自从学了Python后就逼迫用Python来处理Excel,所有操作用Python实现。目的是巩固Python,与增强数据处理能力。 这也是我写这篇文章的初衷。废话不说了,直接进入正题。 数据是网上找到的
|
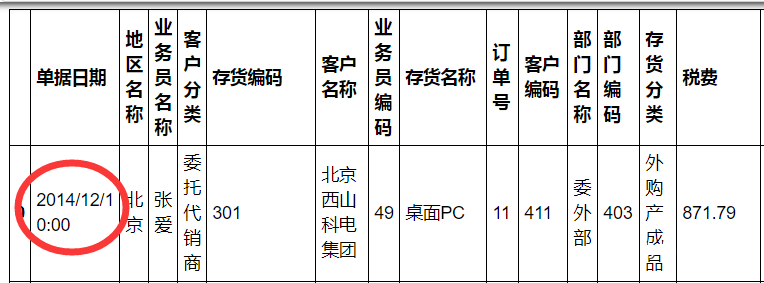
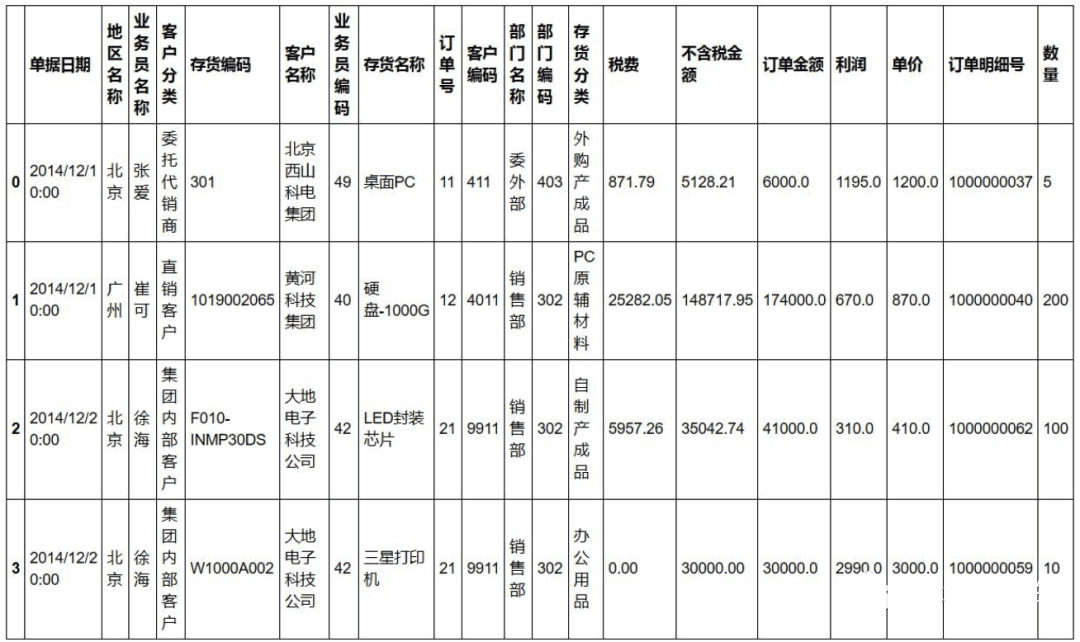
自从学了Python后就逼迫用Python来处理Excel,所有操作用Python实现。目的是巩固Python,与增强数据处理能力。 这也是我写这篇文章的初衷。废话不说了,直接进入正题。 数据是网上找到的销售数据,长这样:
一、关联公式:Vlookupvlookup是excel几乎最常用的公式,一般用于两个表的关联查询等。所以我先把这张表分为两个表。
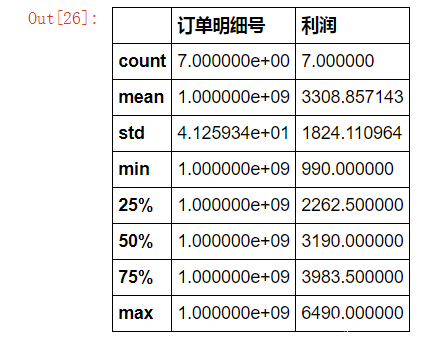
需求:想知道df1的每一个订单对应的利润是多少。 利润一列存在于df2的表格中,所以想知道df1的每一个订单对应的利润是多少。用excel的话首先确认订单明细号是唯一值,然后在df1新增一列写:=vlookup(a2,df2!a:h,6,0) ,然后往下拉就ok了。(剩下13个我就不写excel啦) 那用python是如何实现的呢?
