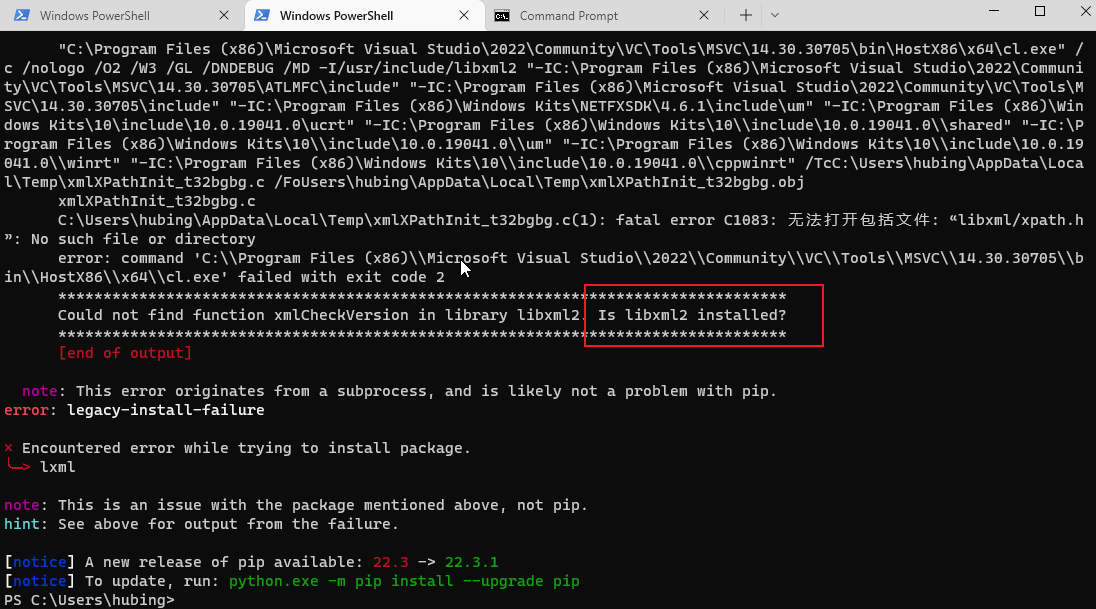
python 3.10支持match语句,3,10以下不支持。
match语句接受一个表达式,并将其值与作为一个或多个case块给出的连续模式进行比较。这表面上类似于C、Java或JavaScript(以及许多其他语言)中的switch语句,但更类似于Rust或Haskell等语言中的模式匹配。只有第一个匹配的模式才会被执行,它还可以将值中的组件(序列元素或对象属性)提取到变量中。
最简单的形式是将一个目标值与一个或多个字面值进行比较:
|
1
2
3
4
5
6
7
8
9
10
|
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
|
注意最后一个代码块:“变量名” _ 被作为 通配符 并必定会匹配成功。 如果没有 case 语句匹配成功,则不会执行任何分支。
使用 | (“ or ”)在一个模式中可以组合多个字面值:
|
1
2
|
case 401 | 403 | 404:
return "Not allowed"
|
模式的形式类似解包赋值,并可被用于绑定变量:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# point is an (x, y) tuple
match point:
case (0, 0):
print("Origin")
case (0, y):
print(f"Y={y}")
case (x, 0):
print(f"X={x}")
case (x, y):
print(f"X={x}, Y={y}")
case _:
raise ValueError("Not a point")
|
请仔细研究此代码! 第一个模式有两个字面值,可以看作是上面所示字面值模式的扩展。但接下来的两个模式结合了一个字面值和一个变量,而变量 绑定 了一个来自目标的值(point)。第四个模式捕获了两个值,这使得它在概念上类似于解包赋值 (x, y) = point。
如果使用类实现数据结构,可在类名后加一个类似于构造器的参数列表,这样做可以把属性放到变量里:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Point:
x: int
y: int
def where_is(point):
match point:
case Point(x=0, y=0):
print("Origin")
case Point(x=0, y=y):
print(f"Y={y}")
case Point(x=x, y=0):
print(f"X={x}")
case Point():
print("Somewhere else")
case _:
print("Not a point")
|
可在 dataclass 等支持属性排序的内置类中使用位置参数。还可在类中设置 __match_args__ 特殊属性为模式的属性定义指定位置。如果它被设为 ("x", "y"),则以下模式均为等价的,并且都把 y 属性绑定到 var 变量:
|
1
2
3
4
|
Point(1, var)
Point(1, y=var)
Point(x=1, y=var)
Point(y=var, x=1)
|
读取模式的推荐方式是将它们看做是你会在赋值操作左侧放置的内容的扩展形式,以便理解各个变量将会被设置的值。 只有单独的名称(例如上面的 var)会被 match 语句所赋值。 带点号的名称 (例如 foo.bar)、属性名称(例如上面的 x= 和 y=)或类名称(通过其后的 "(...)" 来识别,例如上面的 Point)都绝不会被赋值。
模式可以任意地嵌套。例如,如果有一个由点组成的短列表,则可使用如下方式进行匹配:
|
1
2
3
4
5
6
7
8
9
10
11
|
match points:
case []:
print("No points")
case [Point(0, 0)]:
print("The origin")
case [Point(x, y)]:
print(f"Single point {x}, {y}")
case [Point(0, y1), Point(0, y2)]:
print(f"Two on the Y axis at {y1}, {y2}")
case _:
print("Something else")
|
为模式添加成为守护项的 if 子句。如果守护项的值为假,则 match 继续匹配下一个 case 语句块。注意,值的捕获发生在守护项被求值之前:
|
1
2
3
4
5
|
match point:
case Point(x, y) if x == y:
print(f"Y=X at {x}")
case Point(x, y):
print(f"Not on the diagonal")
|
match 语句的其他特性:
- 与解包赋值类似,元组和列表模式具有完全相同的含义,并且实际上能匹配任意序列。 但它们不能匹配迭代器或字符串。
- 序列模式支持扩展解包操作:[x, y, *rest] 和 (x, y, *rest) 的作用类似于解包赋值。 在 * 之后的名称也可以为 _,因此,(x, y, *_) 可以匹配包含至少两个条目的序列,而不必绑定其余的条目。
- 映射模式:{"bandwidth": b, "latency": l} 从字典中捕获 "bandwidth" 和 "latency" 的值。与序列模式不同,额外的键会被忽略。**rest 等解包操作也支持。但 **_ 是冗余的,不允许使用。
使用 as 关键字可以捕获子模式:
|
1
|
case (Point(x1, y1), Point(x2, y2) as p2): ...
|
将把输入的第二个元素捕获为 p2 (只要输入是包含两个点的序列)
大多数字面值是按相等性比较的,但是单例对象 True, False 和 None 则是按标识号比较的。
模式可以使用命名常量。 这些命名常量必须为带点号的名称以防止它们被解读为捕获变量:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from enum import Enum
class Color(Enum):
RED = 'red'
GREEN = 'green'
BLUE = 'blue'
color = Color(input("Enter your choice of 'red', 'blue' or 'green': "))
match color:
case Color.RED:
print("I see red!")
case Color.GREEN:
print("Grass is green")
case Color.BLUE:
print("I'm feeling the blues :(")
|
|