一、项目需求 爬取排行榜小说的作者,书名,分类以及完结或连载 二、项目分析 目标url: https://www.qidian.com/rank/hotsales?style=1page=1 通过控制台搜索发现相应信息均存在于html静态网页中,所以此次爬虫难度较低。 通过控制台观察发现,需要的内容都
|
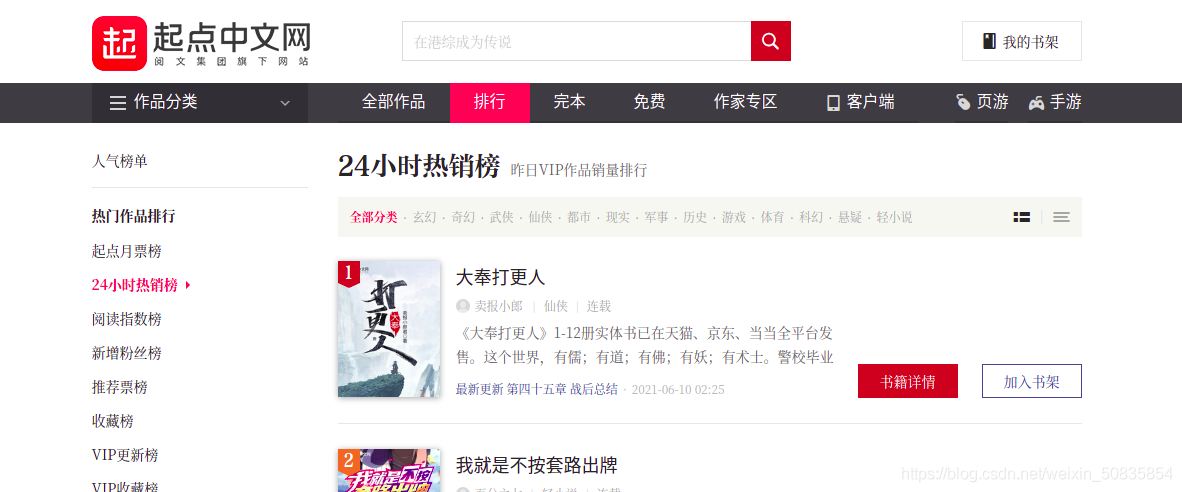
一、项目需求
爬取排行榜小说的作者,书名,分类以及完结或连载 目标url:“”
通过控制台搜索发现相应信息均存在于html静态网页中,所以此次爬虫难度较低。
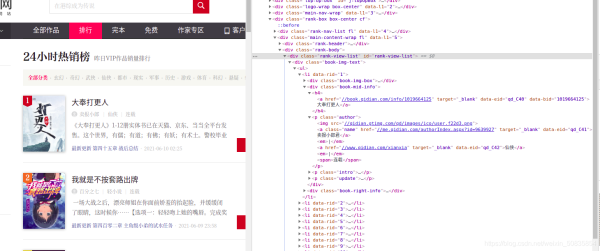
通过控制台观察发现,需要的内容都在一个个li列表中,每一个列表代表一本书的内容。
在li中找到所需的内容
找到第两页的url 创建项目太简单,不说了 1.编写item(数据存储)
2.编写spider(数据抓取(核心代码))
3.start.py(代替命令行) 在爬虫项目文件夹下创建start.py。
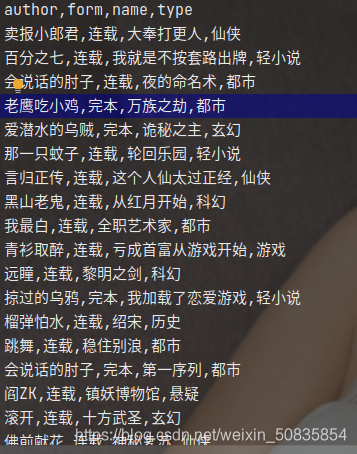
出现类似的过程代表爬取成功。
hot.csv
|







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27