1.字典文本特征提取 DictVectorizer() 1.1 one-hot编码 创建一个字典,观察如下数据形式的变化: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import pandas as pd from sklearn.feature_extraction import DictVectorizer data = [{c
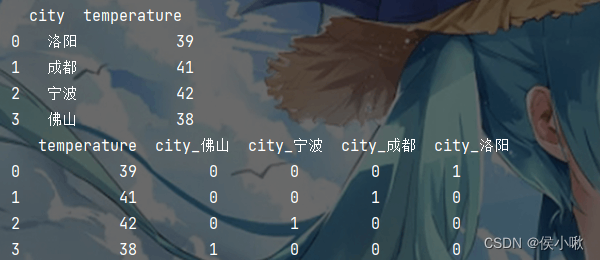
1.字典文本特征提取 DictVectorizer()1.1 one-hot编码创建一个字典,观察如下数据形式的变化:
输出如下:
1.2 字典数据转sparse矩阵使用DictVectorizer()创建字典特征提取模型
使用sparse矩阵没有显示0数据,节约了内存,更为简洁,这一点比ndarray矩阵更好。 2.英文文本特征提取文本特征提取使用的是CountVectorizer文本特征提取模型,这里准备了一段英文文本(I have a dream)。统计词频并得到sparse矩阵,代码如下所示: CountVectorizer()没有sparse参数,默认采用sparse矩阵格式。且可以通过stop_words指定停用词。
