软件架构
mnist数据集的识别使用了两个非常小的网络来实现,第一个是最简单的全连接网络,第二个是卷积网络,mnist数据集是入门数据集,所以不需要进行图像增强,或者用生成器读入内存,直接使用简单的fit()命令就可以一次性训练
安装教程
-
使用到的主要第三方库有tensorflow1.x,基于TensorFlow的Keras,基础的库包括numpy,matplotlib
-
安装方式也很简答,例如:pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
-
注意tensorflow版本不能是2.x
使用说明
-
首先,我们预览数据集,运行mnistplt.py,绘制了4张训练用到的图像
-
训练全连接网络则运行Densemnist.py,得到权重Dense.h5,加载模型并预测运行Denseload.py
-
训练卷积网络则运行CNNmnist.py,得到权重CNN.h5,加载模型并预测运行CNNload.py
结果图
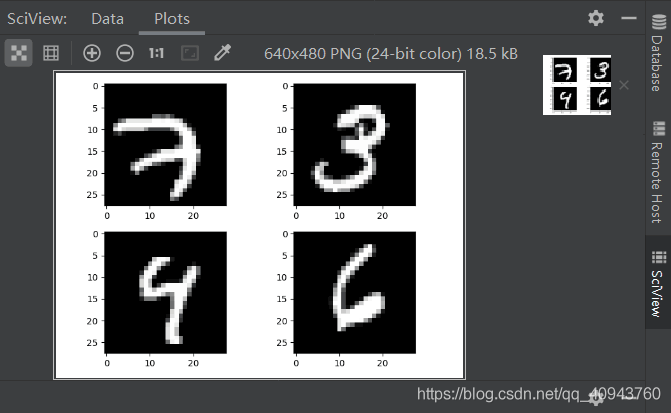
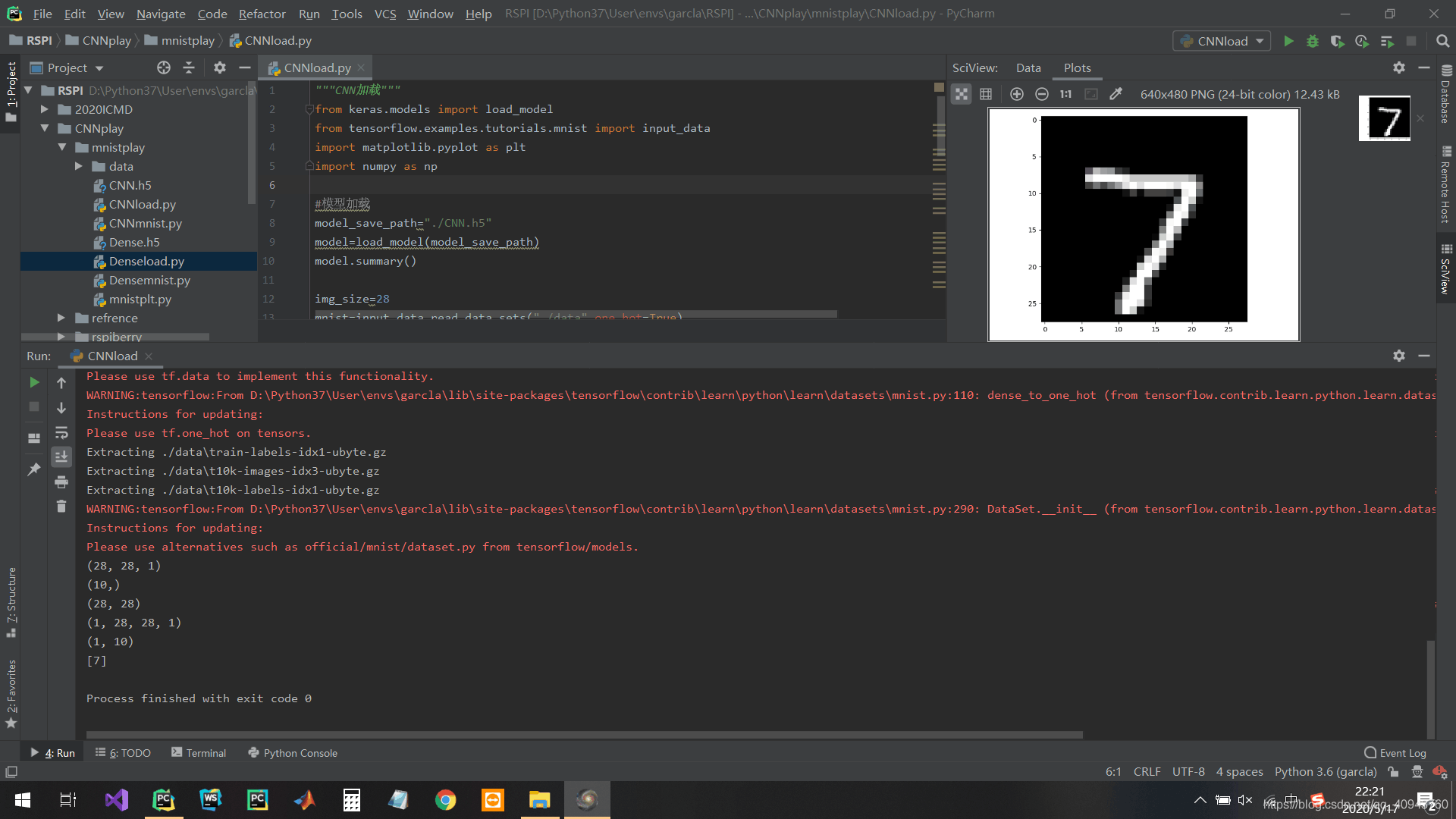
训练过程注释
全连接网络训练:
"""多层感知机训练"""
from tensorflow.examples.tutorials.mnist import input_data
from keras.models import Sequential
from keras.layers import Dense
#模拟原始灰度数据读入
img_size=28
num=10
mnist=input_data.read_data_sets("./data",one_hot=True)
X_train,y_train,X_test,y_test=mnist.train.images,mnist.train.labels,mnist.test.images,mnist.test.labels
X_train=X_train.reshape(-1,img_size,img_size)
X_test=X_test.reshape(-1,img_size,img_size)
X_train=X_train*255
X_test=X_test*255
y_train=y_train.reshape(-1,num)
y_test=y_test.reshape(-1,num)
print(X_train.shape)
print(y_train.shape)
#全连接层只能输入一维
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0],num_pixels).astype('float32')
X_test = X_test.reshape(X_test.shape[0],num_pixels).astype('float32')
#归一化
X_train=X_train/255
X_test=X_test/255
# one hot编码,这里编好了,省略
#y_train = np_utils.to_categorical(y_train)
#y_test = np_utils.to_categorical(y_test)
#搭建网络
def baseline():
"""
optimizer:优化器,如Adam
loss:计算损失,当使用categorical_crossentropy损失函数时,标签应为多类模式,例如如果你有10个类别,
每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0
metrics: 列表,包含评估模型在训练和测试时的性能的指标
"""
model=Sequential()
#第一步是确定输入层的数目:在创建模型时用input_dim参数确定,例如,有784个个输入变量,就设成num_pixels。
#全连接层用Dense类定义:第一个参数是本层神经元个数,然后是初始化方式和激活函数,初始化方法有0到0.05的连续型均匀分布(uniform
#Keras的默认方法也是这个,也可以用高斯分布进行初始化normal,初始化实际就是该层连接上权重与偏置的初始化
model.add(Dense(num_pixels,input_dim=num_pixels,kernel_initializer='normal',activation='relu'))
#softmax是一种用到该层所有神经元的激活函数
model.add(Dense(num,kernel_initializer='normal',activation='softmax'))
#categorical_crossentropy适用于多分类问题,并使用softmax作为输出层的激活函数的情况
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
return model
#训练模型
model = baseline()
"""
batch_size
整数
每次梯度更新的样本数。
未指定,默认为32
epochs
整数
训练模型迭代次数
verbose
日志展示,整数
0:为不在标准输出流输出日志信息
1:显示进度条
