上面我们总共提供了6种方法,原理我们基本知道了,那么我们就使用Go语言中的Benchmark来分析一下到底哪种字符串拼接方式更高效。我们主要分两种情况进行分析:
因为代码量有点多,下面只贴出分析结果,详细代码已经上传github:https://github.com/asong2020/Golang_Dream/tree/master/code_demo/string_join 我们先定义一个基础字符串:
少量字符串拼接的测试我们就采用拼接一次的方式验证,base拼接base,因此得出benckmark结果:
大量字符串拼接的测试我们先构建一个长度为200的字符串切片:
然后遍历这个切片不断的进行拼接,因为可以得出benchmark:
结论通过两次benchmark对比,我们可以看到当进行少量字符串拼接时,直接使用+操作符进行拼接字符串,效率还是挺高的,但是当要拼接的字符串数量上来时,+操作符的性能就比较低了;函数fmt.Sprintf还是不适合进行字符串拼接,无论拼接字符串数量多少,性能损耗都很大,还是老老实实做他的字符串格式化就好了;strings.Builder无论是少量字符串的拼接还是大量的字符串拼接,性能一直都能稳定,这也是为什么Go语言官方推荐使用strings.builder进行字符串拼接的原因,在使用strings.builder时最好使用Grow方法进行初步的容量分配,观察strings.join方法的benchmark就可以发现,因为使用了grow方法,提前分配好内存,在字符串拼接的过程中,不需要进行字符串的拷贝,也不需要分配新的内存,这样使用strings.builder性能最好,且内存消耗最小。bytes.Buffer方法性能是低于strings.builder的,bytes.Buffer 转化为字符串时重新申请了一块空间,存放生成的字符串变量,不像strings.buidler这样直接将底层的 []byte 转换成了字符串类型返回,这就占用了更多的空间。 同步最后分析的结论: 无论什么情况下使用strings.builder进行字符串拼接都是最高效的,不过要主要使用方法,记得调用grow进行容量分配,才会高效。strings.join的性能约等于strings.builder,在已经字符串slice的时候可以使用,未知时不建议使用,构造切片也是有性能损耗的;如果进行少量的字符串拼接时,直接使用+操作符是最方便也是性能最高的,可以放弃strings.builder的使用。 综合对比性能排序: strings.join ≈ strings.builder > bytes.buffer > []byte转换string > "+" > fmt.sprintf 总结本文我们针对6种字符串的拼接方式进行介绍,并通过benckmark对比了效率,无论什么时候使用strings.builder都不会错,但是在少量字符串拼接时,直接+也就是更优的方式,具体业务场景具体分析,不要一概而论。 文中代码已上传github:https://github.com/asong2020/Golang_Dream/tree/master/code_demo/string_join |




2022-04-28
2022-04-21
2022-05-13
2022-08-17
2022-02-25