输出结果如下图所示:
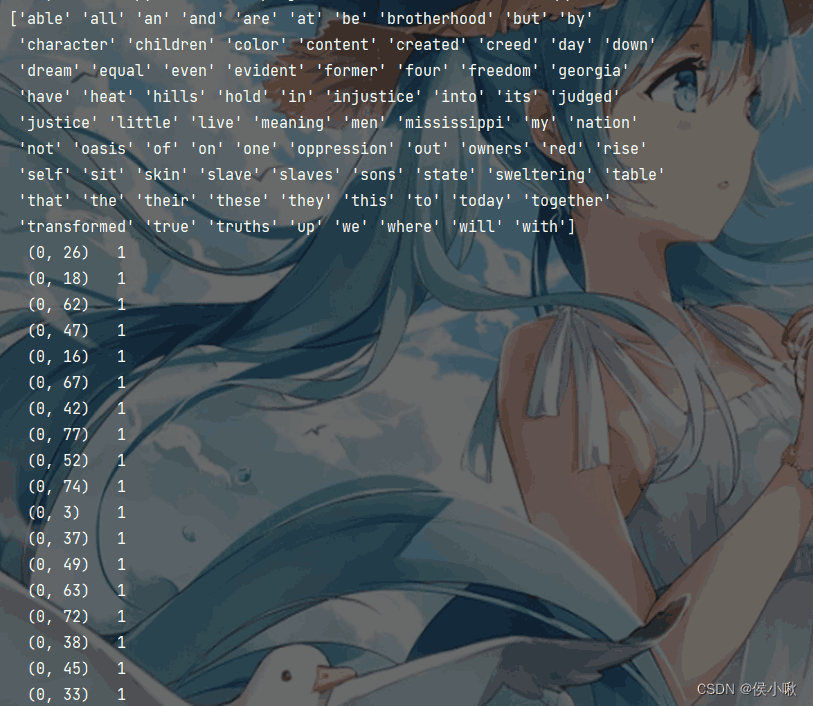
3.中文文本特征提取准备一段中文文本(data.txt),以水浒传中风雪山神庙情节为例:
对中文提取文本特征,需要安装并使用到jieba库。使用该库将文本处理成为空格连接词语的格式,再使用CountVectorizer文本特征提取模型进行提取即可。 代码示例如下:
程序执行效果如下:
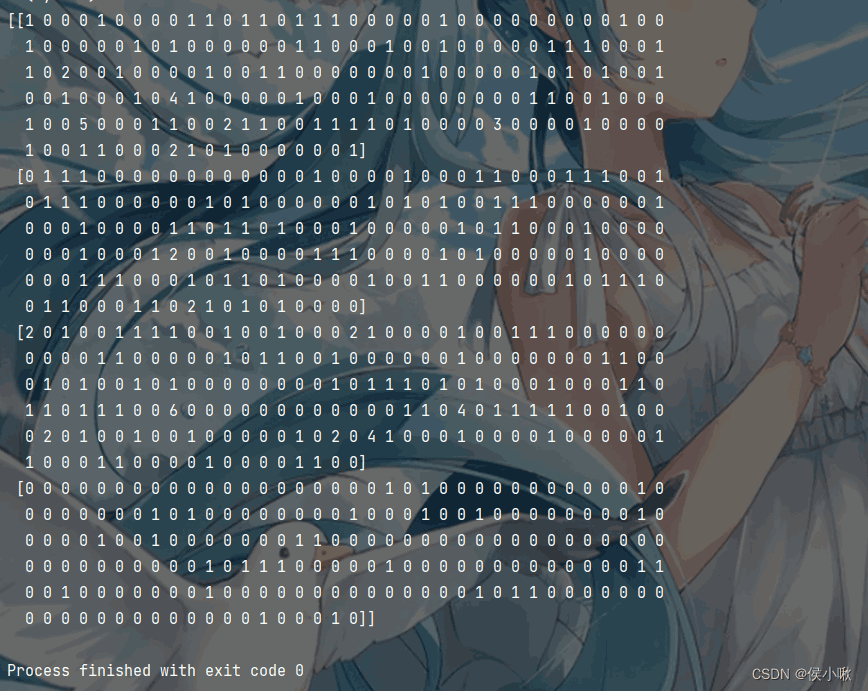
转换得到的ndarray数组形式(如果需要)如图所示:
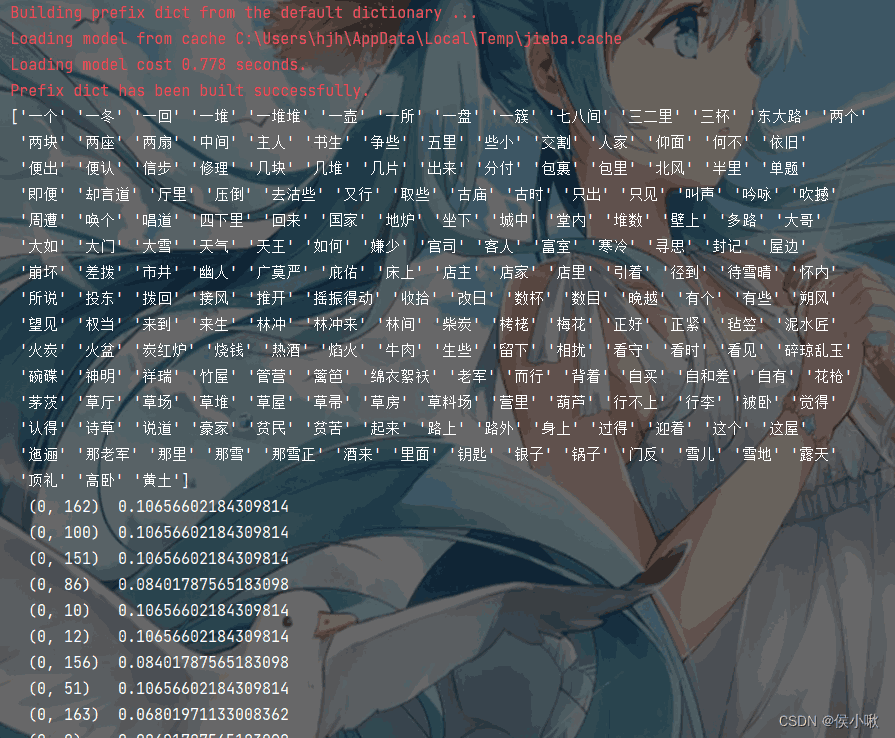
4. TF-IDF 文本特征提取 TfidfVectorizer()TF-IDF文本提取器可以用来评估一字词对于一个文件集或者一个语料库中的其中一份文件的重要程度。 代码展示如下:
程序执行结果如下:
|







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27