二、数据透视表需求:想知道每个地区的业务员分别赚取的利润总和与利润平均数。
三、对比两列差异因为这表每列数据维度都不一样,比较起来没啥意义,所以我先做了个订单明细号的差异再进行比较。 需求:比较订单明细号与订单明细号2的差异并显示出来。
四、去除重复值需求:去除业务员编码的重复值
五、缺失值处理先查看销售数据哪几列有缺失值。
需求:用0填充缺失值或则删除有客户编码缺失值的行。 实际上缺失值处理的办法是很复杂的,这里只介绍简单的处理方法,若是数值变量,最常用平均数或中位数或众数处理,比较复杂的可以用随机森林模型根据其他维度去预测结果填充。若是分类变量,根据业务逻辑去填充准确性比较高。 比如这里的需求填充客户名称缺失值: 就可以根据存货分类出现频率最大的存货所对应的客户名称去填充。 这里我们用简单的处理办法:用0填充缺失值或则删除有客户编码缺失值的行。
六、多条件筛选需求:想知道业务员张爱,在北京区域卖的商品订单金额大于6000的信息。
七、 模糊筛选数据需求:筛选存货名称含有"三星"或则含有"索尼"的信息。
八、分类汇总需求:北京区域各业务员的利润总额。
九、条件计算需求:存货名称含“三星字眼”并且税费高于1000的订单有几个?这些订单的利润总和和平均利润是多少?(或者最小值,最大值,四分位数,标注差)
十、删除数据间的空格需求:删除存货名称两边的空格。
十一、数据分列
需求:将日期与时间分列。
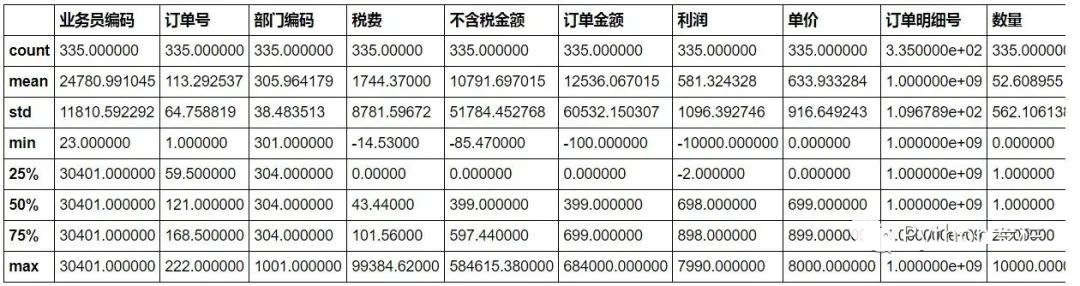
十二、异常值替换首先用describe()函数简单查看一下数据有无异常值。
需求:用0代替异常值。
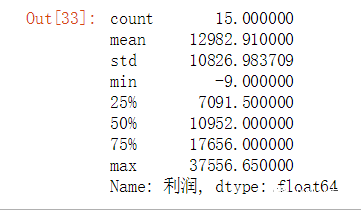
十三、分组需求:根据利润数据分布把地区分组为:“较差”,“中等”,“较好”,“非常好” 首先,当然是查看利润的数据分布呀,这里我们采用四分位数去判断。
根据四分位数把地区总利润为[-9,7091]区间的分组为“较差”,(7091,10952]区间的分组为"中等" (10952,17656]分组为较好,(17656,37556]分组为非常好。
十四、根据业务逻辑定义标签需求:销售利润率(即利润/订单金额)大于30%的商品信息并标记它为优质商品,小于5%为一般商品。
其实excel常用的操作还有很多,我就列举了14个自己比较常用的,若还想实现哪些操作可以评论一起交流讨论,另外我自身也知道我写python不够精简,惯性使用loc。(其实query会比较精简)。若大家对这几个操作有更好的写法请务必评论告知我,感谢! 最后想说说,我觉得最好不要拿excel和python做对比,去研究哪个好用,其实都是工具,excel作为最为广泛的数据处理工具,垄断这么多年必定在数据处理方便也是相当优秀的,有些操作确实python会比较简单,但也有不少excel操作起来比python简单的。 比如一个很简单的操作:对各列求和并在最下一行显示出来,excel就是对一列总一个sum()函数,然后往左一拉就解决,而python则要定义一个函数(因为python要判断格式,若非数值型数据直接报错。) 总结一下就是:无论用哪个工具,能解决问题就是好数据分析师! |




2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27