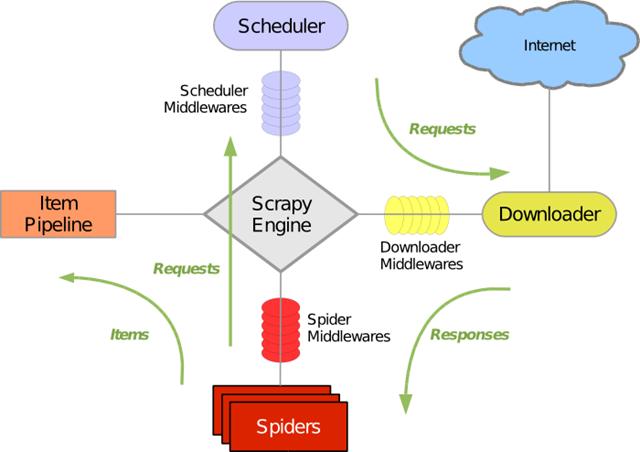
Scrapy框架是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,是提取结构性数据而编写的应用框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,我们只需要少量的代码就能够快速抓取数据。 其框架如下图所示: Scrapy Engine是整个框架的核
|
Scrapy框架是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,是提取结构性数据而编写的应用框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,我们只需要少量的代码就能够快速抓取数据。 其框架如下图所示:
Scrapy Engine是整个框架的核心,而涉及到我们编写代码的模块一般只有Item Pipeline模块和Spiders模块。 首先我们通过以下代码来创建Scrapy项目,执行代码如下图所示:
运行结果如下图所示:
通过上图可知,我们在C盘创建了一个新的Scrapy项目,项目名为Fiction,而且还提示我们可以通过以下命令创建第一个Spider爬虫,命令如下所示:
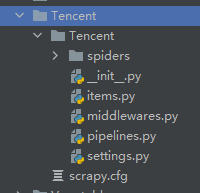
其中example是我们爬虫名,example.com是爬虫爬取的范围,也就是网站的域名。 Fiction文件夹内容如下图所示:
在上面的步骤我们成功创建了一个Scrapy项目,而且知道如何创建Spider爬虫,接下来我们创建名为fiction的Spider爬虫,其域名为www.17k.com,代码如下所示:
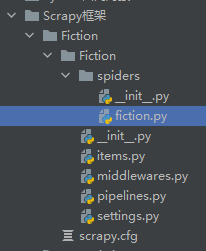
运行后,spiders文件夹中多了我们刚才创建fiction.py,这个就是我们创建的Spider爬虫。 如下图所示:
看到这么多py文件是不是慌了,其实不用慌,一般情况我们主要在刚创建的spider爬虫文件、items.py和pipelines.py进行编写代码,其中:
