
torch.to(device)是否赋值的坑 在我们用GPU跑程序时,需要在程序中把变量和模型放到GPU里面。 有一些坑需要注意,本文用RNN模型实例 首先,定义device 1 device = torch.device(cuda:0 if torch.cuda.is_availabl
torch.to(device)是否赋值的坑在我们用GPU跑程序时,需要在程序中把变量和模型放到GPU里面。 有一些坑需要注意,本文用RNN模型实例首先,定义device
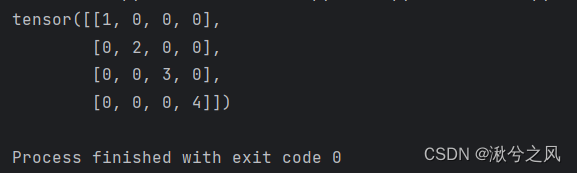
对于变量,需要进行赋值操作才能真正转到GPU上:
对于模型,不需要进行赋值:
对模型进行to(device),还有一种方法,就是在定义模型的时候全部对模型网络参数to(device),这样就可以不需要model.to(device)这句话。
pytorch中model=model.to(device)用法这代表将模型加载到指定设备上。 其中,device=torch.device("cpu")代表的使用cpu,而device=torch.device("cuda")则代表的使用GPU。 当我们指定了设备之后,就需要将模型加载到相应设备中,此时需要使用model=model.to(device),将模型加载到相应的设备中。 将由GPU保存的模型加载到CPU上将torch.load()函数中的map_location参数设置为torch.device('cpu')
将由GPU保存的模型加载到GPU上。确保对输入的tensors调用input = input.to(device)方法。
将由CPU保存的模型加载到GPU上确保对输入的tensors调用input = input.to(device)方法。 map_location是将模型加载到GPU上,model.to(torch.device('cuda'))是将模型参数加载为CUDA的tensor。 最后保证使用.to(torch.device('cuda'))方法将需要使用的参数放入CUDA。
|






2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27


