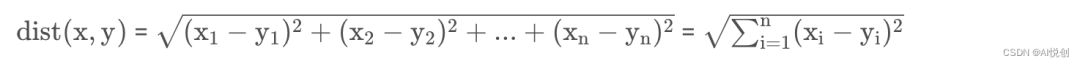一、介绍 k-近邻算法(K-Nearest Neighbour algorithm),又称 KNN 算法,是数据挖掘技术中原理最简单的算法。 工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在
一、介绍k-近邻算法(K-Nearest Neighbour algorithm),又称 KNN 算法,是数据挖掘技术中原理最简单的算法。 工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻近的 k 个实例,如果这 k 个实例的多数属于某个类别,那么新数据就属于这个类别。简单理解为:由那些离 X 最近的 k 个点来投票决定 X 归为哪一类。 二、k-近邻算法的步骤(1)计算已知类别数据集中的点与当前点之间的距离; (2)按照距离递增次序排序; (3)选取与当前点距离最小的 k 个点; (4)确定前k个点所在类别的出现频率; (5)返回前 k 个点出现频率最高的类别作为当前点的预测类别。 三、Python 实现判断一个电影是爱情片还是动作片。
欧氏距离
构建数据集
计算已知类别数据集中的点与当前点之间的距离
将距离升序排列,然后选取距离最小的 k 个点「容易拟合·以后专栏再论」
确定前 k 个点的类别的出现概率
选择频率最高的类别作为当前点的预测类别
四、约会网站配对效果判定
五、手写数字识别
六、算法优缺点优点(1)简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归; (2)可用于数值型数据和离散型数据; (3)无数据输入假定; (4)适合对稀有事件进行分类。 缺点(1)计算复杂性高;空间复杂性高; (2)计算量大,所以一般数值很大的适合不用这个,但是单个样本又不能太少,否则容易发生误分; (3)样本不平衡问题(即有些类别的样本数量很多,而其他样本的数量很少); (4)可理解性比较差,无法给出数据的内在含义 |







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27