当数据需要保存在MongoDB数据库时,则编写以下代码即可:
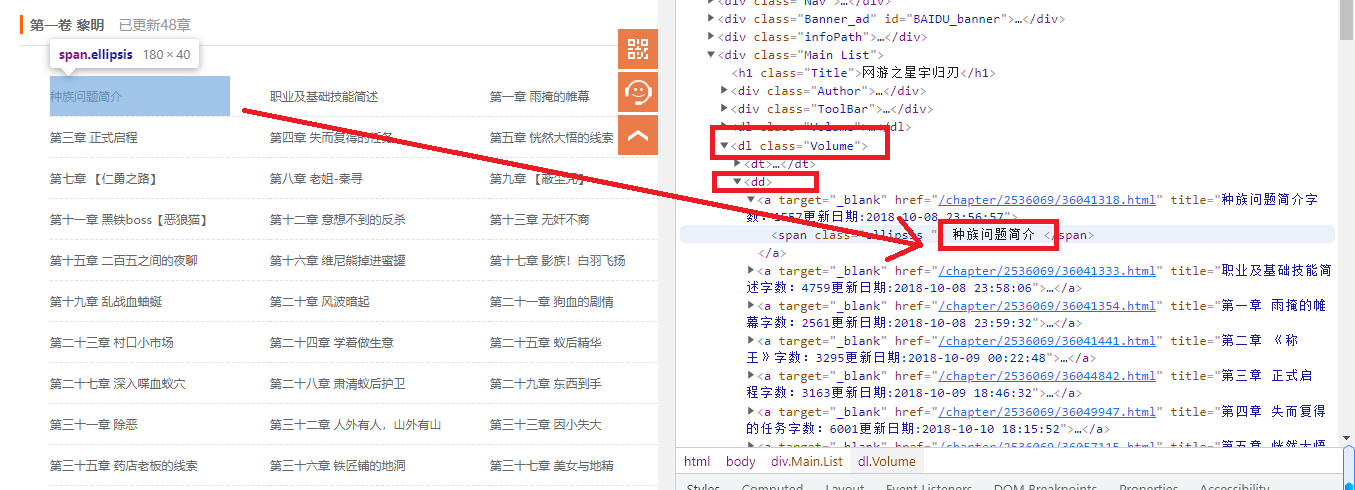
Spider爬虫提取数据 在提取数据前,首先我们进入要爬取小说网站并打开开发者工具,如下图所示:
我们通过上图可以发现,<dl class="Volume">存放着我们所有小说章节名,点击该章节就可以跳转到对应的章节页面,所以可以使用Xpath来通过这个div作为我们的xpath爬取范围,通过for循环来遍历获取每个章节的名和URL链接。 跳转章节内容页面后,打开开发者工具,如下图所示:
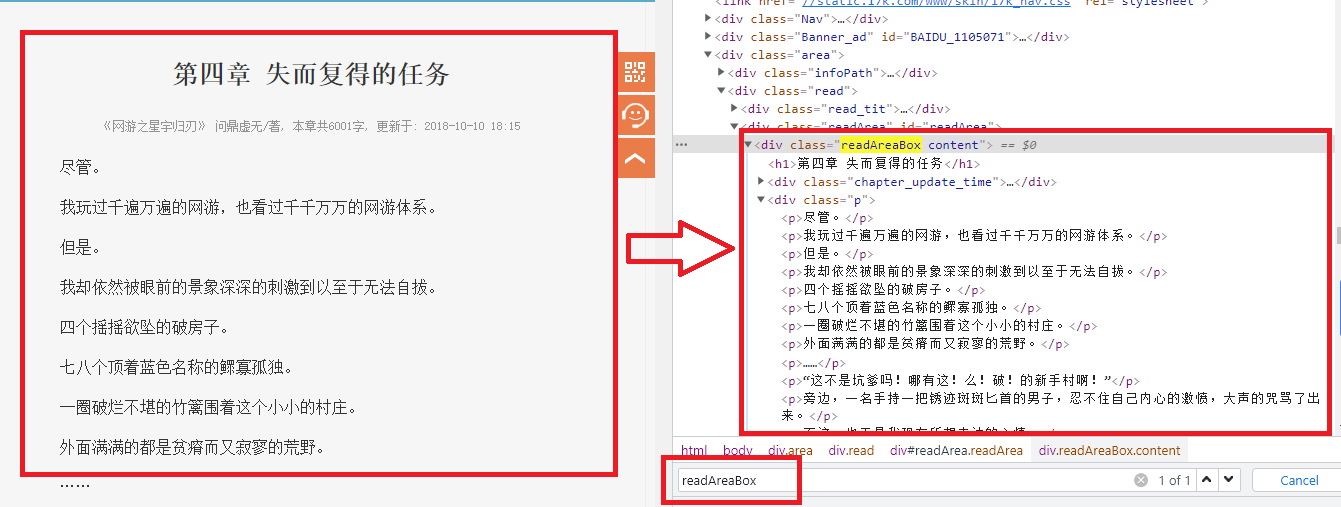
通过上图可以发现,小说内容存储在<div class="readAreaBox">里面,我们可以通过for循环来遍历该dl中的<div class="p">获取到章节的全部内容,当然也是通过使用Xpath来获取。 细心的小伙伴就发现了,我们所需要提前的字段有章节名、章节URL链接和章节内容,其中章节名和章节内容是需要进行数据保存的,所以可以先在items.py文件中定义好字段名,具体代码如下所示:
定义字段很简单,字段名=scrapy.Field()即可。 对了,在items.py定义好字段有个最好的好处是当我们在获取到数据的时候,使用不同的item来存放不同的数据,在把数据交给pipeline的时候,可以通过isinstance(item,FictionItem)来判断数据属于哪个item,进行不同的数据(item)处理。 定义好字段后,这是我们通过在pipeline.py文件中编写代码,对不同的item数据进行区分,具体代码如下:
当然,在我们爬取的项目中,只需要一个class类,在上面的代码只是为了展示如何判断区分数据属于哪个item。 fiction.py文件也就是我们创建的spider爬虫,打开fiction.py文件,其代码内容如下所示:
其中:
大致了解该文件内容的各个部分后,我们开始提取首页的章节名和章节URL链接,具体代码如下所示:
