一、pandas简介 pandas是一个第三方数据分析库,其集成了大量的数据分析工具,可以方便的处理和分析各类数据。这是一个第三方库,使用下面的命令可以安装pandas: 1 pip install pandas 利用pandas处
一、pandas简介pandas是一个第三方数据分析库,其集成了大量的数据分析工具,可以方便的处理和分析各类数据。这是一个第三方库,使用下面的命令可以安装pandas:
利用pandas处理CSV文件主要分为3步:
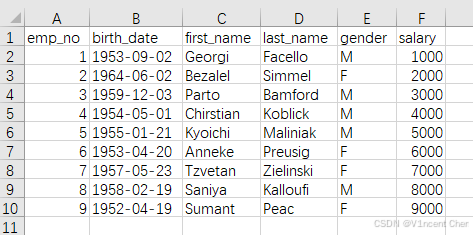
二、用法示例我们先创建一个示例文件,将下面的数据拷贝到文件employees.csv中并保存:
数据对应的excel格式,作为参考:
2.1 读取CSV文件保证employees.csv文件在当前目录下(或提供文件的绝对路径也可以),例如示例文件保存在d:\dir1目录下,先切换到该目录下:
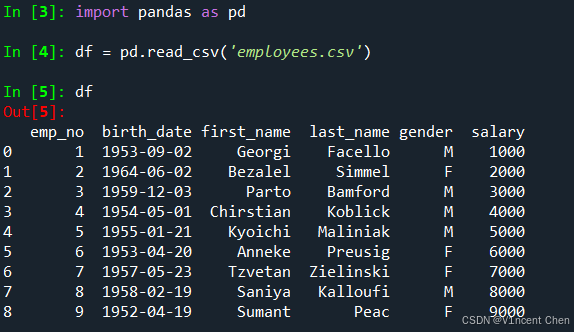
pandas的read_csv函数可以读取CSV文件,并返回一个DataFrame对象,首次使用要先导入pandas模块,使用read_csv()函数读取csv文件,并将返回的DataFrame对象赋给变量名df:
2.1.1 read_csv参数read_csv()在读取过程中有很多自定义设置,上面的示例中只提供了文件名,其他参数都采用了默认值。根据数据格式的不同,可能需要对某些参数进行调整,read_csv函数的常用参数如下:
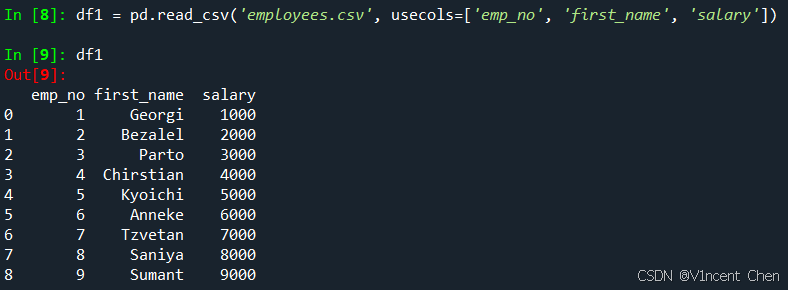
示例:仅选取部分列,只读取emp_no,first_name, salary 这3列,使用参数usecols指定这3列:
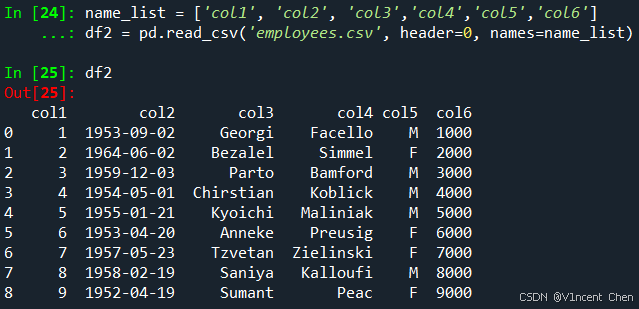
自定义列名:读取数据并使用col1~col6定义列名,由于原数据第一行为列名,使用header=0指定第一行为列名,这样第一行不会被读作数据。然后使用names参数重新指定列名:
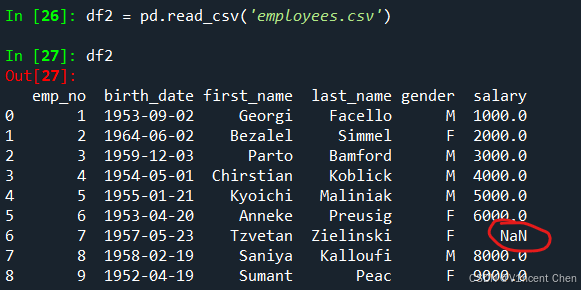
2.1.2 "坏行"的处理很多时候我们得到数据格式并不规范,可能出现有些行数据缺失,有些行数据又多。read_csv函数在遇到数据缺失的列会自动用NaN(在pandas中代表空值)来填充(我们把文件中第七行的salary删除,重新读取后,可以看到会用自动用NaN填充):
但是对于数据列多的行,默认是报错的。在文件第8行后多加一列数据,提示解析错误,期望6列,但是有7列:
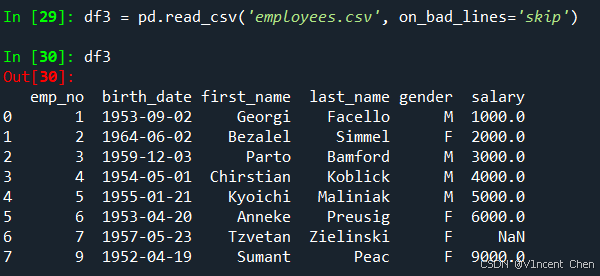
对于这类错误,我们可以用on_bad_lines='skip’来跳过这些行,不影响其他数据的读取,从结果也上可以看到emp_no为8的数据被忽略了:
2.2 引用数据在完成文件的读取后我们就获得了一个DataFrame对象,利用其自带的方法可以快速进行数据预处理,相对于使用Python代码,可以节约大量逻辑编写的时间。 对数据进行处理的第一步就是引用数据,pandas常用的数据引用方法有:
2.2.1 位置索引和标签索引在引用数据前先弄清楚位置索引和标签索引:
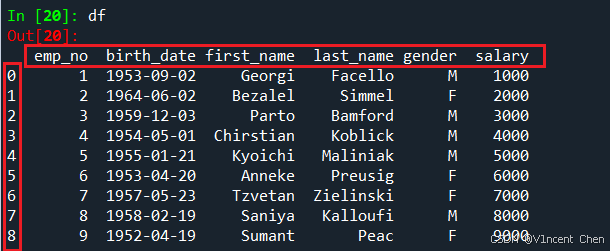
例如下面的df,红框中的都是标签索引: 列标签是emp_no, birth_date ……,索引标签由于未显式指定,所以和位置索引相同,为0,1,2,3,4….,但它不是位置索引。
在标签索引中,可以通过df.index和df.columns属性来分别查看索引标签和列标签:
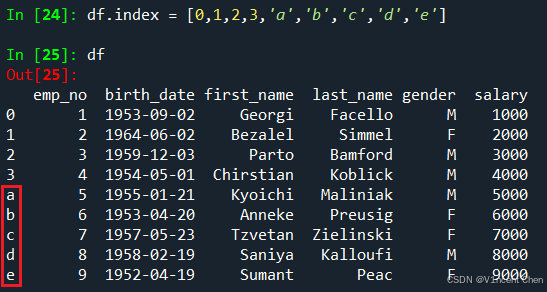
通过给对应的属性赋值,可以改变标签,通过下面的例子可以直观看到,红框中的0,1,2,3…是索引标签,而不是位置标签:
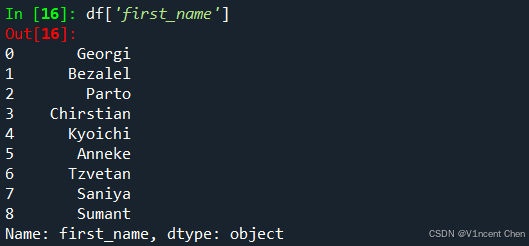
2.2.2 使用[]引用数据使用df[‘列标签’]的格式,通过列标签可以引用数据列,例如选择frist_name列:
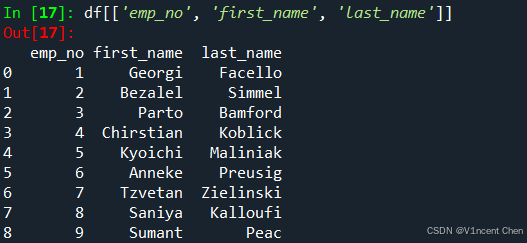
如果要引用多个列,以列表的形式传入多个列,例如选择emp_no, first_name, last_name这3列:
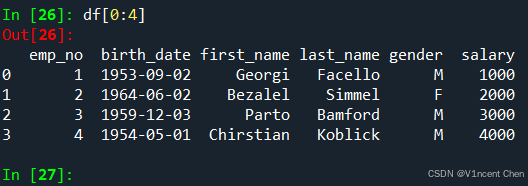
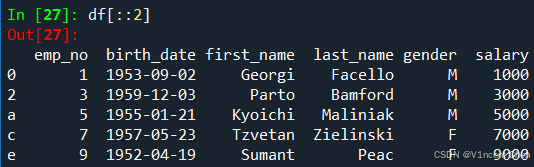
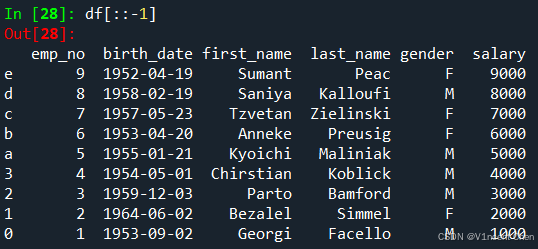
使用df[start:stop:step]的格式,可以通过位置索引引用行,这和标准的Python切片语法相同(这里不详细介绍):
2.2.3 使用.loc属性通过标签引用数据使用[]的引用方式可能有些复杂,它在引用列的时候用的是标签索引,而在引用行的时候是位置索引。 pandas提供了更直观的.loc和.iloc属性:
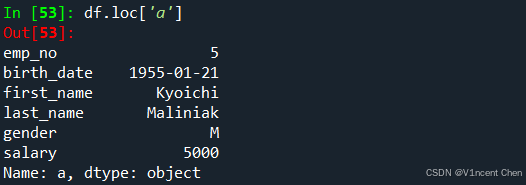
使用df.loc[‘索引标签’, ‘列标签’]可以引用数据。标签之间用逗号分隔,标签内部的分片用冒号分隔,省略则代表全部。注意,.loc属性中的分片是包含结尾的,这和标准的python分片语法不同。 引用a行(返回的是pandas一维数据类型Series):
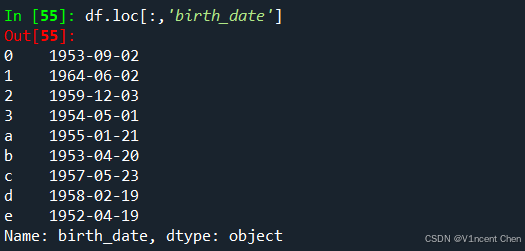
引用birth_date列:
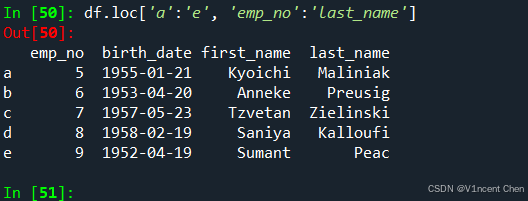
引用a-e行,及emp_no到last_name列,注意e行和last_name列都是包含在分片结果中的:
引用a行,birth_date列的单一元素(没有分片):
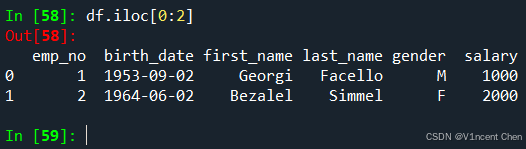
2.2.4 使用.iloc属性通过位置引用数据.iloc的使用方式和.loc很像,只是将索引标签换成了位置标签。语法为df.iloc[‘行位置索引’, ‘列位置索引’],注意.iloc的分片是不包含结尾的(和python相同)。 引用第1,2行:
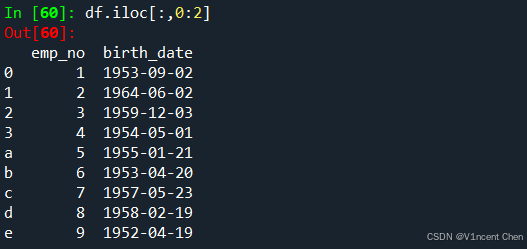
引用第1,2列:
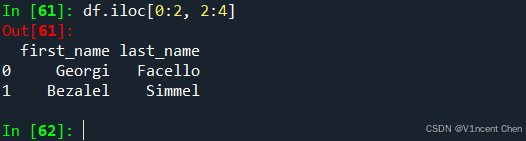
引用1,2行的3,4列数据:
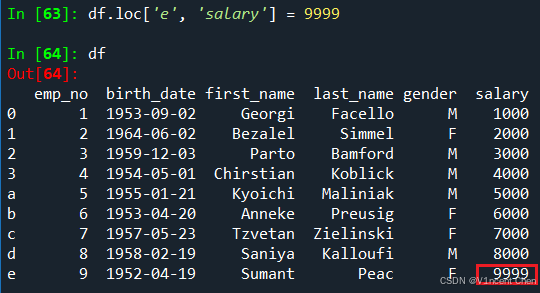
数据引用配合赋值符号’=',即可以修改DataFrame中的值,例如将emp_no为9的salary改为9999
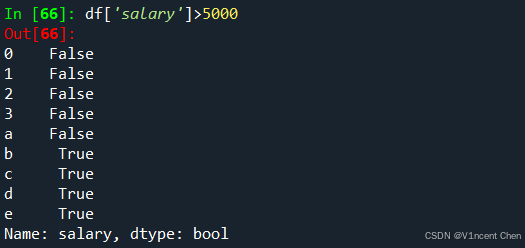
其他的数据引用方式还有通过属性进行引用,但这种方式存在缺陷,不推荐,这里也不进行介绍。重点掌握.loc和.iloc的方法即可。 2.3 数据过滤DataFrame的数据过滤非常方便,例如我要选择salary大于5000的数据,下面表达式即是salary列测试结果,由bool型数据组成:
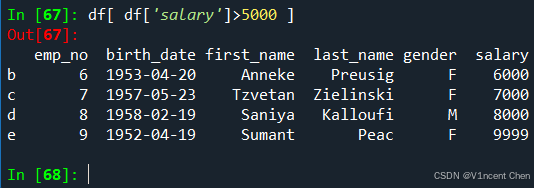
只需要将其再代入df,即可筛选出满足条件的数据:
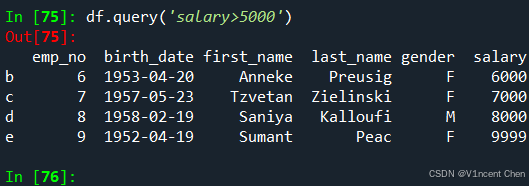
或者使用query方法,基于字符串形式的条件,直接过滤出结果:
2.4 写回csv文件完成数据处理后,使用DataFrame对象自带的to_csv方法来将数据写回文件,主要参数与read_csv类似:
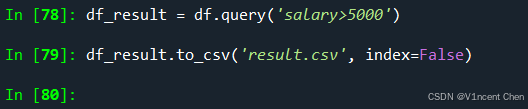
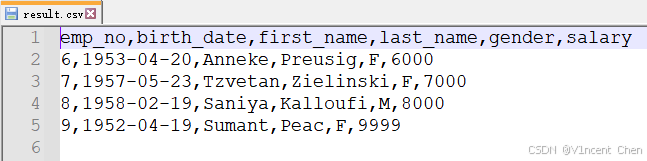
假设要将salary>5000的数据筛选出来后,重新写入一个CSV文件,你可以直接调用DataFrame的to_csv方法:
本文的案例只是展示了最简单及最常用的DataFrame数据处理方法,实际pandas的数据处理功能远远不止这些,有兴趣的同学可以自行深入探索。 |




2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27