|
import re
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT, WD_TABLE_ALIGNMENT
from openpyxl import load_workbook
from docx import Document
def info_update(doc, old_info, new_info):
"""
文档内容替换
:param doc: Word模板文档
:param old_info: 源文本
:param new_info: 新文本
:return:
"""
# 遍历Word文档中的所有段落
for para in doc.paragraphs:
# 遍历每个段落中的run对象
for run in para.runs:
# 替换run对象的文本内容
# run.text = run.text.replace(r'《'+old_info+'》', new_info)
run.text = run.text.replace(old_info, new_info)
run.text = re.sub(r'[《》]', '', run.text)
# 遍历Word文档中的所有表格
for table in doc.tables:
# 遍历表格中的所有行
for row in table.rows:
# 遍历行中的所有单元格
for cell in row.cells:
# 替换单元格内容
cell.text = cell.text.replace('《' + old_info + '》', new_info)
# 设置表格中的内容居中显示
# 计算表格的rows和cols的长度
rows = len(table.rows)
cols = len(table.columns)
# 循环将每一行,每一列都设置为居中
for r in range(rows):
for c in range(cols):
table.cell(r, c).vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER # 垂直居中
table.cell(r, c).paragraphs[0].paragraph_format.alignment = WD_TABLE_ALIGNMENT.CENTER # 水平居中
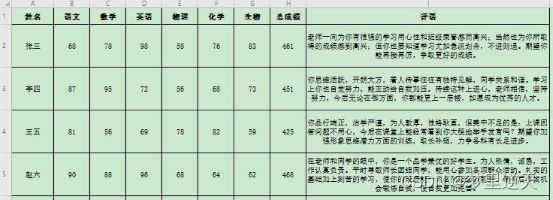
wb = load_workbook('学生成绩表.xlsx') # 打开工作簿
ws = wb.active # 激活工作簿中的工作表
# 遍历工作表的行,从第2行开始
for row in range(2, ws.max_row + 1):
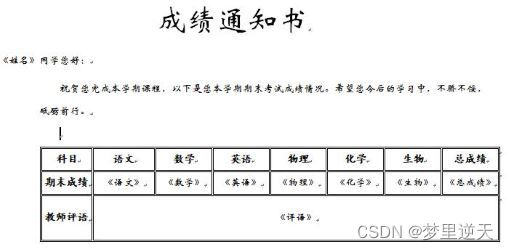
doc = Document('成绩通知书.docx') # 创建文档对象
# 遍历工作表的列
for col in range(1, ws.max_column + 1):
# 读取当前列的第一行,即列标题,单元格的值转换成字符串
old_info = str(ws.cell(row=1, column=col).value)
# 读取当前列的数据,单元格的值需要转换成字符串
new_info = str(ws.cell(row=row, column=col).value)
# 进行内容替换
info_update(doc, old_info, new_info)
student_name = str(ws.cell(row=row, column=1).value)
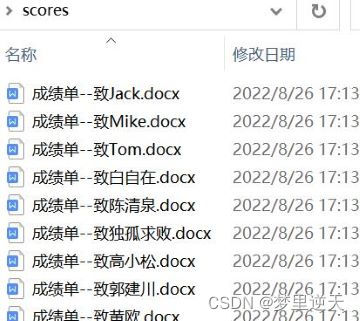
doc.save(f'scores\\成绩单--致{student_name}.docx')
|