首先导入FictionItem,再我们把start_urls链接修改为待会要爬的URL链接,在parse()方法中,使用xpath获取章节名和章节URL链接,通过for循环调用FictionItem(),再把章节名存放在item里面。 通过生成器yield 返回调用scrapy.Request()方法,其中:
在上一步中我们指定了parse_detail函数作为解析处理,接下来将编写parse_detail函数来获取章节内容,具体代码如下所示:
首先我们定义了一个空变量string,在通过response.meta[]来接收item数据,其参数为上一步中的meta={'item': item}的item,接下来获取章节内容,最后将章节内容存储在item['text']中,并通过生成器yield返回数据给引擎。 章节名和章节内容已经全部获取下来了,接下来我们把获取下来的数据保存为txt文件,具体代码如下所示:
首先我们导入FictionItem、time,在open_spider()和close_spider()方法编写代码调用time.time()来获取爬取的开始时间和结束时间,再在process_item()方法中,把引擎返回的item['name']和item['text']分别存放在title和content中,并通过open打开txt文件,调用write()把章节内容写入在txt文件中。 在启动爬虫前,我们先要在settings.py文件中启动引擎,启动方式很简单,只要找到下图中的代码,并取消代码的注释即可:
有人可能问:那User-Agent在哪里设置?我们可以在settings.py文件中,设置User-Agent,具体代码如下:
好了,所有代码已经编写完毕了,接下来将启动爬虫了,执行代码如下:
启动爬虫后,发现我们控制台里面多了很多log日志数据的输出,这时可以通过在settings.py添加以下代码,就可以屏蔽这些log日志:
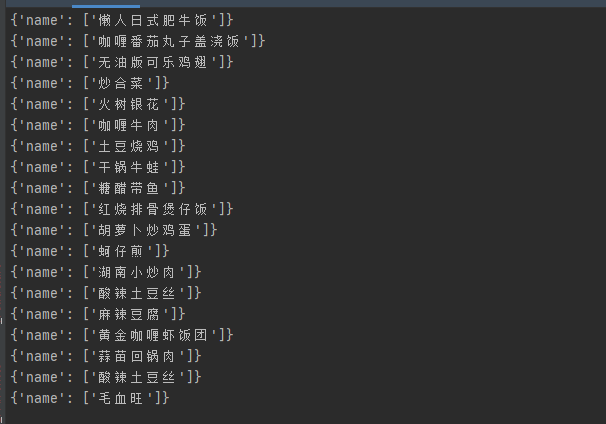
结果展示
好了,scrapy框架爬取小说就讲到这里了,感觉大家的观看!!! |







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27