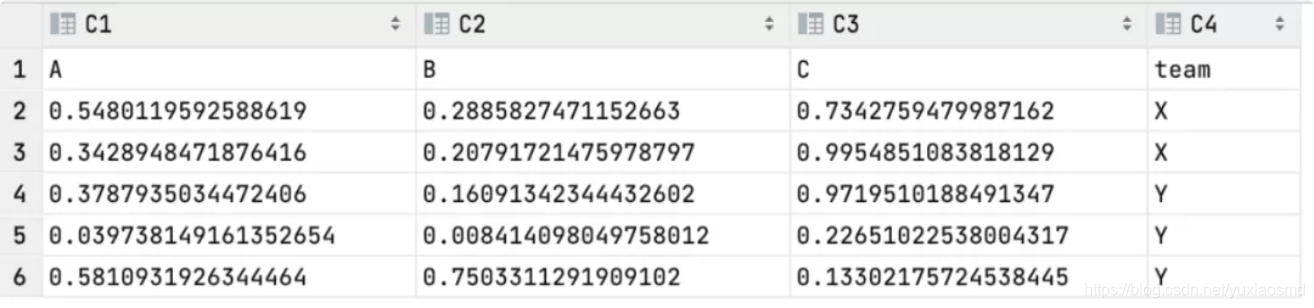
DataFrame.replace()函数用于替换DataFrame中的指定值。该函数允许使用单个值、列表、字典或正则表达式进行替换操作,非常灵活。 二、语法和参数 1 DataFrame.replace(to_replace=None, value=None, inplace=Fals
|
DataFrame.replace()函数用于替换DataFrame中的指定值。该函数允许使用单个值、列表、字典或正则表达式进行替换操作,非常灵活。 二、语法和参数
三、实例3.1 替换单个值
输出:
3.2 使用字典替换值
输出:
3.3 使用列表替换值
输出:
3.4 使用正则表达式替换值
输出:
四、注意事项
|




2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27