2:每个epoch输出一行记录
对于一个有 2000 个训练样本的数据集,将 2000 个样本分成大小为 500 的 batch,那么完成一个 epoch 需要 4 个 iteration
"""
model.fit(X_train,y_train,validation_data=(X_test,y_test),epochs=10,batch_size=200,verbose=2)
#模型概括打印
model.summary()
#model.evaluate()返回的是 损失值和你选定的指标值(例如,精度accuracy)
"""
verbose:控制日志显示的方式
verbose = 0 不在标准输出流输出日志信息
verbose = 1 输出进度条记录
"""
scores = model.evaluate(X_test,y_test,verbose=0)
print(scores)
#模型保存
model_dir="./Dense.h5"
model.save(model_dir)
|
CNN训练
"""
模型构建与训练
Sequential 模型结构: 层(layers)的线性堆栈,它是一个简单的线性结构,没有多余分支,是多个网络层的堆叠
多少个滤波器就输出多少个特征图,即卷积核(滤波器)的深度
3通道RGB图片,一个滤波器有3个通道的小卷积核,但还是只算1个滤波器
"""
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
#Flatten层用来将输入“压平”,即把多维的输入一维化,
#常用在从卷积层到全连接层的过渡
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
#模拟原始灰度数据读入
img_size=28
num=10
mnist=input_data.read_data_sets("./data",one_hot=True)
X_train,y_train,X_test,y_test=mnist.train.images,mnist.train.labels,mnist.test.images,mnist.test.labels
X_train=X_train.reshape(-1,img_size,img_size)
X_test=X_test.reshape(-1,img_size,img_size)
X_train=X_train*255
X_test=X_test*255
y_train=y_train.reshape(-1,num)
y_test=y_test.reshape(-1,num)
print(X_train.shape) #(55000, 28, 28)
print(y_train.shape) #(55000, 10)
#此处卷积输入的形状要与模型中的input_shape匹配
X_train = X_train.reshape(X_train.shape[0],28,28,1).astype('float32')
X_test = X_test.reshape(X_test.shape[0],28,28,1).astype('float32')
print(X_train.shape)#(55000,28,28,1)
#归一化
X_train=X_train/255
X_test=X_test/255
# one hot编码,这里编好了,省略
#y_train = np_utils.to_categorical(y_train)
#y_test = np_utils.to_categorical(y_test)
#搭建CNN网络
def CNN():
"""
第一层是卷积层。该层有32个feature map,作为模型的输入层,接受[pixels][width][height]大小的输入数据。feature map的大小是1*5*5,其输出接一个‘relu'激活函数
下一层是pooling层,使用了MaxPooling,大小为2*2
Flatten压缩一维后作为全连接层的输入层
接下来是全连接层,有128个神经元,激活函数采用‘relu'
最后一层是输出层,有10个神经元,每个神经元对应一个类别,输出值表示样本属于该类别的概率大小
"""
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(img_size,img_size,1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num, activation='softmax'))
#编译
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
#模型训练
model=CNN()
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5, batch_size=200, verbose=1)
model.summary()
scores = model.evaluate(X_test,y_test,verbose=1)
print(scores)
#模型保存
model_dir="./CNN.h5"
model.save(model_dir)
|
|














