
PyTorch池化层详解及作用

在深度学习中,池化层(Pooling Layer)是卷积神经网络(CNN)中的关键组成部分。池化层的主要功能是对特征图进行降维和减少计算量,同时增强模型的鲁棒性。本文将详细介绍池化层的作用、
|
在深度学习中,池化层(Pooling Layer)是卷积神经网络(CNN)中的关键组成部分。池化层的主要功能是对特征图进行降维和减少计算量,同时增强模型的鲁棒性。本文将详细介绍池化层的作用、种类、实现方法,并对比其与卷积层的异同,以及深入探讨全局池化的应用。 1. 池化层的作用池化层的核心作用包括以下几个方面:
2. 池化层的类型池化层主要包括最大池化(Max Pooling)和平均池化(Average Pooling),此外还有全局池化(Global Pooling)。 2.1 最大池化(Max Pooling)最大池化选取池化窗口内的最大值作为输出。这种方法能够保留特征图中最显著的特征,通常用于提取边缘等强特征。
输出结果为:
2.1.1 最大池化的详细计算过程最大池化(Max Pooling)是一种常见的池化操作,用于对输入特征图进行降维和特征提取。其核心思想是通过池化窗口(也称为滤波器)在特征图上滑动,并在每个窗口内选取最大值作为该窗口的输出,从而形成一个新的、尺寸较小的特征图。 1. 池化窗口(Pooling Window) 池化窗口是一个固定大小的矩形区域,通常用kernel_size参数指定。例如,kernel_size=2表示一个2x2的池化窗口。池化窗口在特征图上滑动,滑动的步幅用stride参数指定。例如,stride=2表示池化窗口每次滑动2个单位。 2. 操作过程 假设我们有一个输入特征图,每个池化窗口覆盖特征图的一部分,最大池化的具体操作步骤如下:
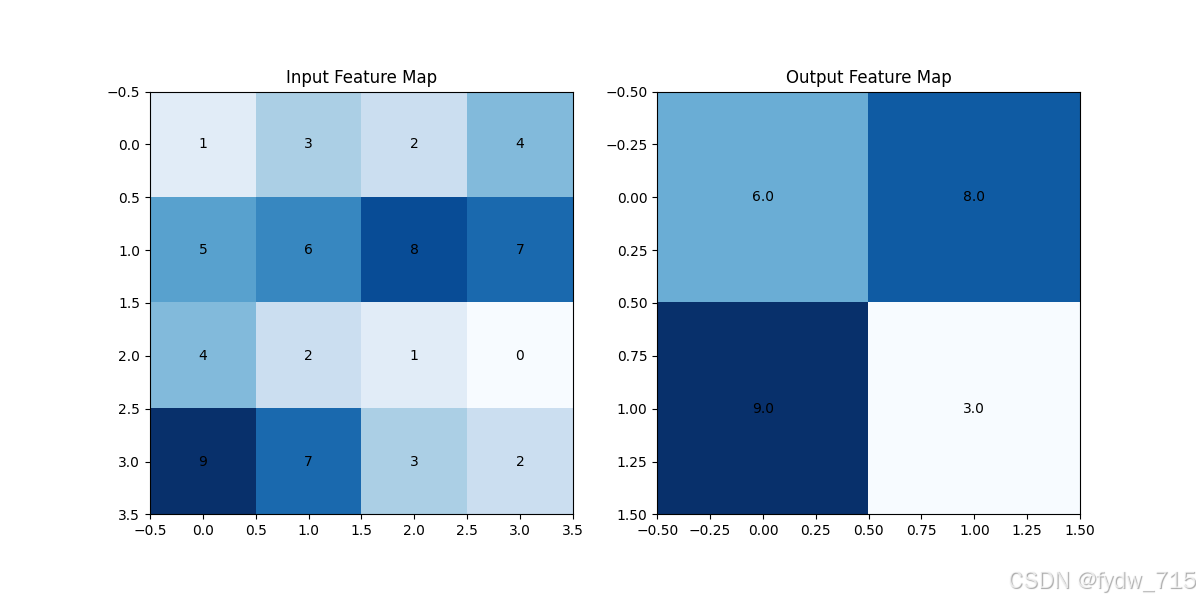
3. 示例 假设我们有一个4x4的特征图,池化窗口大小为2x2,步幅为2。具体操作如下: 输入特征图:
池化过程: 第一个窗口覆盖位置(左上角2x2):
最大值为6。第二个窗口覆盖位置(右上角2x2):
最大值为8。第三个窗口覆盖位置(左下角2x2):
最大值为9。第四个窗口覆盖位置(右下角2x2):
最大值为3。 输出特征图:
4. 代码实现 以下是使用PyTorch实现上述最大池化操作的代码示例:
输出结果为:
2.2 平均池化(Average Pooling)平均池化计算池化窗口内的平均值作为输出。它能够平滑特征图,通常用于减少噪声。
输出结果为:
3. 全局池化(Global Pooling)全局池化是一种特殊的池化操作,它将整个特征图缩小为一个单独的值。全局池化通常用于卷积神经网络的最后一个池化层,目的是将特征图的空间维度完全去除,从而得到一个固定大小的输出。这对于连接全连接层(Fully Connected Layer)或进行分类任务非常有用。 3.1 全局平均池化(Global Average Pooling)全局平均池化计算整个特征图的平均值。
输出结果为:
3.2 全局最大池化(Global Max Pooling)全局最大池化计算整个特征图的最大值。
输出结果为:
3.3 全局池化的应用全局池化在深度学习模型中有许多应用,特别是在卷积神经网络(CNN)中。以下是一些常见的应用场景: 简化模型结构:全局池化可以将特征图的空间维度完全去除,从而简化模型结构。这使得模型在处理不同尺寸的输入时更加灵活。减少参数:全局池化可以减少全连接层的参数数量,因为它将特征图缩小为一个固定大小的输出。这有助于降低模型的复杂度和过拟合风险。提高模型的泛化能力:全局池化通过聚合整个特征图的信息,可以提高模型的泛化能力,使其在不同数据集上表现更好。 3.4 全局池化与传统池化的对比
4. 池化层和卷积层的对比池化层和卷积层在使用滑动窗口和降维方面有相似之处,但它们的功能和作用不同。 相似之处
不同之处 操作性质:
输出特征图的内容:
学习能力:
5. 计算输出特征图的大小
总结池化层在深度学习中扮演着重要角色,通过降维、特征提取和抑制噪声等功能,显著提高了模型的计算效率和鲁棒性。最大池化和平均池化是最常见的池化操作,而全局池化作为一种特殊的池化方法,在简化模型结构和提高泛化能力方面表现突出。了解池化层的工作原理和应用,对于设计和优化高效的深度学习模型至关重要。 |

