说到机器学习,大家首先想到的可能就是Python和算法了,其实光有Python和算法是不够的,数据才是进行机器学习的前提。 大多数的数据都会存储在文件中,要想通过Python调用算法对数据
|
说到机器学习,大家首先想到的可能就是Python和算法了,其实光有Python和算法是不够的,数据才是进行机器学习的前提。 大多数的数据都会存储在文件中,要想通过Python调用算法对数据进行相关学习,首先就要将数据读入程序中,本文介绍两种加载数据的方式,在之后的算法介绍中,将频繁使用这两种方式将数据加载到程序。 下面我们将以Logistic Regression模型加载数据为例,分别对两种不同的加载数据的方式进行介绍。 一、利用open()函数进行加载
二、利用Pandas库中的read_csv()方法进行加载
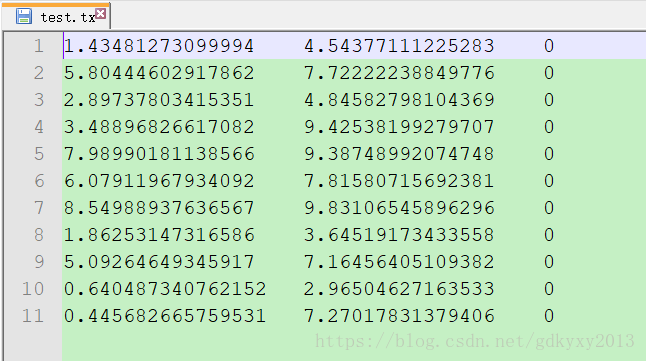
三、示例我们可以使用上述的两种方法加载部分数据进行测试,数据内容如下:
数据分为三列,前两列是特征,最后一列是标签。 加载数据代码如下:
测试结果:
从测试结果来看可知两种加载数据的方法得到的数据结果是一样的,故两种方法均适用于加载数据。 注意: 此处是以Logistic Regression模型加载数据为例,数据与数据本身或许会有差异,但加载数据的方式都是大同小异的,要灵活变通。 |







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27