您可能感兴趣的文章 :

-
解决Python调用df.to_csv()出现中文乱码的问题
Python调用df.to_csv()出现中文乱码 1 2 3 4 df = pd.DataFrame(data=total_info, columns=[公司全名, 公司简称, 公司规模, 融资阶段, 区域, 职位名称, 工作经验 -
python实现列表推导式与生成器的介绍
列表推导式和生成器是 Python 中的两个非常有用的工具。它们可以帮助你以简洁和高效的方式创建和处理数据集合。了解它们的用法不仅可以 -
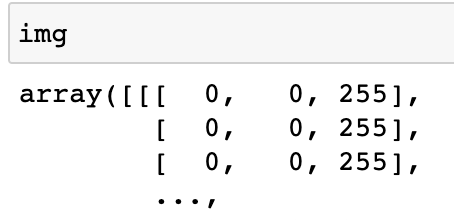
python关于图片和base64互转的三种方式
通过cv2进行转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import cv2 import base64 import numpy as np def img_to_base64(img_array): # 传入图片为RGB格式numpy矩阵, -
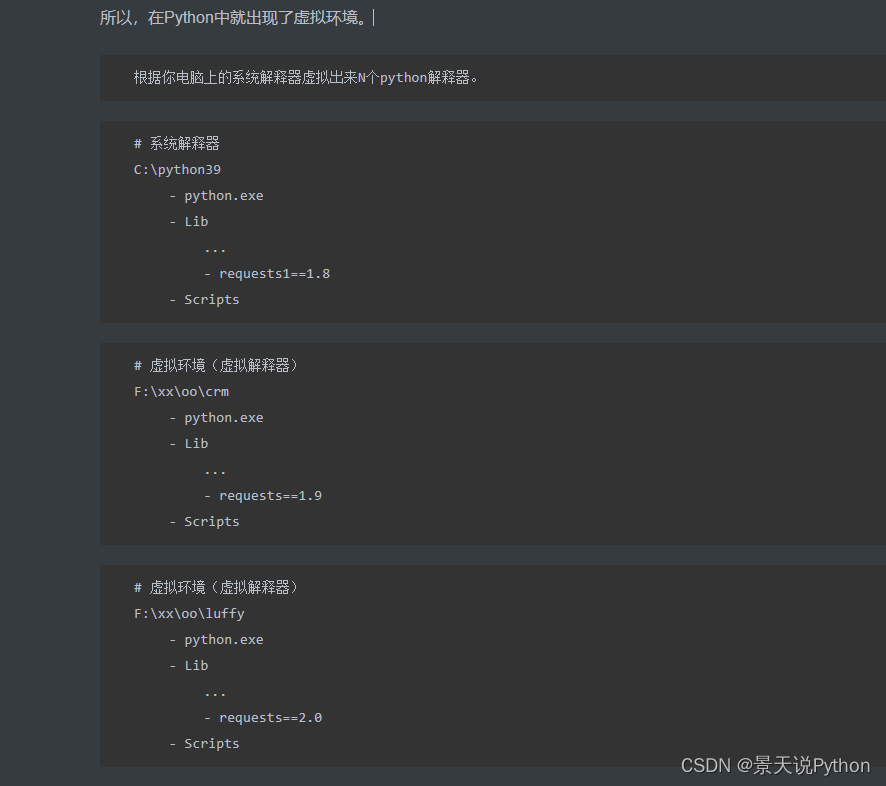
Python虚拟环境virtualenv安装的详细教程保姆级(Wi
虚拟环境安装 工作中我们经常会根据不同的项目切换不同的python环境,如果仅仅是在本地就安装一个python环境,项目移植也要重新配置环境 -
Python使用切片移动元素位置的代码
一.基本介绍 1.切片基础 在 Python 中,切片是指从序列类型(如列表、字符串、元组等)中提取子序列的过程。切片的基本语法如下: 1 seq -
Python使用FastApi发送Post请求的步骤
一.基本介绍 FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,它基于 Python 3.6 及以上版本。在 FastAPI 中发送 POST 请求,通常是 -
pytorch GPU和CPU模型相互加载方式
1 pytorch保存模型的两种方式 1.1 直接保存模型并读取 1 2 3 4 5 6 7 # 创建你的模型实例对象: model model = net() ## 保存模型 torch.save(model, model_name -
pytorch模型保存方式介绍
pytorch模型保存 保存模型主要分为两类: 保存整个模型 只保存模型参数 1.保存加载整个模型(不推荐) 保存整个网络模型,网络结构+权重




-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

